


Mejores prácticas para depurar aplicaciones IoT basadas en Zephyr
El proyecto de código abierto Zephyr de la Fundación Linux se ha convertido en la columna vertebral de muchos proyectos de IoT. Zephyr ofrece el mejor sistema operativo pequeño, escalable y en tiempo real (RTOS) optimizado para dispositivos con recursos limitados, en múltiples arquitecturas. Actualmente, el proyecto cuenta con 1,000 colaboradores y 50,000 compromisos de construcción de soporte avanzado para múltiples arquitecturas, incluidas ARC, Arm, Intel, Nios, RISC-V, SPARC y Tensilica, y más de 250 placas.
Al trabajar con Zephyr, hay algunas consideraciones críticas para mantener las cosas conectadas y funcionando de manera confiable. Los desarrolladores no pueden resolver todas las clases de problemas en su escritorio y algunos solo se vuelven obvios cuando crece la flota de dispositivos. A medida que evolucionan las redes y las pilas de redes, debe asegurarse de que las actualizaciones no presenten problemas innecesarios.
Por ejemplo, considere una situación que enfrentamos con rastreadores GPS desplegados para rastrear animales de granja. El dispositivo era un collar basado en sensores que ocupaba poco espacio. En un día cualquiera, el animal deambulaba de una red móvil a otra; de país a país; de un lugar a otro. Dicho movimiento expuso rápidamente configuraciones erróneas y comportamientos inesperados que podrían conducir a una pérdida de energía que resultaría en una gran pérdida económica. No solo necesitábamos saber sobre un problema, necesitábamos saber por qué sucedió y cómo solucionarlo. Cuando se trabaja con dispositivos conectados, el monitoreo y la depuración remotos son cruciales para obtener una visión instantánea de lo que salió mal, los siguientes mejores pasos para abordar la situación y, en última instancia, cómo establecer y mantener un funcionamiento normal.
Usamos una combinación de Zephyr y la plataforma de observación de dispositivos Memfault basada en la nube para respaldar el monitoreo y la actualización de dispositivos. Según nuestra experiencia, puede aprovechar ambos para establecer las mejores prácticas para el monitoreo remoto mediante reinicios, controles, fallas / afirmaciones y métricas de conectividad.
Configuración de una plataforma de observación
Memfault permite a los desarrolladores monitorear, depurar y actualizar el firmware de forma remota, lo que nos permite:
- evite congelar la producción a favor de un producto mínimo viable y actualizaciones del día 0
- supervisar continuamente el estado general del dispositivo
- enviar actualizaciones y parches antes de que la mayoría de los usuarios finales noten problemas, si los hay,
El SDK de Memfault se integra fácilmente para recopilar paquetes de datos para el análisis de la nube y la deduplicación de problemas. Funciona como un módulo Zephyr típico donde lo agrega a su archivo de manifiesto.
# west.yml [...] - nombre:memfault-firmware-sdk URL:https://github.com/memfault/memfault-firmware-sdk ruta:módulos / memfault-firmware-sdk revisión:maestra # prj.conf CONFIG_MEMFAULT =y CONFIG_MEMFAULT_HTTP_ENABLE =y
Primera área de interés:reinicios
Suponga que ve un aumento considerable de restablecimientos en su dispositivo. A menudo, este es un indicador temprano de que algo en la topología ha cambiado o que los dispositivos están comenzando a experimentar problemas debido a defectos de hardware. Es la información más pequeña que puede recopilar para comenzar a obtener información sobre el estado del dispositivo, y ayuda a pensar en dos partes:reinicios de hardware y reinicios de software.
Los reinicios de hardware a menudo se deben a controles de hardware y caídas de tensión. Los reinicios de software pueden deberse a actualizaciones de firmware, afirmaciones o pueden ser iniciados por el usuario.
Después de identificar qué tipos de reinicios se están produciendo, podemos comprender si hay problemas que están afectando a toda la flota o si se limitan a un pequeño porcentaje de dispositivos.
Registrar el motivo del reinicio
anulado fw_update_finish (void) { // ... memfault_reboot_tracking_mark_reset_imminent (kMfltRebootReason_FirmwareUpdate, ...); sys_reboot (0); } Zephyr tiene un mecanismo para registrar regiones que se conservarán a través de un reinicio al que se engancha Memfault. Si está a punto de reiniciar la plataforma, le recomendamos que guarde antes de comenzar. Cuando reinicie la plataforma, registre el motivo de su reinicio, en este caso, una actualización de firmware, y luego llámelo Zephyr sys_reboot.
Captura de restablecimientos del dispositivo en Zephyr
Registrar el controlador de inicio para leer la información de arranque
estático int record_reboot_reason () { // 1. Lea el registro de motivo de restablecimiento de hardware. (Consulte la hoja de datos de MCU para ver el nombre de registro) // 2. Capturar el motivo del restablecimiento del software desde la RAM noinit // 3. Enviar datos al servidor para su agregación } SYS_INIT (record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); Puede configurar una macro que capture la información del sistema antes de que se reinicie a través del registro de motivo de reinicio de la MCU. Cuando el dispositivo se reinicia, Zephyr registrará los controladores mediante la macro system_int. Todos los registros de motivo de restablecimiento de MCU tienen nombres ligeramente diferentes y todos son útiles porque puede ver si hay problemas o defectos de hardware.
Ejemplo:problema con la fuente de alimentación
Veamos un ejemplo de cómo el monitoreo remoto puede brindar información vital sobre el estado de la flota al observar los reinicios y el suministro de energía. Aquí podemos ver una pequeña cantidad de dispositivos que representan más de 12,000 reinicios (Figura 1).
haga clic para ver la imagen en tamaño completo

Figura 1:Ejemplo de problema con la fuente de alimentación, tabla de reinicios durante 15 días. (Fuente:Autores)
- 12.000 reinicios del dispositivo al día: demasiados
- 99% de los reinicios aportados por 10 dispositivos
- Parte mecánica defectuosa que contribuye a que el dispositivo se reinicie constantemente
En este caso, algunos dispositivos se reinician 1000 veces al día, probablemente debido a un problema mecánico (pieza defectuosa, mal contacto de la batería o varios problemas de frecuencia crónica).
Una vez que los dispositivos están en producción, puede manejar varios de estos problemas a través de actualizaciones de firmware. La implementación de una actualización le permite solucionar defectos de hardware y evitar la necesidad de intentar recuperar y reemplazar dispositivos.
Segunda área de interés:perros guardianes
Cuando se trabaja con pilas conectadas, un perro guardián es la última línea de defensa para que un sistema vuelva a un estado limpio sin reiniciar manualmente el dispositivo. Los bloqueos pueden ocurrir por muchas razones, como
- Bloques de pila de conectividad al enviar ()
- Bucles de reintento infinitos
- Puntos muertos entre tareas
- Corrupción
Los perros guardianes de hardware son un periférico dedicado en la MCU que debe ser "alimentado" periódicamente para evitar que reinicien el dispositivo. Los controles de software se implementan en el firmware y se activan antes del control de hardware para permitir la captura del estado del sistema que conduce al control de hardware
Zephyr tiene una API de vigilancia de hardware donde todas las MCU pueden pasar por la API genérica para instalar y configurar la vigilancia en la plataforma. (Consulte la API de Zephyr para obtener más detalles:zephyr / include / drivers / watchdog.h)
// ... anular start_watchdog (void) { // consulte el árbol de dispositivos para conocer el control de hardware disponible s_wdt =device_get_binding (DT_LABEL (DT_INST (0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ / * Restablece el SoC cuando expira el temporizador de vigilancia. * / .flags =WDT_FLAG_RESET_SOC, / * Caducar el perro guardián después de la ventana máxima * / .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout (s_wdt, &wdt_config); const uint8_t opciones =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup (s_wdt, opciones); // TODO:Iniciar un perro guardián de software } anular feed_watchdog (void) { wdt_feed (s_wdt, s_wdt_channel_id); // TODO:Control del software de feeds } Analicemos algunos pasos con este ejemplo del nRF9160 nórdico.
- Vaya al árbol de dispositivos y configure la carpeta de tiempo de reproducción de Nordic nRF.
- Establezca las opciones de configuración para el perro guardián a través de la API expuesta.
- Instale el perro guardián.
- Alimente periódicamente al perro guardián cuando los comportamientos se estén ejecutando según lo esperado. A veces, esto se hace desde las tareas de menor prioridad. Si el sistema está bloqueado, se reiniciará.
Usando Memfault en Zephyr, puede hacer uso de temporizadores del kernel, impulsados por un periférico temporizador. Puede configurar el tiempo de espera del perro guardián del software para que esté por delante del perro guardián del hardware (por ejemplo, establezca el perro guardián del hardware en 60 segundos y el perro guardián del software en 50 segundos). Si alguna vez se invoca la devolución de llamada, se activará una aserción, que lo llevará a través del controlador de fallas de Zephyr y obtendrá información sobre lo que estaba sucediendo en ese momento en el que el sistema estaba atascado.
Ejemplo:controlador SPI atascado
Volvamos nuevamente a un ejemplo de un problema que no está atrapado en el desarrollo sino que surge en el campo. En la Figura 2, puede ver el tiempo, los hechos y la degradación en los chips del controlador SPI.
haga clic para ver la imagen en tamaño completo
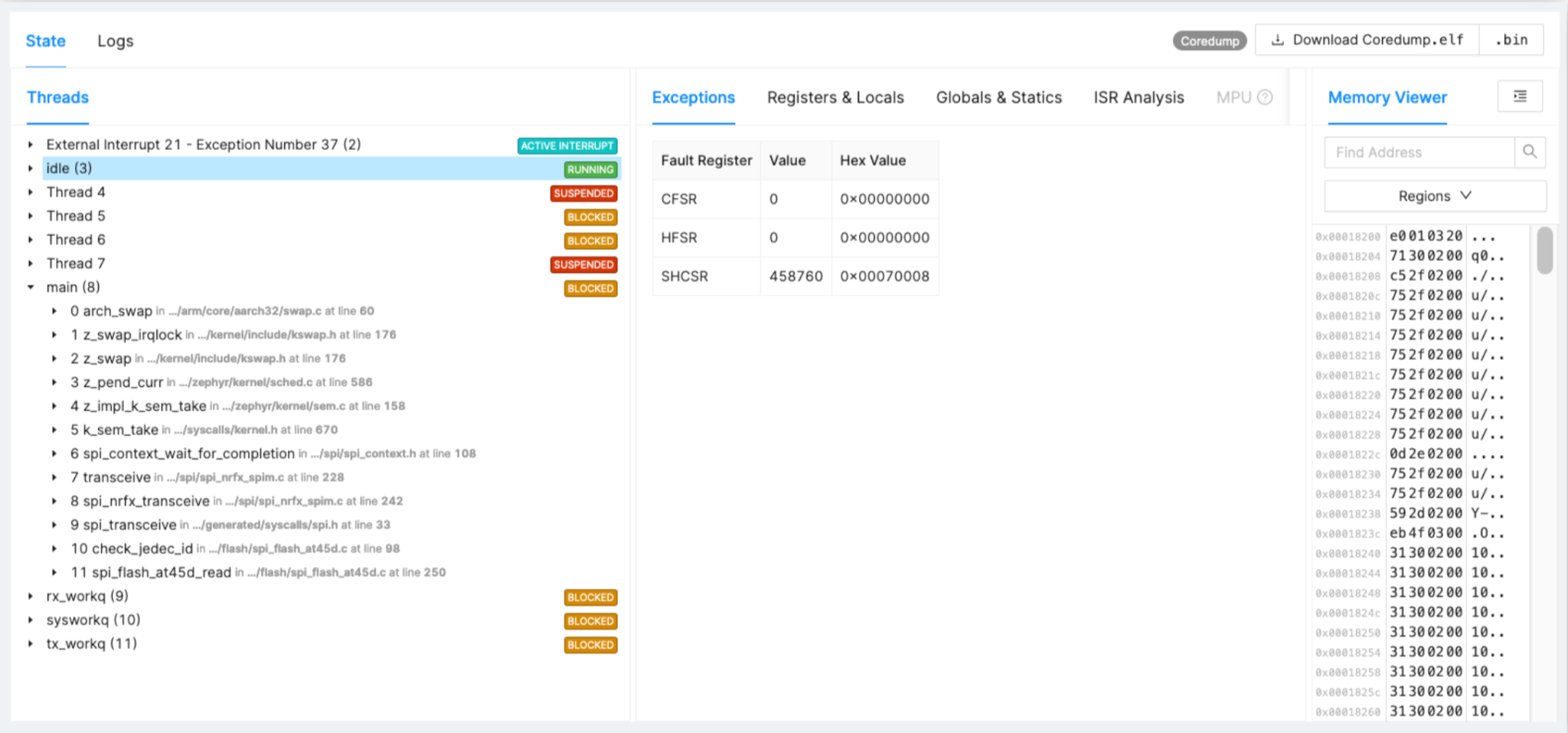
Figura 2:Ejemplo de controlador SPI atascado. (Fuente:Autores)
- El flash SPI se degrada con el tiempo, sincronización incorrecta de la comunicación
- Rastreó esto en el 1% de los dispositivos después de 16 meses de implementación de campo
- Corrección del controlador e implementación con la próxima versión
Para Flash, después de un año en el campo, puede ver que hay un comienzo repentino de errores debido a que se atascan en las transacciones SPI o en varios fragmentos de código. Tener el rastro completo lo ayuda a encontrar la causa raíz y desarrollar una solución.
El perro guardián a continuación (Figura 3) está iniciando el controlador de fallas Zephyr.
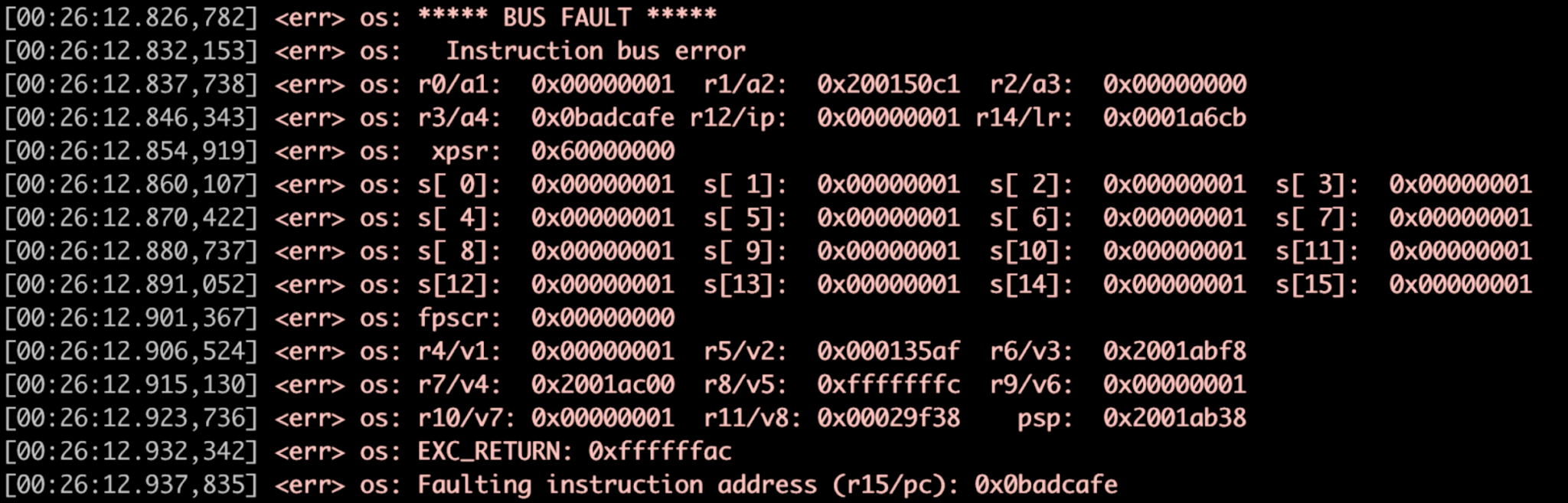
Figura 3:Ejemplo de controlador de fallas, volcado de registros. (Fuente:Autores)
Enfoque de tercer área:fallas / afirmaciones:
El tercer componente a rastrear son fallas y afirmaciones. Si alguna vez ha realizado una depuración local o ha creado algunas funciones por su cuenta, probablemente haya visto una pantalla similar sobre el estado del registro cuando se produjo una falla en la plataforma. Estos pueden deberse a:
- afirma, o
- acceder a la mala memoria
- dividir por cero
- usar un periférico de manera incorrecta
Aquí hay un ejemplo de un flujo de manejo de fallas que se toma en microcontroladores Cortex M en Zephyr.
anulado network_send (void) { const size_t tamaño_paquete =1500; void * buffer =z_malloc (tamaño_paquete); // ¡Falta el cheque NULL! memcpy (búfer, 0x0, tamaño_paquete); // ... } ↓ anular network_send (void) { const size_t tamaño_paquete =1500; void * buffer =z_malloc (tamaño_paquete); // ¡Falta el cheque NULL! memcpy (búfer, 0x0, tamaño_paquete); // ... } ↓ bool memfault_coredump_save (const sMemfaultCoredumpSaveInfo * save_info) { // Guardar estado de registro // Guardar _kernel y contextos de tareas // Guardar las regiones .bss y .data seleccionadas } ↓ anular sys_arch_reboot (tipo int) { // ... } Cuando se inicia una afirmación o una falla, se activa una interrupción y se invoca un controlador de fallas en Zephyr que proporciona el estado del registro en el momento del bloqueo.
Memfault SDK se une automáticamente al flujo de manejo de fallas, guardando información crítica en la nube, incluido el estado del registro, el estado del kernel y una parte de todas las tareas que se ejecutan en el sistema en el momento del bloqueo.
Hay tres cosas que debe buscar cuando está depurando local o remotamente:
- El registro de estado de falla de Cortex M le dice por qué la plataforma se afirmó o falló.
- Memfault recupera la línea exacta de código que el sistema estaba ejecutando antes del bloqueo y el estado de todas las demás tareas.
- Recopile el _kernel estructura en el Zephyr RTOS para ver el programador y, si es una aplicación conectada, el estado de los parámetros de Bluetooth o LTE.
Cuarta área de interés:seguimiento de métricas para la observabilidad del dispositivo
Las métricas de seguimiento le permiten comenzar a construir un patrón de lo que está sucediendo en su sistema y le permite hacer comparaciones entre sus dispositivos y su flota para comprender qué cambios están teniendo un impacto.
Algunas métricas útiles para realizar un seguimiento son:
- Utilización de la CPU
- parámetros de conectividad
- uso de calor
Con Memfault SDK, puede agregar y comenzar a definir métricas en Zephyr con dos líneas de código:
- Definir métrica
MEMFAULT_METRICS_KEY_DEFINE ( LteDisconnect, kMemfaultMetricType_Unsigned)
- Actualizar la métrica en el código
anulado lte_disconnect (void) { memfault_metrics_heartbeat_add ( MEMFAULT_METRICS_KEY (LteDisconnect), 1); // ... } Memfault SDK + Cloud
- Serializa y comprime métricas para el transporte
- Indiza métricas por dispositivo y versión de firmware
- Expone la interfaz web para las métricas de navegación por dispositivo y en toda la flota
Se pueden recopilar e indexar docenas de métricas por dispositivo y versión de firmware. Algunos ejemplos:
- Conectividad básica NB-IoT / LTE-M: Vea cómo un módem afecta la duración de la batería, ya sea al estar conectado o al conectarse.
- Seguimiento de estaciones base y PSM en NB-IoT / LTE-M: La calidad de la señal móvil puede ser dolorosa y puede agotar la vida útil de la batería si no se administra. Cree métricas para el estado de la red, eventos, información de torres de telefonía celular, configuraciones, temporizadores y más. Supervise los cambios y utilice las alertas.
- Prueba de flotas grandes: Los datos inesperadamente grandes pueden aumentar los costos de conectividad del dispositivo y ayudar a identificar valores atípicos.
Ejemplo:tamaño de datos NB-IoT / LTE-M
haz clic para ver la imagen en tamaño completo
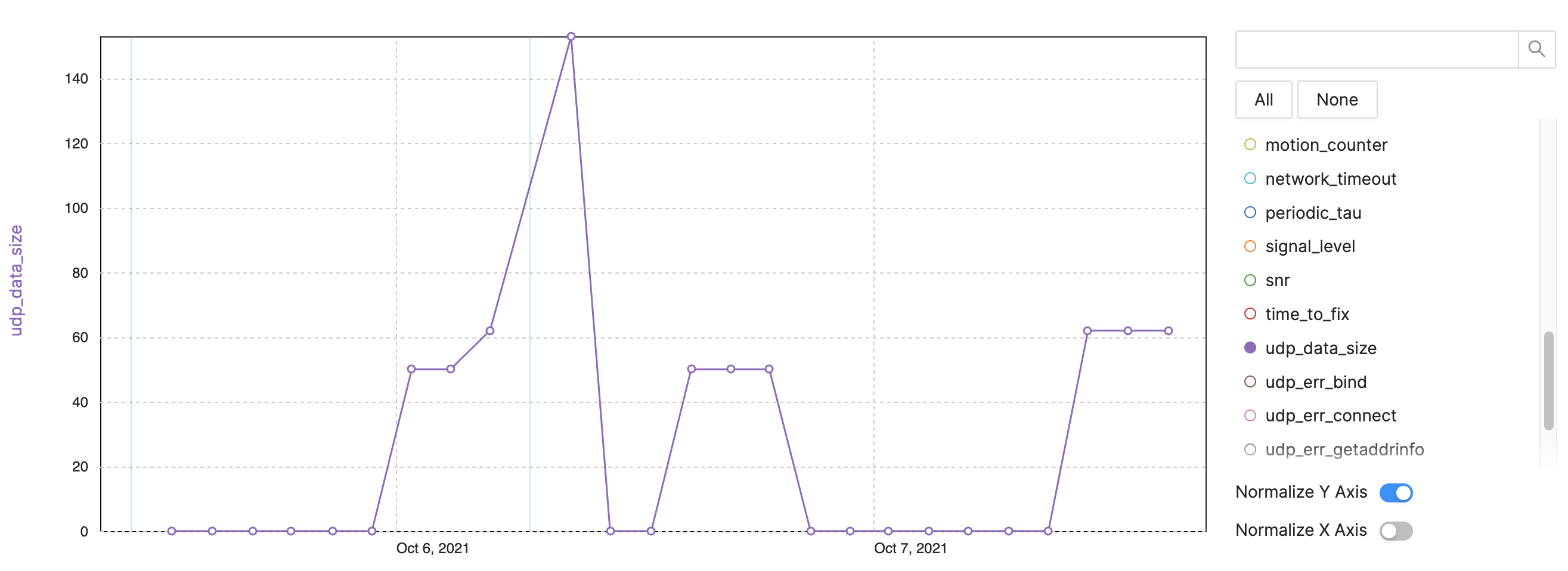
Figura 4:Métricas de seguimiento para la observabilidad del dispositivo:ejemplo de NB-IoT, tamaño de datos LTE-M. (Fuente:Autores)
- Tamaño de datos UDP:seguimiento de bytes por intervalo de envío (Figura 4)
- Se envían más datos después del reinicio
- Algunos paquetes son más grandes debido a más información o rastros
- Realice un seguimiento del problema del consumo de datos
Conclusión
Aprovechando Zephyr y Memfault, los desarrolladores pueden implementar el monitoreo remoto para obtener una mejor observabilidad de la funcionalidad del dispositivo conectado. Al centrarse en reinicios, controles, fallos / afirmaciones y métricas de conectividad, los desarrolladores pueden optimizar el costo y el rendimiento de los sistemas de IoT.
Obtenga más información al ver una presentación grabada de la Cumbre de desarrolladores Zephyr 2021.
Tecnología de Internet de las cosas
- Mejores prácticas para el monitoreo sintético
- Mejores prácticas de seguridad para la computación en la niebla
- Transceptores bidireccionales 1G para proveedores de servicios y aplicaciones de IoT
- ETSI avanza para establecer estándares para aplicaciones de IoT en comunicaciones de emergencia
- IIC y TIoTA colaborarán en las mejores prácticas de IoT/Blockchain
- NIST publica borrador de recomendaciones de seguridad para fabricantes de IoT
- La asociación apunta a una duración ilimitada de la batería del dispositivo IoT
- Las 3 mejores razones para utilizar la tecnología IoT para la gestión de activos
- ¿Por qué considerar IoT como la mejor plataforma para el monitoreo ambiental?
- Mejores aplicaciones para sistemas de aire comprimido
- Prácticas recomendadas de marketing de fabricación para 2019