


¿Cuántas capas y nodos ocultos necesita una red neuronal?
Este artículo proporciona pautas para configurar la parte oculta de un perceptrón multicapa.
Hasta ahora, en esta serie sobre redes neuronales, hemos analizado los NN de Perceptron, los NN multicapa y cómo desarrollar dichos NN utilizando Python. Antes de pasar a discutir cuántas capas y nodos ocultos puede elegir emplear, considere ponerse al día con la siguiente serie.
- Cómo realizar la clasificación mediante una red neuronal:¿Qué es el perceptrón?
- Cómo utilizar un ejemplo de red neuronal de Perceptron simple para clasificar datos
- Cómo entrenar una red neuronal de perceptrón básica
- Comprensión del entrenamiento de redes neuronales simples
- Introducción a la teoría del entrenamiento para redes neuronales
- Comprensión de la tasa de aprendizaje en redes neuronales
- Aprendizaje automático avanzado con el perceptrón multicapa
- La función de activación sigmoidea:activación en redes neuronales de perceptrones multicapa
- Cómo entrenar una red neuronal de perceptrón multicapa
- Comprender las fórmulas de entrenamiento y la retropropagación para perceptrones multicapa
- Arquitectura de red neuronal para una implementación de Python
- Cómo crear una red neuronal de perceptrón multicapa en Python
- Procesamiento de señales mediante redes neuronales:validación en el diseño de redes neuronales
- Conjuntos de datos de entrenamiento para redes neuronales:cómo entrenar y validar una red neuronal Python
- ¿Cuántas capas y nodos ocultos necesita una red neuronal?
Resumen de capas ocultas
Primero, repasemos algunos puntos importantes sobre los nodos ocultos en las redes neuronales.
- Los perceptrones que constan únicamente de nodos de entrada y nodos de salida (llamados perceptrones de una sola capa) no son muy útiles porque no pueden aproximarse a las complejas relaciones de entrada-salida que caracterizan muchos tipos de fenómenos de la vida real. Más específicamente, los perceptrones de una sola capa están restringidos a separables linealmente problemas; como vimos en la Parte 7, incluso algo tan básico como la función booleana XOR no es separable linealmente.
- Agregar una capa oculta entre las capas de entrada y salida convierte al Perceptron en un aproximador universal , lo que esencialmente significa que es capaz de capturar y reproducir relaciones de entrada-salida extremadamente complejas.
- La presencia de una capa oculta hace que el entrenamiento sea un poco más complicado porque el input-to-hidden los pesos tienen un efecto indirecto sobre el error final (este es el término que utilizo para indicar la diferencia entre el valor de salida de la red y el valor objetivo proporcionado por los datos de entrenamiento).
- La técnica que usamos para entrenar un perceptrón multicapa se llama retropropagación :propagamos el error final hacia el lado de entrada de la red de una manera que nos permite modificar efectivamente los pesos que no están conectados directamente al nodo de salida. El procedimiento de retropropagación es extensible, es decir, el mismo procedimiento nos permite entrenar pesos asociados con un número arbitrario de capas ocultas.
El siguiente diagrama resume la estructura de un perceptrón multicapa básico.
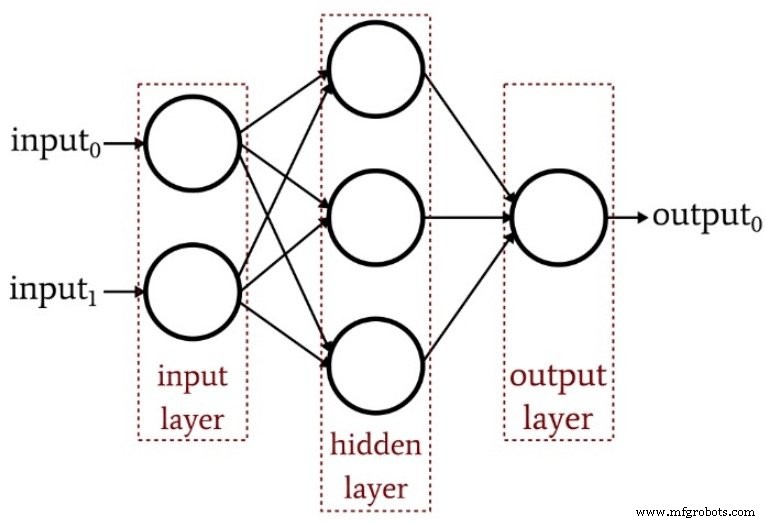
¿Cuántas capas ocultas?
Como era de esperar, no existe una respuesta sencilla a esta pregunta. Sin embargo, lo más importante que hay que entender es que un perceptrón con una capa oculta es un sistema computacional extremadamente poderoso. Si no obtiene resultados adecuados con una capa oculta, pruebe otras mejoras primero; tal vez necesite optimizar su tasa de aprendizaje, aumentar la cantidad de períodos de entrenamiento o mejorar su conjunto de datos de entrenamiento. Agregar una segunda capa oculta aumenta la complejidad del código y el tiempo de procesamiento.
Otra cosa a tener en cuenta es que una red neuronal dominada no es solo un desperdicio de esfuerzo de codificación y recursos del procesador; en realidad, puede causar un daño positivo al hacer que la red sea más susceptible al sobreentrenamiento.
Hablamos sobre el sobreentrenamiento en la Parte 4, que incluía el siguiente diagrama como una forma de visualizar el funcionamiento de una red neuronal cuya solución no está suficientemente generalizada.
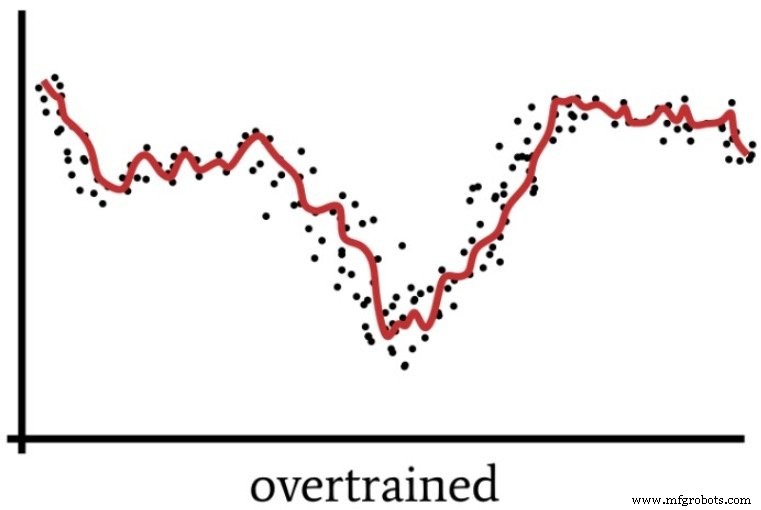
Un Perceptron superpoderoso puede procesar los datos de entrenamiento de una manera que es vagamente análoga a cómo las personas a veces "piensan demasiado" en una situación.
Cuando nos centramos demasiado en los detalles y aplicamos un esfuerzo intelectual excesivo a un problema que en realidad es bastante simple, perdemos el "panorama general" y terminamos con una solución que resultará subóptima. Del mismo modo, un perceptrón con una potencia informática excesiva y datos de entrenamiento insuficientes podría optar por una solución demasiado específica en lugar de encontrar una solución generalizada (como se muestra en la siguiente figura) que clasificará de manera más eficaz las nuevas muestras de entrada.
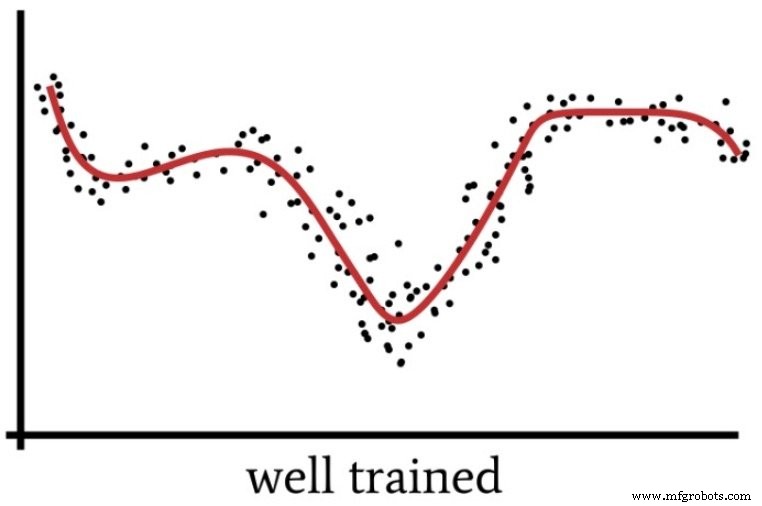
Entonces, ¿cuándo realmente necesitamos múltiples capas ocultas? No puedo darte ninguna pauta por experiencia personal. Lo mejor que puedo hacer es transmitir la experiencia del Dr. Jeff Heaton (consulte la página 158 del texto vinculado), quien afirma que una capa oculta permite que una red neuronal se aproxime a cualquier función que implique “un mapeo continuo de un espacio finito a otro . ”
Con dos capas ocultas, la red es capaz de "representar un límite de decisión arbitrario con precisión arbitraria".
¿Cuántos nodos ocultos?
Encontrar la dimensionalidad óptima para una capa oculta requerirá prueba y error. Como se mencionó anteriormente, tener demasiados nodos no es deseable, pero debe tener suficientes nodos para que la red sea capaz de capturar las complejidades de la relación entrada-salida.
Prueba y error está muy bien, pero necesitará algún tipo de punto de partida razonable. En el mismo libro vinculado anteriormente (en la página 159), el Dr. Heaton menciona tres reglas generales para elegir la dimensionalidad de una capa oculta. Me basaré en ellos ofreciendo recomendaciones basadas en mi vaga intuición de procesamiento de señales.
- Si la red tiene solo un nodo de salida y cree que la relación entrada-salida requerida es bastante sencilla, comience con una dimensionalidad de capa oculta que sea igual a dos tercios de la dimensionalidad de entrada.
- Si tiene varios nodos de salida o cree que la relación entrada-salida requerida es compleja, haga que la dimensionalidad de la capa oculta sea igual a la dimensionalidad de la entrada más la dimensionalidad de la salida (pero manténgala menos del doble de la dimensionalidad de la entrada).
- Si cree que la relación entrada-salida requerida es extremadamente compleja, establezca la dimensionalidad oculta en uno menos del doble de la dimensionalidad de entrada.
Conclusión
Espero que este artículo le haya ayudado a comprender el proceso de configuración y perfeccionamiento de la configuración de capa oculta de un perceptrón multicapa.
En el próximo artículo, exploraremos los efectos de la dimensionalidad de la capa oculta usando mi implementación de Python y algunos problemas de ejemplo.
Robot industrial
- ¿Qué es una prensa de palanca y cómo funciona?
- ¿Cómo funciona una prensa de piñón y cremallera?
- ¿Qué es el moldeo por transferencia y cómo funciona?
- ¿Qué es una transmisión y cómo funciona?
- Incorporación de nodos de sesgo en su red neuronal
- Cómo aumentar la precisión de una red neuronal de capa oculta
- Conjuntos de datos de entrenamiento para redes neuronales:cómo entrenar y validar una red neuronal Python
- Cómo crear una red neuronal de perceptrón multicapa en Python
- Comprender las fórmulas de entrenamiento y la retropropagación para perceptrones multicapa
- ¿Qué es un embrague industrial y cómo funciona?
- ¿Cuántos HP necesita una bomba hidráulica?