


Mejores resultados comerciales al poner en funcionamiento la inteligencia artificial a escala
La inteligencia artificial (IA) está impulsando una nueva normalidad para las empresas en todas las industrias. Los minoristas pueden, por ejemplo, usar IA para predecir pedidos de compra en datos de inventario históricos para impulsar decisiones inteligentes de reabastecimiento. Los equipos de atención al cliente pueden usar IA para responder automáticamente y enrutar tickets de atención al cliente de alta prioridad a los equipos correctos. Hay un mundo de posibilidades en las que puede usar la IA, y específicamente el ML, para generar resultados comerciales prácticos.
Según Deloitte Insights, el 83 % de los primeros usuarios de IA empresarial vieron un retorno de la inversión (ROI) positivo de los proyectos en producción. Estos incluyeron ejemplos como la implementación de software empresarial de terceros utilizando IA, el uso de chatbots y asistentes virtuales, y motores de recomendación para plataformas de comercio electrónico. El ochenta y tres por ciento de las empresas encuestadas planearon aumentar el gasto en IA en 2019. De las empresas que invierten en IA, el 63 % había adoptado ML.
Desarrollar una estrategia para usar pragmáticamente AI y ML para lograr objetivos comerciales es una prioridad para muchas empresas. Para muchos, el principal desafío para poner en funcionamiento ML con éxito es comprender, planificar y ejecutar la gestión de una implementación holística de ML en toda la organización.
Principales consideraciones para poner en práctica el ML
La forma "correcta" de abordar el ciclo de vida de la ciencia de datos difiere de una organización a otra. Se han realizado muchos intentos para codificar y estandarizar los procedimientos del ciclo de vida de la ciencia de datos. Sin embargo, ningún enfoque incorpora las necesidades de todas las empresas.
Adoptar una estrategia sostenible y mantenible para los datos y la ciencia de datos es un ejercicio en constante evolución distinto para cada empresa. Debido a que las necesidades, la estructura y las capacidades de cada empresa son únicas, se debe consultar a las partes interesadas de toda la empresa para crear un modelo de aprendizaje automático flexible y escalable y ejecutar una estrategia holística de ciencia de datos.
Los desafíos operativos y los cambios en la infraestructura y las prácticas de desarrollo que cada empresa debe abordar serán diferentes.
Es fundamental que su organización tenga en cuenta su cultura, sus sistemas y sus necesidades al definir y desarrollar el ciclo de vida de la ciencia de datos. Tener un marco base para presentar entre equipos ayuda a desarrollar una base común para la comunicación mientras continúa desarrollando y evolucionando su operacionalización de ML.
Analicemos un marco estándar que puede ayudar a su organización a comenzar su viaje de aprendizaje automático.
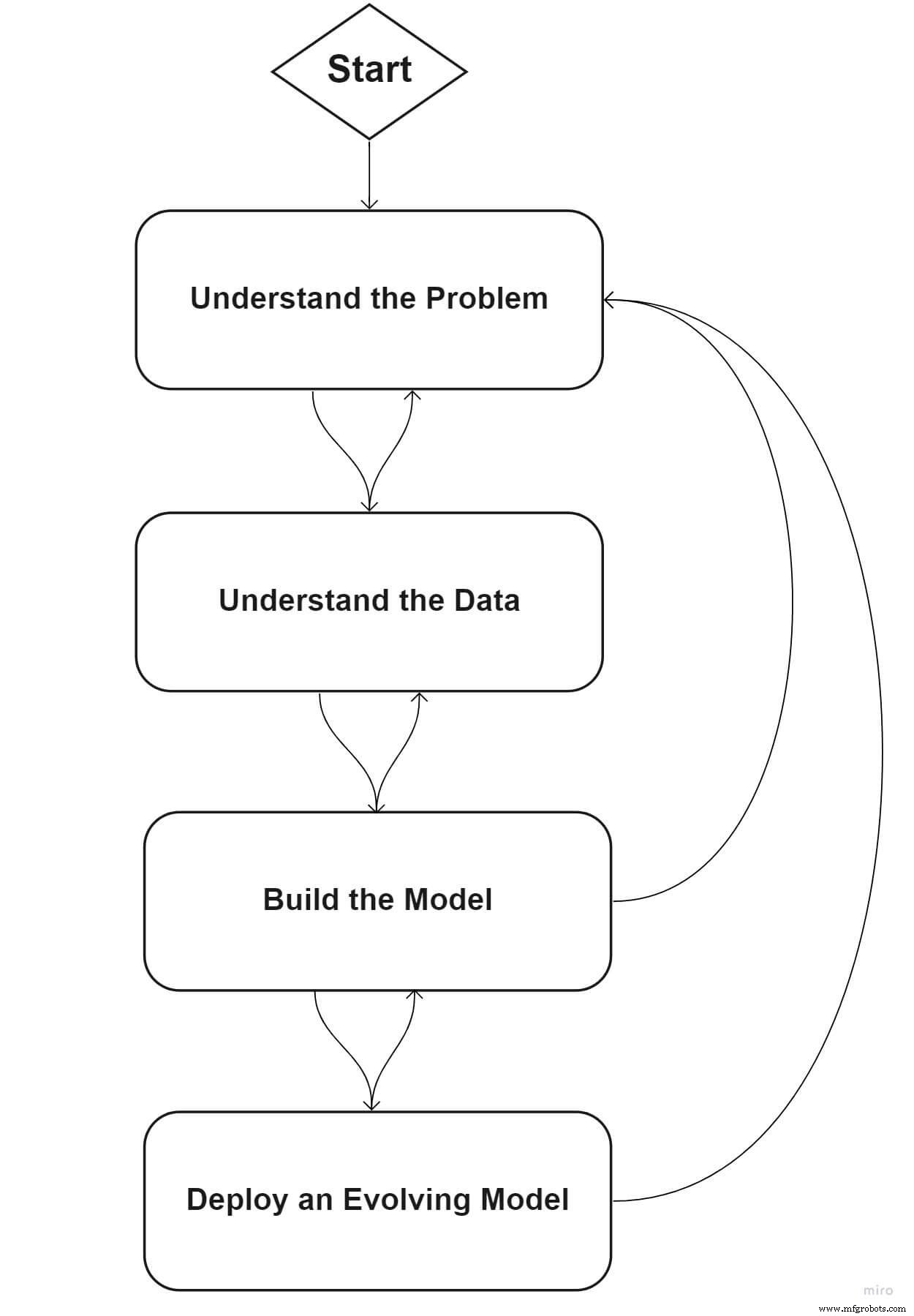
Fase uno:Define tu problema
En el centro de cualquier iniciativa de ML hay dos preguntas:
1. ¿Qué problema estás tratando de resolver?
2. ¿Por qué cree que ML y una mejor comprensión de sus datos pueden ayudarlo a resolver el problema en cuestión?
Las respuestas a estas preguntas dependen de cómo piense su empresa sobre la estrategia y evalúe los problemas comerciales.
Durante la fase uno, las partes interesadas clave deben reunirse para definir el alcance inicial del problema y sus requisitos.
Fase dos:comprender sus datos
¿Cuál es la historia de sus datos? ¿De dónde provienen sus datos y cuántas fuentes de datos son relevantes para ayudarlo a resolver su problema comercial específico?
Durante esta fase, las empresas se centran en:
-
Mapeo de fuentes de datos relevantes y los entornos en los que viven (dichos entornos pueden estar en las instalaciones o en la nube, configurados como un almacén de datos, un lago de datos o plataformas de transmisión de datos)
-
Definir qué canalizaciones de datos existen actualmente y qué canalizaciones de datos deben construirse para la validación, limpieza y exploración de datos
-
Comprender la frecuencia con la que se actualizan los datos
-
Comprender la confiabilidad de los datos
-
Evaluación de consideraciones y requisitos de privacidad de datos
-
Habilitación de la exploración de datos a través de visualizaciones, propiedades estadísticas de datos sin procesar y transformados, etc.
Comprender sus datos no es tarea fácil. Es importante abordar esta fase de forma iterativa. A medida que descubra más acerca de sus datos, es posible que descubra problemas que afecten su capacidad para resolver el problema, lo que puede requerir que redefina o vuelva a analizar el problema desde la fase uno.
Fase tres:construir el modelo ML
Una vez que tenga los datos listos, es hora de que sus científicos de datos creen un modelo de ML. Los pasos comunes para construir un modelo de ML robusto incluyen:
-
Características de extracción e ingeniería (incluye agrupamiento, blanqueamiento de datos y aplicación de transformaciones estadísticas)
-
Selección de funciones
-
Entrenamiento del modelo (incluye dividir los datos en cualquier cantidad de conjuntos de datos de entrenamiento, validación cruzada y validación)
-
Ajuste de hiperparámetros
-
Evaluación del modelo
-
Validación de la significancia estadística
El desarrollo de un modelo requiere comentarios continuos de las partes interesadas del negocio. Por ejemplo, el problema comercial puede requerir una afinidad con la sensibilidad frente a la especificidad. De manera similar, puede intercambiar un rendimiento predictivo leve (p. ej., puntuación F1) por el rendimiento operativo del modelo (p. ej., predicciones más rápidas) o la explicabilidad del modelo.
El objetivo del científico de datos es construir un modelo que use datos para contar una historia clara relacionada con el problema comercial. A medida que el problema evoluciona y los requisitos cambian, el enfoque del modelado también debe evolucionar para adaptarse al contexto actual.
Fase cuatro:implementar un modelo en evolución
Construir el modelo inicial es solo el comienzo del viaje de ML. La implementación de un modelo en evolución es un paso crucial para la creación de valor a largo plazo para la organización.
La implementación de un modelo en evolución requiere:
-
Sirviendo al modelo (haciendo que el modelo sea altamente disponible y escalable horizontalmente)
-
Gestión de versiones de modelos (incluidas reversiones e implementaciones canary/challenger)
-
Volver a entrenar el modelo (modificar o construir un nuevo modelo a medida que ingresan nuevos datos al sistema)
-
Seguimiento del modelo (seguimiento de métricas tanto operativas como de experiencia de usuario en tiempos de servicio y formación)
Supervisar los datos y la desviación del modelo, requerir la especialización de un modelo para casos de uso específicos dentro de la organización y mantener las canalizaciones de datos (entre otros elementos de mantenimiento) son fundamentales para el éxito continuo de un modelo.
Los requisitos de toda la empresa y de toda la industria pueden evolucionar rápidamente y afectar las fuentes de datos y las entradas. Por ejemplo, la gobernanza y el cumplimiento a escala son consideraciones que abarcan todo el ciclo de vida de la ciencia de datos.
El cumplimiento de las normativas, como el Reglamento general de protección de datos (GDPR) de la Unión Europea (UE), requiere un nivel más profundo de trazabilidad en las capas de control de versiones de datos, control de versiones de modelos y entrada de modelos. Desarrollar una estrategia para responder a estos cambios y requisitos de la industria a través de los datos puede ayudar a las empresas a seguir aprovechando el aprendizaje automático para generar mejores resultados comerciales, como el crecimiento de los ingresos, la reducción de costos y la disminución del riesgo.
¿Qué sigue?
Operar ML de una manera flexible, mantenible y escalable requiere muchos pasos y consideraciones más allá del alcance de alto nivel de lo que hemos descrito en este blog. El diablo está en los detalles.
En nuestro próximo blog, profundizaremos en las consideraciones técnicas, los desafíos que pueden surgir de una implementación ad-hoc de un sistema ML a gran escala y cómo UiPath ayuda a abordar los desafíos comunes para los clientes empresariales.
Sistema de control de automatización
- Bosch agrega inteligencia artificial a la industria 4.0
- ¿La inteligencia artificial es ficción o moda?
- ¿Tendrá la inteligencia artificial un impacto en IoT tarde o temprano?
- Por qué Internet de las cosas necesita inteligencia artificial
- Cómo crear una estrategia de inteligencia empresarial exitosa
- Evolución de la Automatización de Pruebas con Inteligencia Artificial
- ¿Qué es la inteligencia empresarial? ¿Y por qué necesito saberlo?
- AIoT industrial:combinación de inteligencia artificial e IoT para la Industria 4.0
- Robots de inteligencia artificial
- Ventajas y desventajas de la inteligencia artificial
- Big Data vs Inteligencia Artificial