


Arquitectura de red neuronal para una implementación de Python
Este artículo analiza la configuración de Perceptron que usaremos para nuestros experimentos con el entrenamiento y la clasificación de redes neuronales, y también veremos el tema relacionado de nodos de sesgo.
Bienvenido a la serie de artículos técnicos sobre redes neuronales Todo sobre circuitos. En la serie hasta ahora, vinculada a continuación, hemos cubierto un poco de teoría sobre las redes neuronales.
- Cómo realizar la clasificación mediante una red neuronal:¿Qué es el perceptrón?
- Cómo utilizar un ejemplo de red neuronal de Perceptron simple para clasificar datos
- Cómo entrenar una red neuronal de perceptrón básica
- Comprensión del entrenamiento de redes neuronales simples
- Introducción a la teoría del entrenamiento para redes neuronales
- Comprensión de la tasa de aprendizaje en redes neuronales
- Aprendizaje automático avanzado con el perceptrón multicapa
- La función de activación sigmoidea:activación en redes neuronales de perceptrones multicapa
- Cómo entrenar una red neuronal de perceptrón multicapa
- Comprender las fórmulas de entrenamiento y la retropropagación para perceptrones multicapa
- Arquitectura de red neuronal para una implementación de Python
- Cómo crear una red neuronal de perceptrón multicapa en Python
- Procesamiento de señales mediante redes neuronales:validación en el diseño de redes neuronales
- Conjuntos de datos de entrenamiento para redes neuronales:cómo entrenar y validar una red neuronal Python
Ahora estamos listos para comenzar a convertir este conocimiento teórico en un sistema funcional de clasificación Perceptron.
Primero quiero presentar las características generales de la red que implementaremos en un lenguaje de programación de alto nivel; Estoy usando Python, pero el código se escribirá de una manera que facilite la traducción a otros lenguajes como C. El siguiente artículo proporciona un recorrido detallado del código Python, y luego exploraremos diferentes formas de entrenamiento. , usando y evaluando esta red.
La arquitectura de red neuronal de Python
El software corresponde al Perceptron que se muestra en el siguiente diagrama.
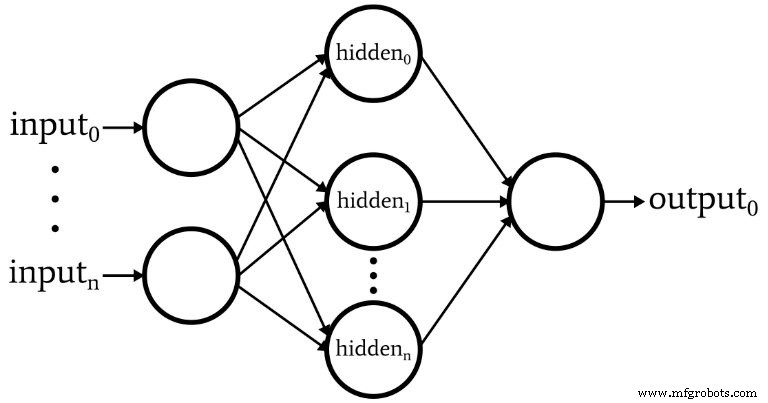
Estas son las características básicas de la red:
- El número de nodos de entrada es variable. Esto es esencial si queremos una red que tenga un grado significativo de flexibilidad, porque la dimensionalidad de entrada debe coincidir con la dimensionalidad de las muestras que queremos clasificar.
- El código no admite varias capas ocultas. En este punto no es necesario:una capa oculta es suficiente para una clasificación extremadamente poderosa.
- El número de nodos dentro de una capa oculta es variable. Encontrar el número óptimo de nodos ocultos implica algo de prueba y error, aunque existen pautas que pueden ayudarnos a elegir un punto de partida razonable. Exploraremos el tema de la dimensionalidad de la capa oculta en un artículo futuro.
- La cantidad de nodos de salida está actualmente fijada en uno. Esta limitación hará que nuestro programa inicial sea un poco más simple y podremos incorporar la dimensionalidad de salida variable en una versión mejorada.
- La función de activación para los nodos ocultos y de salida será la relación sigmoide logística estándar:
\ [f (x) =\ frac {1} {1 + e ^ {- x}} \]
¿Qué es un nodo de sesgo? (AKA Bias es bueno si eres un perceptrón)
Mientras discutimos la arquitectura de red, debo señalar que las redes neuronales a menudo incorporan algo llamado nodo de sesgo (o puede llamarlo simplemente un "sesgo", sin "nodo"). El valor numérico asociado con un nodo de sesgo es una constante elegida por el diseñador. Por ejemplo:
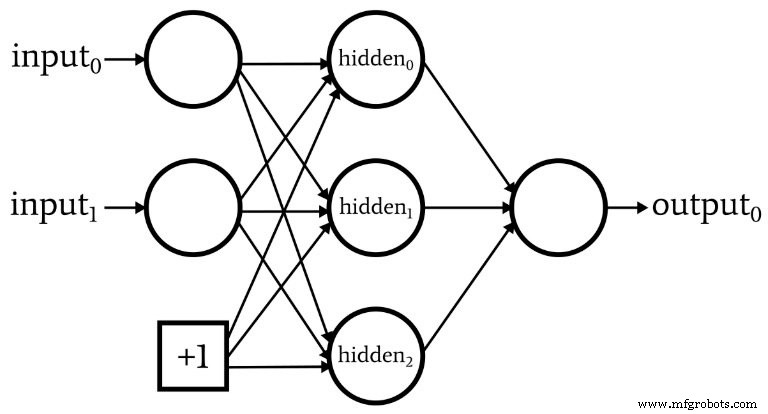
Los nodos de sesgo se pueden incorporar en la capa de entrada o en la capa oculta, o en ambas. Sus ponderaciones son como cualquier otra ponderación y se actualizan utilizando el mismo procedimiento de retropropagación.
El uso de nodos de sesgo es una razón importante para escribir código de red neuronal que le permite cambiar fácilmente la cantidad de nodos de entrada o nodos ocultos, incluso si solo está interesado en una tarea de clasificación específica, la dimensionalidad de la capa de entrada variable y la capa oculta asegura que pueda experimentar cómodamente con el uso de nodos de sesgo.
En la parte 10, señalé que la señal de preactivación de un nodo se calcula realizando un producto escalar, es decir, multiplica los elementos correspondientes de dos matrices (o vectores, si lo prefiere) y luego suma todos los productos individuales. La primera matriz contiene los valores posteriores a la activación de la capa anterior, y la segunda matriz contiene los pesos que conectan la capa anterior a la capa actual. Por lo tanto, si la matriz de postactivación de la capa anterior se indica con x y el vector de peso se indica con w, se calcula un valor de preactivación de la siguiente manera:
\ [S_ {preA} =w \ cdot x =sum (w_1x_1 + w_2x_2 + \ cdots + w_nx_n) \]
Quizás se pregunte qué diablos tiene esto que ver con los nodos de sesgo. Bueno, el sesgo (indicado por b) modifica este procedimiento de la siguiente manera:
\ [S_ {preA} =(w \ cdot x) + b =sum (w_1x_1 + w_2x_2 + \ cdots + w_nx_n) + b \]
Un sesgo desplaza la señal que es procesada por la función de activación y, por lo tanto, puede hacer que la red sea más flexible y robusta. El uso de la letra b para indicar el valor de sesgo recuerda a la "intersección con el eje y" en la ecuación estándar para una línea recta:y =mx + b . Y esto no es una casualidad. De hecho, el sesgo es como una intersección con el eje y, y es posible que también haya notado que la matriz de pesos es equivalente a una pendiente:
\ [S_ {preA} =(w \ cdot x) + b \]
\ [y =mx + b \]
Pesos, sesgo y activación
Si pensamos en los valores numéricos entregados a la función de activación de un nodo durante el entrenamiento, los pesos aumentan o disminuyen la pendiente de los datos de entrada y el sesgo desplaza los datos de entrada verticalmente. Pero, ¿cómo afecta esto a la salida del nodo? Bueno, supongamos que estamos usando la función logística estándar para la activación:
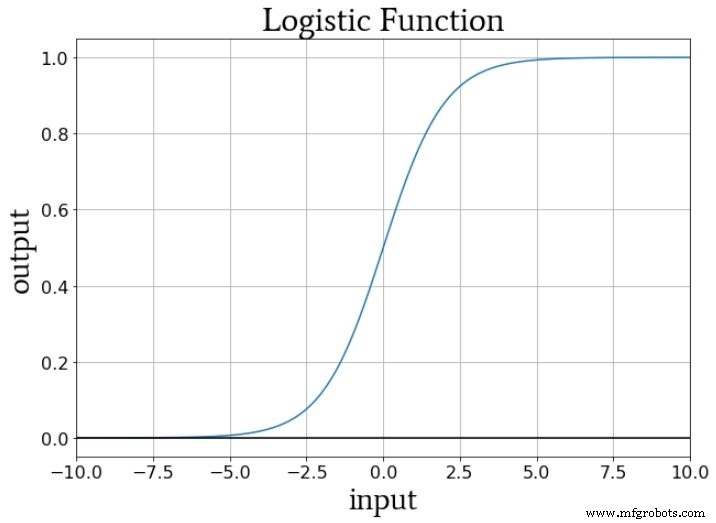
La transición de f A (x) =0 af A (x) =1 está centrado en un valor de entrada de x =0. Por lo tanto, al usar un sesgo para aumentar o disminuir la señal de preactivación, podemos influir en la ocurrencia de la transición y, por lo tanto, cambiar la función de activación hacia la izquierda o hacia la derecha. . Los pesos, por otro lado, determinan qué tan "rápido" pasa el valor de entrada a través de x =0, y esto influye en la inclinación de la transición en la función de activación.
Conclusión
Hemos hablado de los nodos de sesgo y las características destacadas de la primera red neuronal que implementaremos en software. Ahora estamos listos para ver el código real, y eso es exactamente lo que haremos en el próximo artículo.
Robot industrial
- 5 métricas de red para un mundo en la nube
- Introducción a la arquitectura de red en AWS Cloud
- Python para bucle
- Un desglose de la arquitectura NB-IoT para arquitectos de IoT
- ¿Busca una alternativa de Z-Wave?
- Descripción general de un ingeniero de la arquitectura de red M2M
- CEVA:procesador de inteligencia artificial de segunda generación para cargas de trabajo de redes neuronales profundas
- La infraestructura de red es clave para los automóviles sin conductor
- Python - Programación de redes
- 5 consejos básicos de seguridad de red para pequeñas empresas
- Explicador:¿Por qué 5G es tan importante para IoT?