


Cómo crear una red neuronal de perceptrón multicapa en Python
Este artículo lo lleva paso a paso a través de un programa de Python que nos permitirá entrenar una red neuronal y realizar una clasificación avanzada.
Esta es la entrada número 12 en la serie de desarrollo de redes neuronales de AAC. Vea qué más ofrece la serie a continuación:
- Cómo realizar la clasificación mediante una red neuronal:¿Qué es el perceptrón?
- Cómo utilizar un ejemplo de red neuronal de Perceptron simple para clasificar datos
- Cómo entrenar una red neuronal de perceptrón básica
- Comprensión del entrenamiento de redes neuronales simples
- Introducción a la teoría del entrenamiento para redes neuronales
- Comprensión de la tasa de aprendizaje en redes neuronales
- Aprendizaje automático avanzado con el perceptrón multicapa
- La función de activación sigmoidea:activación en redes neuronales de perceptrones multicapa
- Cómo entrenar una red neuronal de perceptrón multicapa
- Comprender las fórmulas de entrenamiento y la retropropagación para perceptrones multicapa
- Arquitectura de red neuronal para una implementación de Python
- Cómo crear una red neuronal de perceptrón multicapa en Python
- Procesamiento de señales mediante redes neuronales:validación en el diseño de redes neuronales
- Conjuntos de datos de entrenamiento para redes neuronales:cómo entrenar y validar una red neuronal Python
En este artículo, tomaremos el trabajo que hemos hecho en las redes neuronales de Perceptron y aprenderemos cómo implementar una en un lenguaje familiar:Python.
Desarrollo de código Python comprensible para redes neuronales
Recientemente, he examinado bastantes recursos en línea para redes neuronales y, aunque indudablemente hay mucha información buena, no estaba satisfecho con las implementaciones de software que encontré. Siempre eran demasiado complejos, demasiado densos o no lo suficientemente intuitivos. Cuando estaba escribiendo mi red neuronal Python, realmente quería hacer algo que pudiera ayudar a las personas a aprender sobre cómo funciona el sistema y cómo la teoría de la red neuronal se traduce en instrucciones de programa.
Sin embargo, a veces existe una relación inversa entre la claridad del código y la eficiencia del código. El programa que discutiremos en este artículo es definitivamente no optimizado para un rendimiento rápido. La optimización es un problema serio dentro del dominio de las redes neuronales; Las aplicaciones de la vida real pueden requerir una gran cantidad de entrenamiento y, en consecuencia, una optimización completa puede conducir a reducciones significativas en el tiempo de procesamiento. Sin embargo, para experimentos simples como los que haremos, la capacitación no lleva mucho tiempo y no hay razón para preocuparse por las prácticas de codificación que favorecen la simplicidad y la comprensión sobre la velocidad.
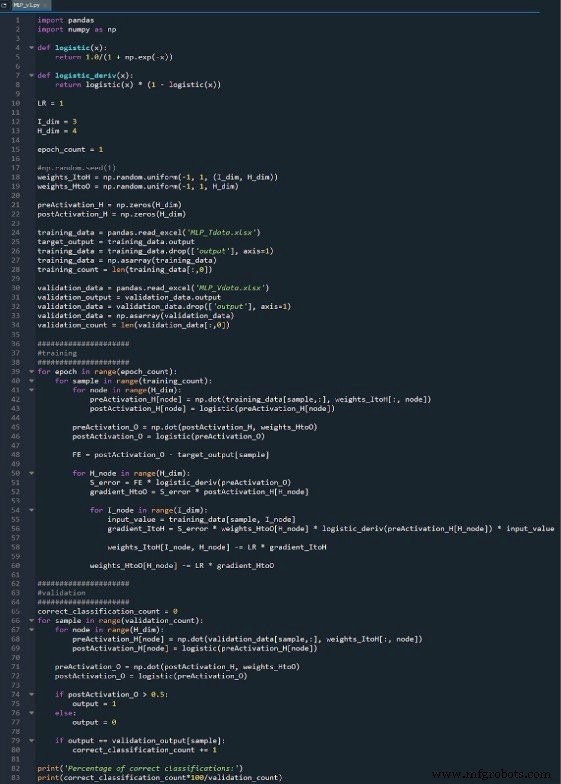
El programa Python completo se incluye como una imagen al final de este artículo y el archivo ("MLP_v1.py") se proporciona como descarga. El código realiza tanto entrenamiento como validación; este artículo se centra en la formación y analizaremos la validación más adelante. En cualquier caso, sin embargo, no hay muchas funciones en la parte de validación que no se tratan en la parte de formación.
Mientras reflexiona sobre el código, es posible que desee mirar hacia atrás en el diagrama de arquitectura más terminología, un poco abrumador pero muy informativo, que proporcioné en la Parte 10.
Preparación de funciones y variables
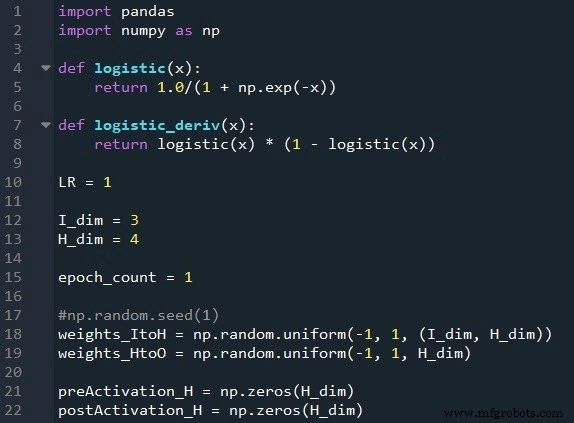
La biblioteca NumPy se usa ampliamente para los cálculos de la red, y la biblioteca Pandas me brinda una forma conveniente de importar datos de entrenamiento desde un archivo de Excel.
Como ya sabe, estamos utilizando la función sigmoidea logística para la activación. Necesitamos la función logística en sí para calcular los valores posteriores a la activación, y la derivada de la función logística es necesaria para la propagación hacia atrás.
A continuación, elegimos la tasa de aprendizaje, la dimensionalidad de la capa de entrada, la dimensionalidad de la capa oculta y el recuento de época. El entrenamiento en múltiples épocas es importante para las redes neuronales reales, porque le permite extraer más aprendizaje de sus datos de entrenamiento. Cuando genera datos de entrenamiento en Excel, no necesita ejecutar varias épocas porque puede crear fácilmente más muestras de entrenamiento.
El np.random.uniform () La función llena nuestras dos matrices de peso con valores aleatorios entre –1 y +1. (Tenga en cuenta que la matriz oculta a salida es en realidad solo una matriz, porque solo tenemos un nodo de salida). La np.random.seed (1) La instrucción hace que los valores aleatorios sean los mismos cada vez que ejecuta el programa. Los valores de ponderación iniciales pueden tener un efecto significativo en el rendimiento final de la red entrenada, por lo que si está tratando de evaluar cómo otros Las variables mejoran o degradan el rendimiento, puede descomentar esta instrucción y, por lo tanto, eliminar la influencia de la inicialización de peso aleatorio.
Finalmente, creo matrices vacías para los valores de preactivación y postactivación en la capa oculta.
Importación de datos de entrenamiento

Este es el mismo procedimiento que utilicé en la Parte 4. Importo datos de entrenamiento desde Excel, separo los valores objetivo en la columna "salida", elimino la columna "salida", convierto los datos de entrenamiento en una matriz NumPy y almaceno la cantidad de muestras de entrenamiento en el training_count variable.
Procesamiento anticipado
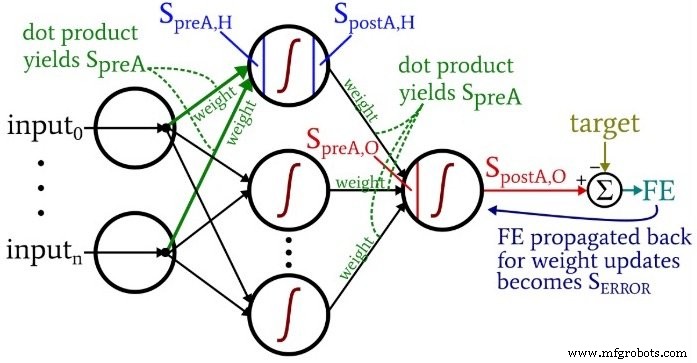
Los cálculos que producen un valor de salida, y en los que los datos se mueven de izquierda a derecha en un diagrama de red neuronal típico, constituyen la parte de "retroalimentación" de la operación del sistema. Aquí está el código de feedforward:
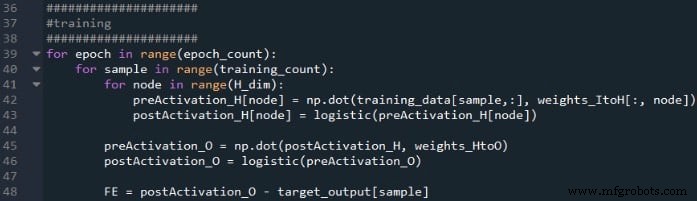
El primer bucle for nos permite tener varias épocas. Dentro de cada época, calculamos un valor de salida (es decir, la señal de postactivación del nodo de salida) para cada muestra, y esa operación muestra por muestra es capturada por el segundo ciclo for. En el tercer bucle for, atendemos individualmente a cada nodo oculto, utilizando el producto punto para generar la señal de preactivación y la función de activación para generar la señal de postactivación.
Después de eso, estamos listos para calcular la señal de preactivación para el nodo de salida (nuevamente usando el producto punto), y aplicamos la función de activación para generar la señal de postactivación. Luego restamos el objetivo de la señal de postactivación del nodo de salida para calcular el error final.
Retropropagación
Una vez que hayamos realizado los cálculos de anticipación, es hora de invertir las direcciones. En la parte de retropropagación del programa, nos movemos desde el nodo de salida hacia los pesos de oculta a salida y luego los pesos de entrada a oculta, trayendo con nosotros la información de error que usamos para entrenar eficazmente la red.

Tenemos dos capas de bucles for aquí:una para los pesos de oculta a salida y otra para las ponderaciones de entrada a oculta. Primero generamos S ERROR , que necesitamos para calcular tanto el gradiente HtoO y degradado ItoH , y luego actualizamos los pesos restando el gradiente multiplicado por la tasa de aprendizaje.
Observe cómo se actualizan las ponderaciones de entrada a oculta dentro de el bucle de salida oculta. Comenzamos con la señal de error que conduce a uno de los nodos ocultos, luego extendemos esa señal de error a todos los nodos de entrada que están conectados a este nodo oculto:
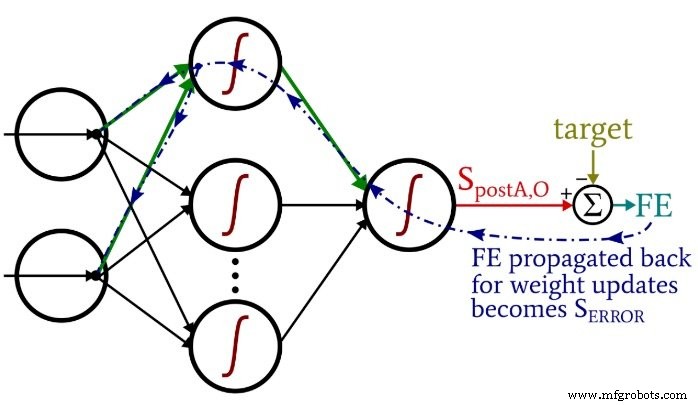
Después de que se hayan actualizado todos los pesos (tanto ItoH como HtoO) asociados con ese nodo oculto, retrocedemos y comenzamos de nuevo con el siguiente nodo oculto.
También tenga en cuenta que los pesos ItoH se modifican antes que los pesos HtoO. Usamos el peso actual de HtoO cuando calculamos el gradiente ItoH , por lo que no queremos cambiar los pesos de HtoO antes de que se haya realizado este cálculo.
Conclusión
Es interesante pensar en cuánta teoría se ha invertido en este programa de Python relativamente corto. Espero que este código le ayude a comprender realmente cómo podemos implementar una red neuronal Perceptron multicapa en el software.
Puede encontrar mi código completo a continuación:
Código de descarga
Robot industrial
- Cómo crear una plantilla de CloudFormation con AWS
- ¿Cómo crear un centro de excelencia en la nube?
- Cómo crear UX sin fricciones
- Cómo crear una lista de cadenas en VHDL
- Cómo crear un banco de pruebas de autocomprobación
- Cómo crear un temporizador en VHDL
- Cómo crear un proceso sincronizado en VHDL
- Comprender los mínimos locales en el entrenamiento de redes neuronales
- Incorporación de nodos de sesgo en su red neuronal
- Cómo crear una matriz de objetos en Java
- Python - Programación de redes