


Cómo la computación analógica en memoria puede resolver los desafíos de potencia de la inferencia de IA de borde
El aprendizaje automático y el aprendizaje profundo ya son partes integrales de nuestras vidas. Las aplicaciones de inteligencia artificial (IA) a través del procesamiento del lenguaje natural (NLP), la clasificación de imágenes y la detección de objetos están profundamente integradas en muchos de los dispositivos que utilizamos. La mayoría de las aplicaciones de inteligencia artificial se sirven a través de motores basados en la nube que funcionan bien para lo que se utilizan, como obtener predicciones de palabras al escribir una respuesta por correo electrónico en Gmail.
Por mucho que disfrutemos de los beneficios de estas aplicaciones de inteligencia artificial, este enfoque presenta desafíos de privacidad, disipación de energía, latencia y costos. Estos desafíos pueden resolverse si existe un motor de procesamiento local capaz de realizar cálculos (inferencias) parciales o totales en el origen de los datos en sí. Esto ha sido difícil de hacer con las implementaciones tradicionales de redes neuronales digitales, en las que la memoria se convierte en un cuello de botella que consume mucha energía. El problema se puede resolver con memoria multinivel y el uso de un método de cálculo analógico en memoria que, en conjunto, permiten que los motores de procesamiento cumplan con los requisitos de potencia mucho más bajos, milivatios (mW) a microvatios (uW) para realizar inferencias de IA en el borde de la red.
Desafíos de la informática en la nube
Cuando las aplicaciones de IA se sirven a través de motores basados en la nube, el usuario debe cargar algunos datos (de forma voluntaria o involuntaria) en las nubes donde los motores de cálculo procesan los datos, proporcionan predicciones y envían las predicciones al usuario para que las consuma.

Figura 1:Transferencia de datos de Edge a Cloud. (Fuente:Tecnología Microchip)
Los desafíos asociados con este proceso se describen a continuación:
- Problemas de privacidad y seguridad: Con dispositivos siempre activos y siempre alerta, existe la preocupación de que los datos personales (y / o la información confidencial) se utilicen indebidamente, ya sea durante las cargas o durante su vida útil en los centros de datos.
- Disipación de energía innecesaria: Si cada bit de datos se va a la nube, está consumiendo energía del hardware, radios, transmisión y, potencialmente, en cálculos no deseados en la nube.
- Latencia para inferencias de lotes pequeños: A veces, puede llevar un segundo o más obtener una respuesta de un sistema basado en la nube si los datos se originan en el borde. Para los sentidos humanos, algo más de 100 milisegundos (ms) de latencia es perceptible y puede resultar molesto.
- La economía de datos debe tener sentido: Los sensores están en todas partes y son muy asequibles; sin embargo, producen una gran cantidad de datos. No es económico cargar todos los datos en la nube y procesarlos.
Para resolver estos desafíos utilizando un motor de procesamiento local, el modelo de red neuronal que realizará las operaciones de inferencia primero debe entrenarse con un conjunto de datos dado para el caso de uso deseado. Generalmente, esto requiere altos recursos informáticos (y de memoria) y operaciones aritméticas de punto flotante. Como resultado, la parte de entrenamiento de una solución de aprendizaje automático aún debe realizarse en nubes públicas o privadas (o una GPU local, CPU, granja de FPGA) con un conjunto de datos para generar un modelo de red neuronal óptimo. Una vez que el modelo de red neuronal está listo, el modelo se puede optimizar aún más para un hardware local con un motor informático pequeño porque el modelo de red neuronal no necesita propagación hacia atrás para la operación de inferencia. Un motor de inferencia generalmente necesita un mar de motores de acumulación múltiple (MAC), seguido de una capa de activación como unidad lineal rectificada (ReLU), sigmoide o tanh, según la complejidad del modelo de red neuronal y una capa de agrupación entre capas.
La mayoría de los modelos de redes neuronales requieren una gran cantidad de operaciones MAC. Por ejemplo, incluso un modelo "1.0 MobileNet-224" comparativamente pequeño tiene 4,2 millones de parámetros (pesos) y requiere 569 millones de operaciones MAC para realizar una inferencia. Dado que la mayoría de los modelos están dominados por operaciones MAC, el enfoque aquí estará en esta parte del cálculo del aprendizaje automático y la exploración de la oportunidad de crear una mejor solución. A continuación, en la Figura 2, se ilustra una red de dos capas simple y completamente conectada.
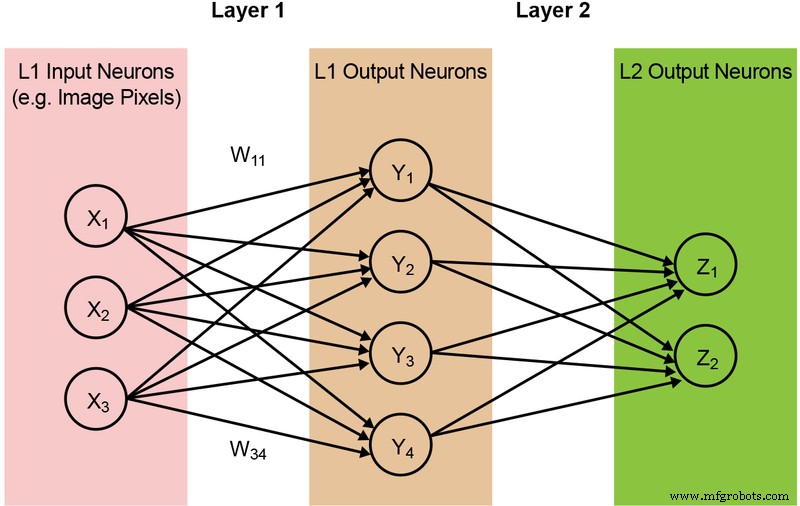
Figura 2:Red neuronal completamente conectada con dos capas. (Fuente:Tecnología Microchip)
Las neuronas de entrada (datos) se procesan con la primera capa de pesos. Las neuronas de salida de las primeras capas se procesan luego con la segunda capa de pesos y proporcionan predicciones (digamos, si el modelo pudo encontrar una cara de gato en una imagen determinada). Estos modelos de redes neuronales utilizan el "producto punto" para el cálculo de cada neurona en cada capa, ilustrado por la siguiente ecuación (omitiendo el término "sesgo" en la ecuación para simplificar):
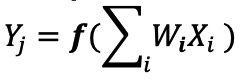
Memoria Cuello de botella en la informática digital
En una implementación de red neuronal digital, los pesos y los datos de entrada se almacenan en una DRAM / SRAM. Los pesos y los datos de entrada deben trasladarse a un motor MAC para la inferencia. Como se muestra en la Figura 3 a continuación, este enfoque da como resultado que la mayor parte de la energía se disipe al obtener los parámetros del modelo y los datos de entrada a la ALU donde se lleva a cabo la operación MAC real.
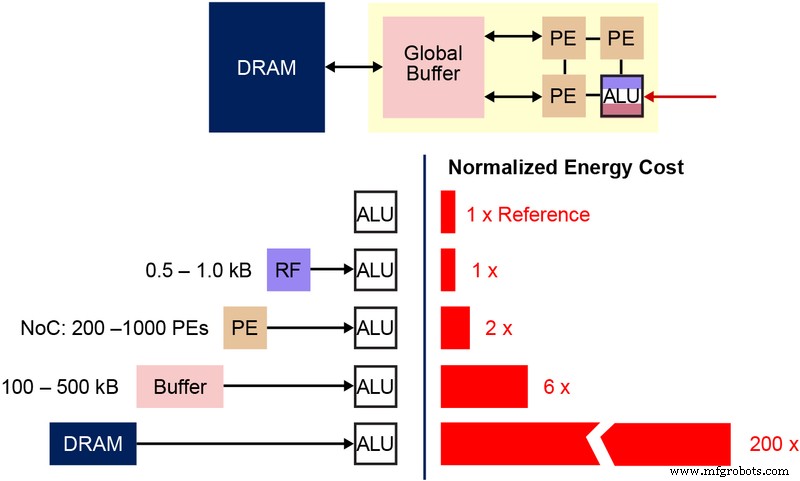
Figura 3:Cuello de botella de memoria en la computación de aprendizaje automático. (Fuente:Y.-H. Chen, J. Emer y V. Sze, “Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks”, en ISCA, 2016.)
Para poner las cosas en una perspectiva energética:una operación MAC típica que utiliza puertas lógicas digitales consume ~ 250 femtojulios (fJ, o 10 −15 joules) de energía, pero la energía disipada durante la transferencia de datos es más de dos órdenes de magnitud que el cálculo en sí y se encuentra en el rango de 50 picojoules (pJ, o 10 −12 julios) a 100pJ. Para ser justos, hay muchas técnicas de diseño disponibles para minimizar la transferencia de datos desde la memoria a la ALU; sin embargo, todo el esquema digital todavía está limitado por la arquitectura de Von Neumann, por lo que presenta una gran oportunidad para reducir el desperdicio de energía. ¿Qué pasa si la energía para realizar una operación MAC se puede reducir de ~ 100 pJ a una fracción de pJ?
Eliminación de cuellos de botella en la memoria con computación en memoria analógica
La realización de operaciones de inferencia en el borde se vuelve eficiente en términos de energía cuando la propia memoria se puede usar para reducir la energía requerida para el cálculo. El uso de un método de cálculo en memoria minimiza la cantidad de datos que se deben mover. Esto, a su vez, elimina la energía desperdiciada durante la transferencia de datos. La disipación de energía se minimiza aún más mediante el uso de celdas flash que pueden funcionar con una disipación de energía activa ultrabaja y casi sin disipación de energía durante el modo de espera.
Un ejemplo de este enfoque es la tecnología memBrain ™ de Silicon Storage Technology (SST), una empresa de Microchip Technology. Basado en SuperFlash ® de SST tecnología de memoria, la solución incluye una arquitectura informática en memoria que permite realizar cálculos donde se almacenan los pesos del modelo de inferencia. Esto elimina el cuello de botella de la memoria en el cálculo MAC, ya que no hay movimiento de datos para los pesos; solo los datos de entrada deben moverse desde un sensor de entrada como una cámara o un micrófono a la matriz de memoria.
Este concepto de memoria se basa en dos fundamentos:(a) la respuesta de corriente eléctrica analógica de un transistor se basa en su voltaje umbral (Vt) y los datos de entrada, y (b) la ley de corriente de Kirchhoff, que establece que la suma algebraica de corrientes en una red de conductores que se encuentran en un punto es cero.
También es importante comprender la celda de bits fundamental de la memoria no volátil (NVM) que se utiliza en esta arquitectura de memoria multinivel. El siguiente diagrama (Figura 4) es una sección transversal de dos ESF3 (Embedded SuperFlash 3 rd generación) bitcells con Erase Gate (EG) y Source Line (SL) compartidas. Cada celda de bits tiene cinco terminales:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) y Bitline (BL). La operación de borrado en la celda de bits se realiza aplicando alto voltaje en EG. La operación de programación se realiza aplicando señales de polarización de voltaje alto / bajo en WL, CG, BL y SL. La operación de lectura se realiza aplicando señales de polarización de bajo voltaje en WL, CG, BL y SL.
Figura 4:Celda SuperFlash ESF3. (Fuente:Tecnología Microchip)
Con esta arquitectura de memoria, el usuario puede programar las celdas de bits de memoria en varios niveles de Vt mediante una operación de programación detallada. La tecnología de memoria utiliza un algoritmo inteligente para sintonizar la puerta flotante (FG) Vt de la celda de memoria para lograr cierta respuesta de corriente eléctrica a partir de un voltaje de entrada. Dependiendo del requisito de la aplicación final, las celdas se pueden programar en una región operativa lineal o subumbral.
La Figura 5 ilustra la capacidad de almacenar y leer múltiples niveles en la celda de memoria. Digamos que estamos intentando almacenar un valor entero de 2 bits en una celda de memoria. Para este escenario, necesitamos programar cada celda en una matriz de memoria con uno de los cuatro valores posibles de los valores enteros de 2 bits (00, 01, 10, 11). Las cuatro curvas a continuación son una curva IV para cada uno de los cuatro estados posibles, y la respuesta de la corriente eléctrica de la celda dependería del voltaje aplicado en CG.
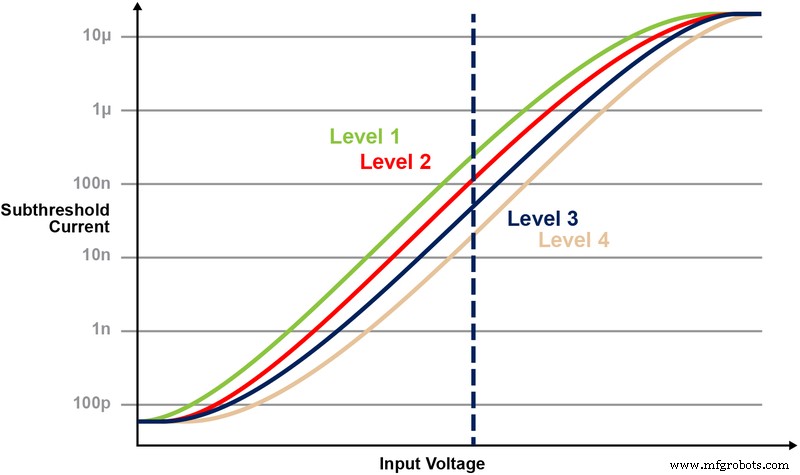
Figura 5:Programación de niveles de Vt en la celda ESF3. (Fuente:Tecnología Microchip)
Operación de acumulación y multiplicación con computación en memoria
Cada celda de ESF3 se puede modelar como conductancia variable (g m ). La conductancia de una celda ESF3 depende de la puerta flotante Vt de la celda programada. Un peso de un modelo entrenado se programa como puerta flotante Vt de la celda de memoria, por lo tanto, g m de la celda representa un peso del modelo entrenado. Cuando se aplica un voltaje de entrada (Vin) en la celda ESF3, la corriente de salida (Iout) vendría dada por la ecuación Iout =g m * Vin, que es la operación de multiplicación entre el voltaje de entrada y el peso almacenado en la celda ESF3.
La Figura 6 a continuación ilustra el concepto de multiplicar-acumular en una configuración de matriz pequeña (matriz de 2 × 2) en la que la operación de acumulación se realiza agregando corrientes de salida (de las celdas (de la operación de multiplicación) conectadas a la misma columna (por ejemplo, I1 =I11 + I21) Dependiendo de la aplicación, la función de activación puede realizarse dentro del bloque ADC o puede realizarse con una implementación digital fuera del bloque de memoria.
haz clic para ampliar la imagen
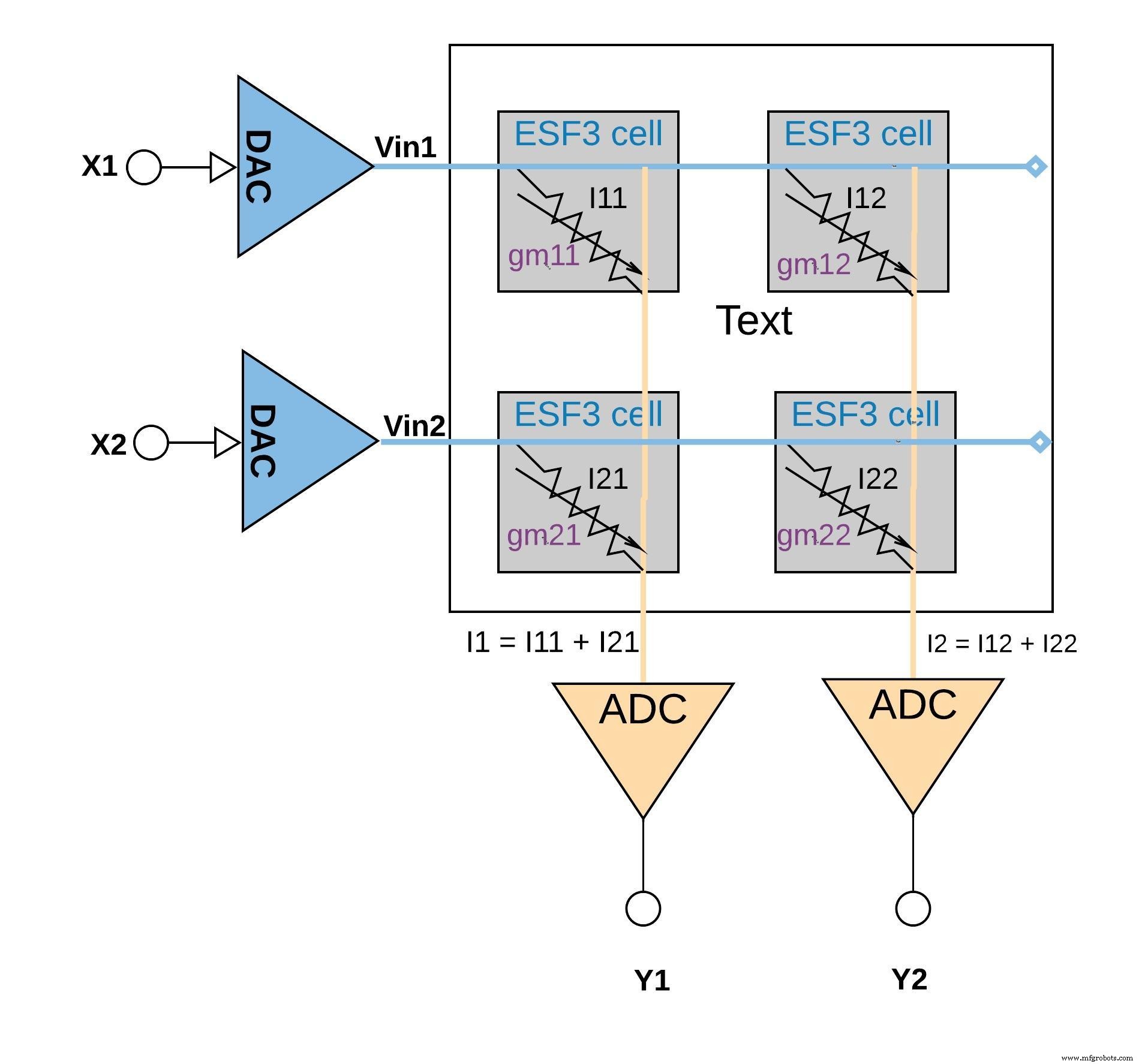
Figura 6:operación de acumulación y multiplicación con matriz ESF3 (2 × 2). (Fuente:Tecnología Microchip)
Para ilustrar mejor el concepto a un nivel superior; los pesos individuales de un modelo entrenado se programan como puerta flotante Vt de la celda de memoria, por lo que todos los pesos de cada capa del modelo entrenado (digamos una capa completamente conectada) se pueden programar en una matriz de memoria que físicamente parece una matriz de peso , como se ilustra en la Figura 7.
haz clic para ampliar la imagen
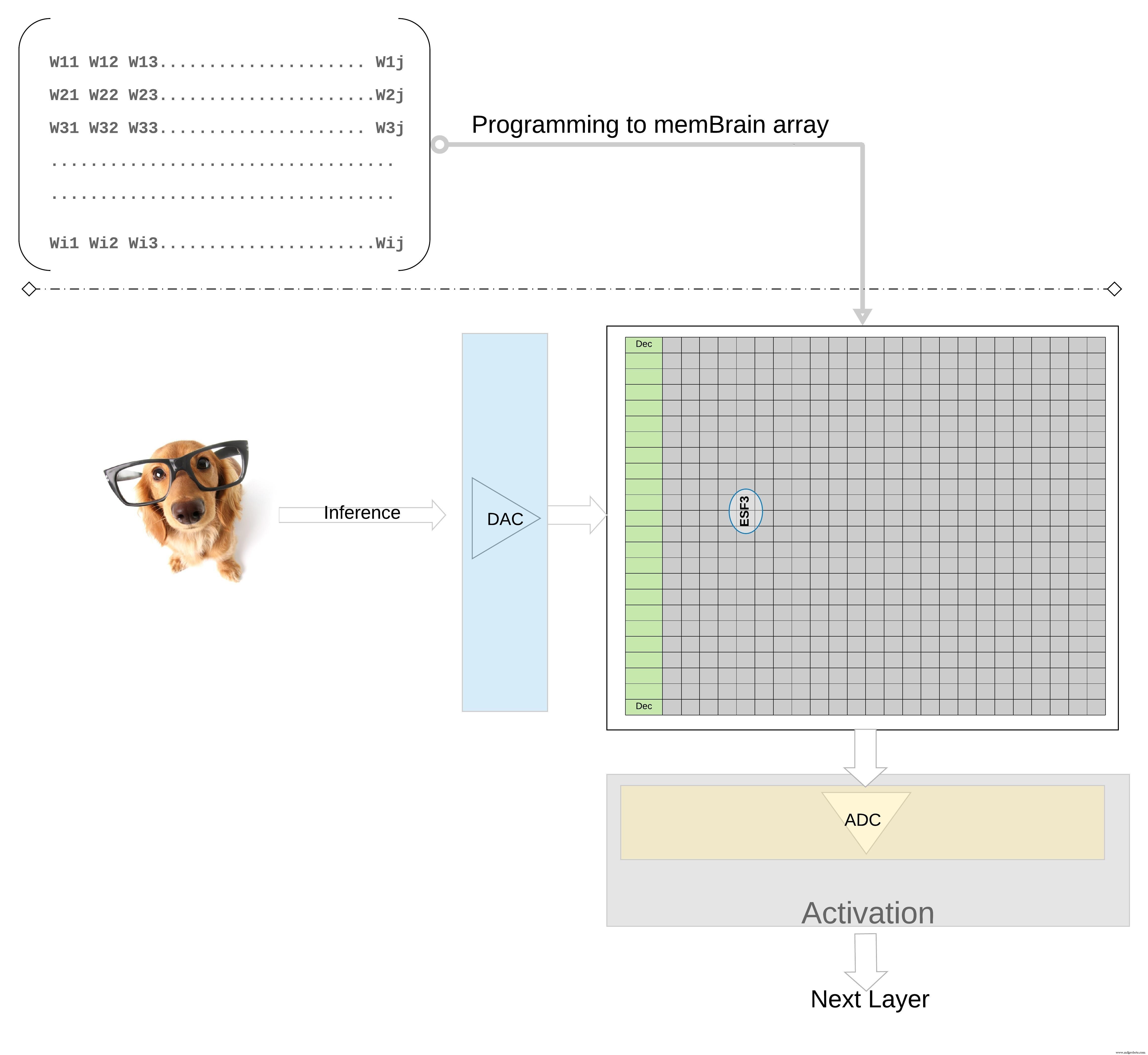
Figura 7:Matriz de memoria de matriz de peso para inferencia. (Fuente:Tecnología Microchip)
Para una operación de inferencia, una entrada digital, digamos píxeles de imagen, primero se convierte en una señal analógica usando un convertidor de digital a analógico (DAC) y se aplica a la matriz de memoria. Luego, la matriz realiza miles de operaciones MAC en paralelo para el vector de entrada dado y produce una salida que puede ir a la etapa de activación de las neuronas respectivas, que luego se pueden convertir nuevamente en señales digitales usando un convertidor de analógico a digital (ADC). Luego, las señales digitales se procesan para agruparlas antes de pasar a la siguiente capa.
Este tipo de arquitectura de memoria es muy modular y flexible. Se pueden unir muchos mosaicos de MemBrain para construir una variedad de modelos grandes con una combinación de matrices de peso y neuronas, como se ilustra en la Figura 8. En este ejemplo, una configuración de mosaico de 3 × 4 se une con un tejido analógico y digital entre los mosaicos, y los datos se pueden mover de un mosaico a otro a través de un bus compartido.
haz clic para ampliar la imagen
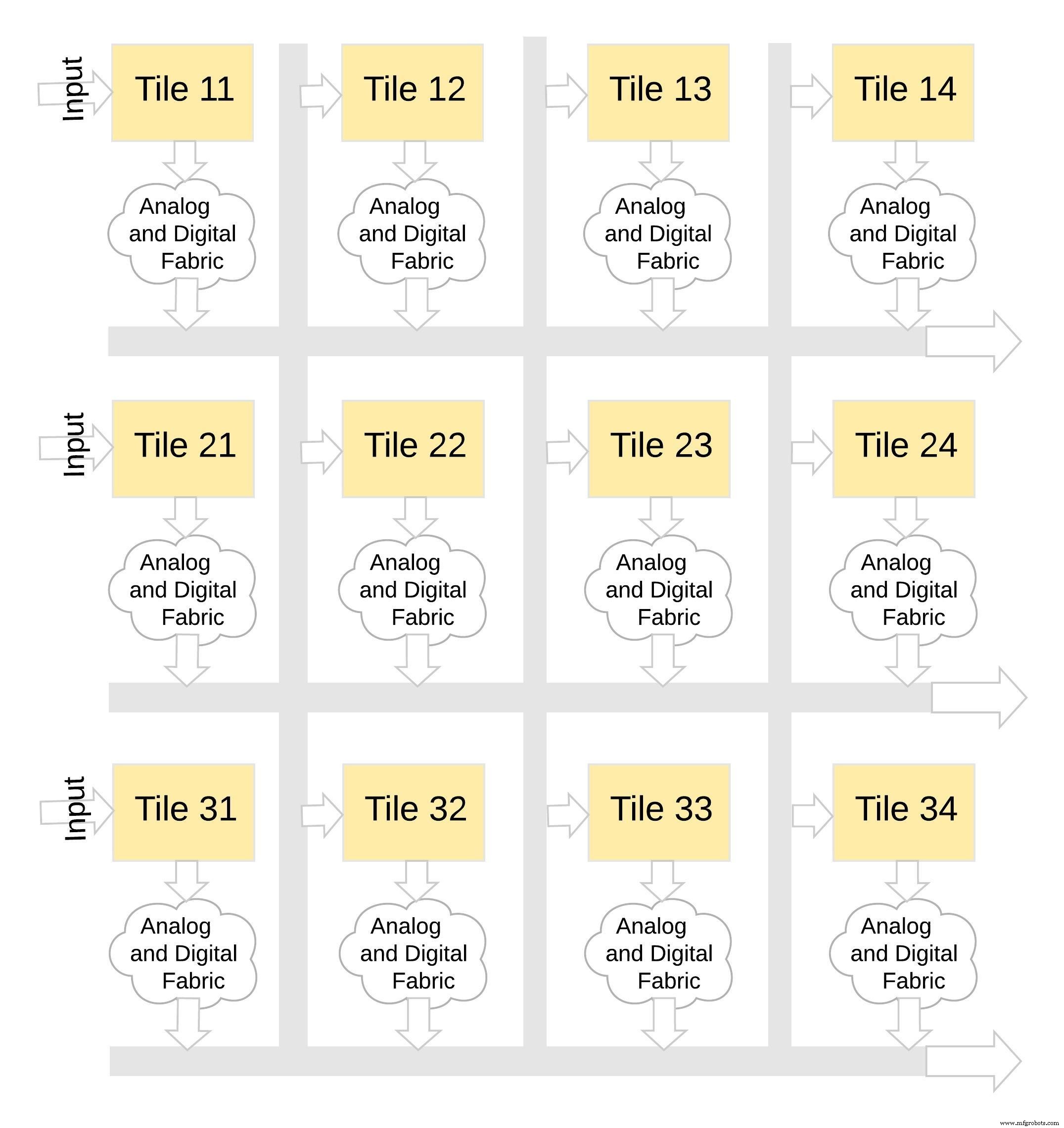
Figura 8:memBrain ™ es modular. (Fuente:Tecnología Microchip)
Hasta ahora hemos discutido principalmente la implementación de silicio de esta arquitectura. La disponibilidad de un kit de desarrollo de software (SDK) (Figura 9) ayuda con la implementación de la solución. Además del silicio, el SDK facilita la implementación del motor de inferencia.
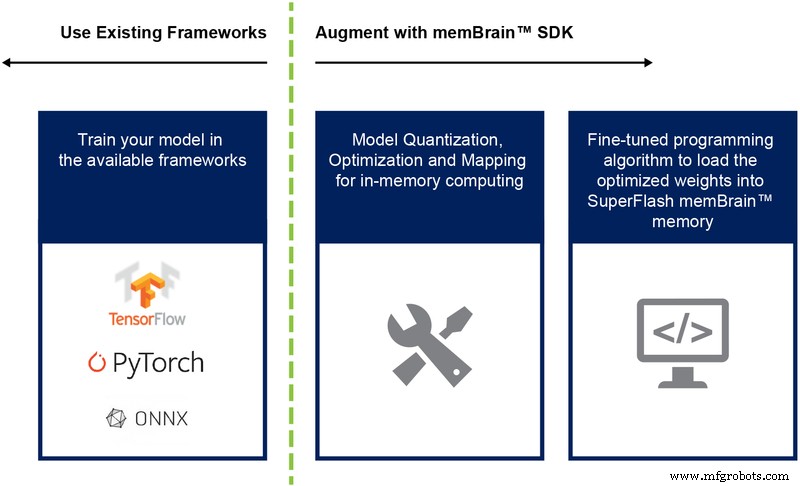
Figura 9:Flujo del SDK de memBrain ™. (Fuente:Tecnología Microchip)
El flujo del SDK es independiente del marco de entrenamiento. El usuario puede crear un modelo de red neuronal en cualquiera de los marcos disponibles, como TensorFlow, PyTorch u otros, utilizando el cálculo de punto flotante como desee. Una vez que se crea un modelo, el SDK ayuda a cuantificar el modelo de red neuronal entrenado y mapearlo a la matriz de memoria donde se puede realizar la multiplicación vector-matriz con el vector de entrada proveniente de un sensor o computadora.
Conclusión
Las ventajas de este enfoque de memoria multinivel con sus capacidades de cálculo en memoria incluyen:
- Potencia extremadamente baja: La tecnología está diseñada para aplicaciones de baja potencia. La ventaja de energía de primer nivel proviene del hecho de que la solución es la computación en memoria, por lo que no se desperdicia energía en la transferencia de datos y pesos desde SRAM / DRAM durante la computación. La segunda ventaja energética proviene del hecho de que las celdas de destello funcionan en modo subumbral con valores de corriente muy bajos, por lo que la disipación de potencia activa es muy baja. La tercera ventaja es que casi no hay disipación de energía durante el modo de espera, ya que la celda de memoria no volátil no necesita energía para mantener los datos del dispositivo siempre encendido. El enfoque también es adecuado para aprovechar la escasez de pesos y datos de entrada. La celda de bits de memoria no se activa si los datos de entrada o el peso son cero.
- Menor tamaño del paquete: La tecnología utiliza una arquitectura de celda de puerta dividida (1.5T), mientras que una celda SRAM en una implementación digital se basa en una arquitectura 6T. Además, la celda es una celda de bits mucho más pequeña en comparación con una celda 6T SRAM. Además, una celda de celda puede almacenar todo el valor entero de 4 bits, a diferencia de una celda SRAM que necesita 4 * 6 =24 transistores para hacerlo. Esto proporciona una huella en el chip sustancialmente más pequeña.
- Menor costo de desarrollo: Debido a los cuellos de botella en el rendimiento de la memoria y las limitaciones de la arquitectura de von Neumann, muchos dispositivos especialmente diseñados (como Jetsen de Nvidia o TPU de Google) tienden a usar geometrías más pequeñas para obtener rendimiento por vatio, lo cual es una forma costosa de resolver el desafío de la computación de inteligencia artificial de borde. Con el enfoque de memoria multinivel que utiliza métodos de cálculo analógicos en memoria, el cálculo se realiza en el chip en celdas flash para poder utilizar geometrías más grandes y reducir los costos de máscara y los tiempos de entrega.
Las aplicaciones de Edge Computing son muy prometedoras. Sin embargo, existen desafíos de energía y costos que resolver antes de que la informática de punta pueda despegar. Se puede eliminar un obstáculo importante mediante el uso de un enfoque de memoria que realiza cálculos en chip en celdas flash. Este enfoque aprovecha una solución de tecnología de memoria multinivel de tipo estándar de facto probada en producción y optimizada para aplicaciones de aprendizaje automático.
Incrustado
- Cómo la informática perimetral podría beneficiar a la TI empresarial
- ¿Cómo la computación en la nube puede beneficiar al personal de TI?
- Una introducción a la computación perimetral y ejemplos de casos de uso
- Computación perimetral:5 trampas potenciales
- Cómo los datos de IIoT pueden impulsar la rentabilidad en la fabricación ajustada
- Más cerca del borde:cómo la informática en el borde impulsará la Industria 4.0
- Cómo un corte de energía puede dañar sus suministros de energía
- 6 buenas razones para adoptar Edge Computing
- Edge Computing y 5G escalan la empresa
- Cómo la tecnología conectada puede ayudar a resolver los desafíos de la cadena de suministro
- Cómo las tiendas pequeñas pueden volverse digitales, ¡económicamente!