


Tolerancia a fallas y su impacto en la confiabilidad del sistema
Los equipos y sistemas que están diseñados sin tener en cuenta la tolerancia a fallas a menudo tienen una confiabilidad (más) pobre.
Esta es la razón por la que un diseño de sistema tolerante a fallas es una opción obvia para la mayoría de los ingenieros de confiabilidad y diseño, especialmente cuando se trata de equipos críticos cuyas fallas pueden comprometer la confiabilidad, disponibilidad, mantenibilidad y seguridad (RAMS) de todo el sistema. parte de.
Únase a nosotros mientras exploramos las características de los sistemas tolerantes a fallas y discutimos formas de mejorar la tolerancia a fallas a través de diseños redundantes.
¿Qué es la tolerancia a fallas?
La tolerancia a fallas representa la capacidad de cualquier sistema o equipo para mantener su funcionamiento durante la presencia de una falla.
Los sistemas y equipos con alta tolerancia a fallas, dependiendo del mecanismo de tolerancia a fallas adoptado, pueden mantener total o parcialmente su funcionamiento en caso de que ocurra una falla. Para que esto funcione en la práctica, dichos sistemas no pueden tener un solo punto de falla (SPOF).
La esencia de los diseños tolerantes a fallas
El desarrollo de un diseño tolerante a fallas requiere una consideración cuidadosa de las fallas que pueden manifestarse a lo largo del ciclo de vida del equipo, junto con sus probables causas y consecuencias.
Sin embargo, los ingenieros de diseño también deben considerar los factores de costo y recursos necesarios para lograr el nivel requerido de tolerancia, confiabilidad y confiabilidad del equipo.
A menudo se malinterpreta que un diseño tolerante a fallas debería proporcionar tolerancia completa a todo tipo de fallas. Esto no es verdad. Un buen diseño debe igualar el grado de tolerancia a la criticidad de la falla de manera que se pueda lograr la optimización general de la eficiencia de costos y recursos.
Por ejemplo, es posible que no sea rentable gastar dinero en el rediseño del producto, solo para abordar una falla que tiene una probabilidad extremadamente baja de ocurrir.
Características de los sistemas tolerantes a fallas
Para crear un sistema tolerante a fallas, se requieren esfuerzos en cada etapa del ciclo de vida del equipo. Esto incluye, entre otros, la fase de especificación y diseño (incorporando controles de detección de fallas en el diseño), validación y verificación (V&V), mantenimiento y operación (utilizando piezas de repuesto aprobadas por el OEM y pautas para el mantenimiento de rutina) e incluso la etapa de eliminación. .
Cada etapa puede adoptar combinaciones de las técnicas indicadas a continuación para desarrollar nuevos diseños o mejorar los actuales para mejorar su nivel de tolerancia a fallas:
- detección y visualización de fallas
- diagnóstico y contención de fallas
- enmascaramiento y compensación de fallas
1) Detección y visualización de fallas
La detección de fallas se refiere a la capacidad del sistema / equipo para detectar y mostrar la falla. Es el aspecto fundamental de cualquier sistema tolerante a fallas . Todos los demás aspectos dependen de la efectividad del proceso de detección de fallas. Si el sistema no está diseñado para detectar su falla, o de alguna manera detecta incorrectamente una falla, el resto de aspectos también serán ineficaces.
Por ejemplo, un simple sensor de presión de aire en un sistema de monitoreo de presión de llantas de automóvil (TPMS) puede detectar el sobrellenado de aire y notificar al conductor a través del tablero del automóvil.
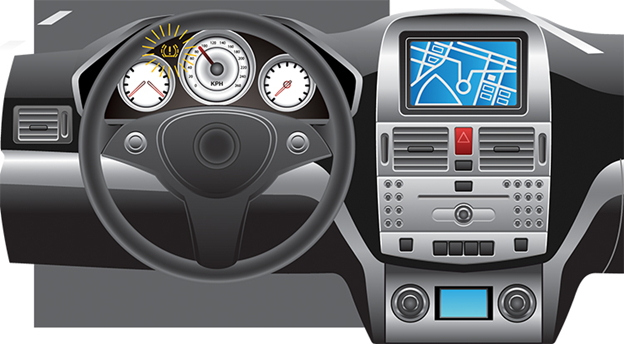
Una representación de la activación de TPMS
En este caso, la detección y visualización es el único nivel de tolerancia aceptable para este evento de falla. El cliente puede desenganchar con seguridad la manguera de aire antes de romper el neumático.
Si la detección de presión es inexacta, el conductor puede desenganchar la manguera demasiado pronto / tarde y experimentar fallas en los neumáticos durante la conducción. Dado que no existe una corrección automática de la presión de aire, el aspecto de tolerancia para esta falla se limita a la detección y visualización.
2) Diagnóstico y contención de fallas
En sistemas más sofisticados, a menudo se agregan capas adicionales en la etapa de diseño del producto. Su propósito es diagnosticar y realizar contención además de la detección y visualización. Estas capas adicionales están garantizadas debido a la criticidad del sistema o debido a varios problemas de seguridad.
Por ejemplo, un sistema de control distribuido (DCS), un sistema de control para plantas de proceso, no solo monitorea los parámetros críticos del proceso a través de un conjunto de sensores, sino que también realiza un diagnóstico para detectar la ubicación de la falla y realizar la contención necesaria.
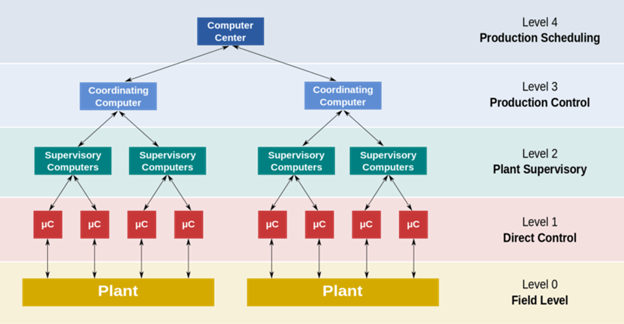
Una representación del sistema DCS
Por ejemplo, en el caso de sobrepresión de productos petrolíferos en un recipiente, el sistema se activa mediante sensores de presión relevantes. Abre la válvula de presión de seguridad y expulsa los vapores en la chimenea de antorcha.
En este ejemplo, la contención se lleva a cabo desviando el vapor inflamable a alta presión hacia la chimenea de escape, protegiendo el sistema de incendios o explosiones.
3) Enmascaramiento y compensación de fallas
Otro enfoque eficaz para la tolerancia a fallas es enmascarar el estado de falla. Es muy efectivo para equipos que se pueden monitorear y controlar a través de la tecnología de Internet de las cosas (IoT).
Con dicho equipo, uno de los desafíos más importantes se presenta en forma de amenazas a la seguridad cibernética. Estos tipos de amenazas pueden intentar inducir la falla alterando el estado del equipo mediante la inyección de datos falsos del equipo en el servidor.
Con registros de estado de equipo incorrectos, el mismo sistema de control y monitoreo que originalmente se pretendía proteger puede, en cambio, causar la falla del activo. Alternativamente, se puede "engañar" para que piense que el activo está en buenas condiciones cuando en realidad no lo está, dejando que el deterioro conduzca a una falla sin activar ninguna alerta.
Al incorporar el enmascaramiento de fallas, el sistema está diseñado de manera que pueda reconocer y enmascarar esos valores incorrectos.
Por ejemplo, en las redes eléctricas, los interruptores automáticos a menudo se controlan y monitorean a través del control de supervisión y adquisición de datos (SCADA).
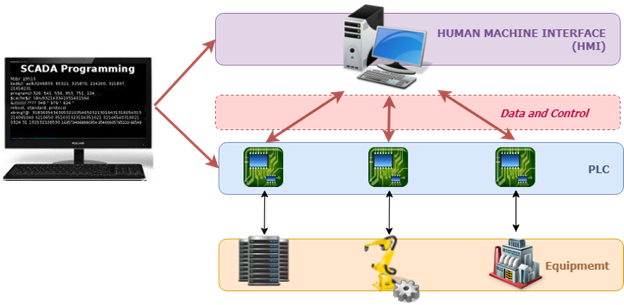
Una representación del sistema SCADA
Tal sistema monitorea de cerca los parámetros de voltaje y frecuencia del equipo eléctrico y hace que se cierren o se abran para mantener la estabilidad de la red eléctrica.
Un ataque cibernético entrante podría alterar los límites de voltaje y frecuencia en el equipo. ¿Consecuencias? El sistema podría provocar un corte de energía en lugar de prevenirlo.
El enmascaramiento de fallas a menudo se lleva a cabo a través de algoritmos que detectan flujos de datos anómalos e inyectan datos falsos con el propósito de enmascarar los datos que representan el estado defectuoso del equipo. Esto evita que los actores de datos erróneos propaguen la falla y agraven aún más la confiabilidad de la red.
Mejora de la tolerancia a fallas mediante diseños redundantes
Una de las acciones simples que se pueden tomar para aumentar la tolerancia a fallas es incorporar redundancias en el diseño. La redundancia simplemente significa la presencia de un sistema o solución alternativo que puede asumir la función deseada en caso de que falle el sistema principal.
Si bien la redundancia mejora la tolerancia a fallas, agregar sistemas al azar no debe ser el objetivo, ya que la cantidad de costo requerido para agregar cualquier sistema nuevo puede superar significativamente el beneficio de confiabilidad alcanzable.
Desde la perspectiva del equipo físico, se pueden clasificar en términos generales como activos o despidos pasivos .
Redundancias activas
Se pueden establecer redundancias activas cuando se operan simultáneamente varios equipos. En esta configuración, cada pieza de equipo contribuye con su parte para lograr la función deseada mientras siguen actuando como redundancia entre sí.
Una redundancia activa simplista es el funcionamiento en paralelo de dos bombas a la mitad de sus capacidades nominales. Ambas bombas operan conjuntamente para lograr la presión de descarga deseada. Si una bomba falla, la otra bomba aún se puede impulsar a su capacidad nominal para alcanzar la presión de descarga deseada por sí sola. Para lograr la economía de diseño, los ingenieros de confiabilidad han ideado varias otras formas complicadas de lograr redundancias activas, como las redundancias K de N y la degradación elegante.
En K de N despidos , un determinado subconjunto de equipos siempre está en funcionamiento. Esto aumenta la confiabilidad del sistema ya que algunos de los equipos todavía están en espera activa y pueden unirse a la operación en caso de fallas de algunos equipos. Esto garantiza una mayor confiabilidad en comparación con el simple funcionamiento en paralelo de dos bombas, ya que habrá un mayor número de bombas pequeñas en funcionamiento.
Agradable degradación es una alternativa a la adición de costosos sistemas idénticos y paralelos. Asegura que las características o la funcionalidad del equipo en general se degraden proporcionalmente al número de componentes defectuosos. Para lograr tal degradación escalable, se debe realizar un examen de todas las fallas posibles dentro de todos los componentes. Su impacto en el rendimiento general del sistema debe analizarse y documentarse.
Dichas técnicas brindan tolerancia a fallas parciales y permiten que el sistema continúe funcionando a una capacidad degradada.
Redundancias pasivas
La redundancia pasiva es la redundancia en espera donde está presente el equipo alternativo, pero solo puede asumir la función prevista en caso de falla del equipo primario.
Podemos diferenciar dos tipos de redundancias pasivas:
- funcionamiento de redundancias pasivas
- redundancias pasivas no operativas
Funcionamiento de redundancias pasivas son aquellos en los que el equipo alternativo está presente como repuesto en caliente. El equipo de reserva está caliente porque podría estar funcionando sin carga. En algunos casos, puede estar cumpliendo una función que está fuera de la definición de función del equipo primario.
En caso de falla del equipo primario, el equipo de reserva operativo puede pasar automáticamente a realizar la función de equipo primario.
Un ejemplo de funcionamiento de redundancias pasivas puede ser un alternador secundario que funciona en condiciones sin carga y cumple con todas las demás condiciones de conexión en paralelo, como el mismo voltaje terminal, frecuencia y secuencia de fase. En caso de falla del alternador primario, el alternador secundario puede sincronizarse automáticamente con el sistema y hacerse cargo de la carga.
En el caso de despidos pasivos no operativos , el equipo de reserva está apagado. En caso de falla del equipo primario, el equipo de reserva se puede configurar automática o manualmente a las condiciones de operación y asumir la funcionalidad del equipo primario.
Un buen ejemplo de redundancia pasiva no operativa es una bomba de agua municipal de reserva que se puede poner en marcha y operar manualmente para suministrar agua a los residentes si la bomba de agua principal no funciona correctamente. Dado que la restauración de la operación no es crítica, un operador puede ir y arrancar la bomba (y sincronizarla con el sistema más tarde, según sea necesario).
Técnicas de confiabilidad para analizar la tolerancia a fallas
La tolerancia a fallas es parte de los esfuerzos de ingeniería de confiabilidad y requiere un examen cuidadoso de todas las fallas posibles que pueden ocurrir dentro del equipo. El análisis del efecto del modo de falla (FMEA) y el análisis del árbol de fallas (FTA) son dos técnicas bien conocidas para analizar el diseño del sistema desde enfoques ascendentes y descendentes, respectivamente.
Para comprender mejor la tolerancia, se deben analizar e investigar la secuencia de fallas y las dependencias. Una técnica particularmente útil para analizar las dependencias y la secuencia es el modelo de Markov, donde la probabilidad de cualquier evento de falla dependería del estado del evento anterior.
De manera similar, otra técnica poderosa son las simulaciones de Monte Carlo que se pueden usar para modelar el impacto de las incertidumbres de cualquier evento de falla en el rendimiento del sistema.
Operaciones de mantenimiento y tolerancia a fallos
¿Los sistemas tolerantes a fallas necesitan menos mantenimiento? Bueno, sí y no.
Debido a las redundancias y otras características que discutimos anteriormente, tales sistemas generalmente pueden asumir más fallas antes de que su funcionalidad se vea comprometida. Sin embargo, si no se abordan los problemas, la acumulación de fallas eventualmente conducirá a una falla del sistema o del equipo. Por lo tanto, los equipos de mantenimiento deben usar un sistema CMMS para asegurarse de que las acciones de mantenimiento correctivas se tomen a su debido tiempo.
En cierto sentido, la tolerancia a fallas les da a los equipos de mantenimiento y soporte más espacio para respirar. Todavía necesitan resolver el problema, pero tal vez no de inmediato.
Si bien los diseños tolerantes a fallas tienen sus desafíos en términos de aumento de costos y complejidad, lo compensan en forma de confiabilidad mejorada del equipo.
Mantenimiento y reparación de equipos
- COVID 19 y Cloud; COVID 19 y su impacto en las empresas
- Los mejores en mantenimiento y confiabilidad
- Mantenimiento y confiabilidad:lo suficientemente bueno nunca es
- Los detalles importan en el mantenimiento y la confiabilidad
- Proveedores de mantenimiento y confiabilidad:Atención al comprador
- La fabricación flexible y la fiabilidad pueden coexistir
- Aplicación de la entropía al mantenimiento y la confiabilidad
- UT cambia el nombre del programa a Centro de confiabilidad y mantenimiento
- Una perspectiva de los kayakistas sobre la fiabilidad y la seguridad
- ISA publica un libro sobre seguridad y confiabilidad del sistema de control
- Consejos para mantener un sistema séptico exitoso y bien mantenido