


Startup empaqueta 1000 núcleos RISC-V en el chip acelerador AI
El chip de eficiencia energética de la startup apunta a M.2 Zócalos de acelerador para modelos de recomendación de exceso de velocidad en centros de datos.
Coincidiendo con la conferencia Hot Chips, la startup Esperanto salió del modo sigiloso esta semana con el chip RISC-V comercial de mayor rendimiento hasta la fecha:un acelerador de inteligencia artificial de mil núcleos diseñado para centros de datos a gran escala. Si bien el chip se puede ejecutar en varios perfiles de voltaje y potencia entre 10 y 60 W, su "punto óptimo" es de 20 W de potencia por chip, una configuración que permite montar seis chips en una tarjeta aceleradora Glacier Point, manteniendo el consumo total por debajo de 120 W. El rendimiento total de seis chips es de aproximadamente 800 TOPS.
Se anuncia que el ET-SoC-1 de Esperanto tiene la mayor cantidad de núcleos RISC-V jamás construidos en un solo chip:1.093. El recuento incluye 1.088 núcleos RISC-V personalizados de ET-Minion que sirven como motores de aceleración de IA energéticamente eficientes. También se incluyen cuatro núcleos ET-Maxion RISC-V y un procesador de servicio RISC-V. Todo el diseño está orientado a la eficiencia energética.
Antes de Hot Chips, EE Times habló con el veterano de la industria Dave Ditzel, fundador y presidente ejecutivo de Esperanto. (Las credenciales de Ditzel incluyen la coautoría con David Patters en el artículo fundamental, "The Case for the Reduced Instruction Set Computer" publicado en 1980.)

Dave Ditzel (Fuente:Esperanto)
“Somos los primeros en poner mil núcleos RISC-V en un solo chip”, dijo Ditzel. “La gente ha hablado de CPU de muchos núcleos durante años, pero no hemos visto mucho de eso. La mayoría de las cosas de RISC-V disponibles están disponibles para incrustaciones.
"Dijimos:'Vamos a mostrarles que RISC-V puede hacer de alta gama ... Les mostraremos lo que los diseñadores de CPU realmente experimentados pueden hacer aquí'".
Requisitos del cliente
El equipo de diseñadores de CPU de Ditzel pudo obtener detalles de los operadores de centros de datos a gran escala sobre sus requisitos.
"No querían un chip de entrenamiento, no tenían ningún problema con el entrenamiento", dijo Ditzel. El entrenamiento de IA es a menudo un problema fuera de línea, y la enorme capacidad de la CPU x86 de los hiperescaladores no siempre está en la carga máxima. Por lo tanto, esa capacidad se puede utilizar para la formación cuando esté disponible. "Su verdadero problema es la inferencia", agregó Ditzel. "Eso es lo que impulsa su publicidad. Necesitan una respuesta en 10 milisegundos o menos ".
Por lo tanto, la aceleración del motor de inferencia de recomendaciones para la publicidad en línea se convirtió en el foco del chip del centro de datos. Los requisitos de los hiperescaladores para acelerar este tipo de modelo eran bastante explícitos.
“Nuestros clientes querían 100 megabytes de memoria en chip; todas las cosas que querían hacer con la inferencia cabían en 100 megabytes”, dijo. Los clientes también querían una interfaz externa para la memoria fuera del chip. “El problema real es cuánto puede retener en la tarjeta del acelerador”, explicó Ditzel. “Piense en la tarjeta como la unidad de cálculo, no como el chip. Una vez que puede obtener memoria en la tarjeta, puede acceder a las cosas mucho más rápido que cruzar el bus PCIe hasta el host ”.
haga clic para ver la imagen a tamaño completo

Esperanto encaja seis tarjetas M.2 duales, cada una con un chip, en una tarjeta aceleradora Glacier Point. (Fuente:Esperanto)
El sistema de memoria en chip tiene cachés L1, L2 y L3 y un sistema de memoria principal completo con archivos de registro para un total de poco más de 100 MB. El sistema de memoria en la tarjeta puede contener la mayoría de pesos y activaciones en el modelo en alrededor de 100 GB.
Los modelos de recomendación son notoriamente difíciles de acelerar, que es una de las razones por las que todavía se ejecutan en servidores de CPU existentes.
“Cuando selecciona entre 100 millones de clientes y lo que han estado comprando recientemente, debe acceder a esta ... memoria en la tarjeta, y está haciendo todo tipo de accesos aleatorios a la memoria, por lo que los cachés no lo hacen trabajo. Realmente necesitas más de una computadora clásica ”, dijo Ditzel. Los “servidores x86 manejan buenas cantidades de memoria y tienen recuperación previa, y las CPU de propósito general manejan muy bien esa carga de trabajo. Ha sido difícil para cualquier acelerador entrar en el negocio de las recomendaciones por eso ".
También se requiere soporte para INT8 junto con los tipos de datos FP16 y FP32. El requisito de las matemáticas de punto flotante se deriva tanto de la necesidad de mantener la mayor precisión de predicción posible como de la falta de inclinación a portar o reescribir programas para matemáticas de menor precisión. Ditzel dijo que los principales fabricantes de chips de servidor x86 recientemente agregaron extensiones vectoriales de 8 bits a las CPU de los servidores.
“La mayor parte de la inferencia que se realiza en [un centro de datos de hiperescala] en sus millones de servidores x86 sigue siendo flotante de 32 bits”, dijo.
El chip de esperanto en una tarjeta dual M.2 está diseñado para encajar en las ranuras del acelerador dentro de la infraestructura de servidor de CPU x86 existente. Eso da como resultado un límite de potencia de 120 W, que requiere refrigeración por aire.
Ditzel dijo que el diseño de Esperanto no compite directamente con esfuerzos internos como las TPU de Google o Inferentia de Amazon Web Services. Los hiperescaladores “están tratando de que toda la comunidad construya chips aceleradores para ellos. Muchas de estas empresas creen en la informática abierta y el [Open Compute Project] ". Por lo tanto, “compran servidores OCP y les gustaría incorporar material estandarizado. Si hay competencia, les encanta ... están tratando de fomentar la competencia y mostrarle a la gente lo que es posible ".
Aún así, la startup insiste en que los operadores de grandes centros de datos necesitan proveedores externos para chips aceleradores. "Sigue siendo siempre una decisión de hacer frente a comprar". Por ejemplo, un cliente de esperanto no tenía acceso a chips desarrollados internamente que utilizaba otra división. "Si superas lo que tienen, la entrada en cualquiera de estas empresas es posible".
Nuevo enfoque
El esperanto ha adoptado el enfoque opuesto a los aceleradores de chips gigantes de la competencia, que ofrecen un chip de menor potencia que se puede utilizar en múltiples. El enfoque aborda los requisitos de ancho de banda de la memoria, ya que se pueden usar más pines para E / S de memoria sin tener que recurrir al costoso HBM.
El hardware del esperanto también está diseñado como una computadora de uso general; a pesar del enfoque en los modelos de recomendación, el chip puede acelerar el procesamiento paralelo, según Ditzel. Una tarjeta aceleradora de seis chips incluye aproximadamente 6.000 núcleos paralelos, y cada núcleo puede ejecutar dos subprocesos, que pueden "solucionarse cualquier problema arbitrario".
Otro truco bajo la manga del esperanto es un diseño agresivo de eficiencia energética. Los requisitos del cliente establecieron el presupuesto de energía en 120 W en total, mientras que el espacio máximo establecido en una tarjeta Glacier Point era de seis chips, o 20 W por chip. En comparación, los aceleradores de inferencia de IA operan a más de diez veces esa cantidad.
El esperanto abordó el tema desde varios ángulos. La frecuencia del reloj se redujo a un nivel óptimo de aproximadamente 1 GHz. La tensión de alimentación se redujo a alrededor de 0,4 V, más allá del límite de las SRAM. La capacitancia de conmutación se ayudó mediante el uso de núcleos RISC-V ajustados con el conjunto de instrucciones más pequeño comercialmente viable para reducir la cantidad de transistores. Se eligió una tecnología de proceso avanzada pero estable, TSMC 7nm.
haga clic para ver la imagen a tamaño completo
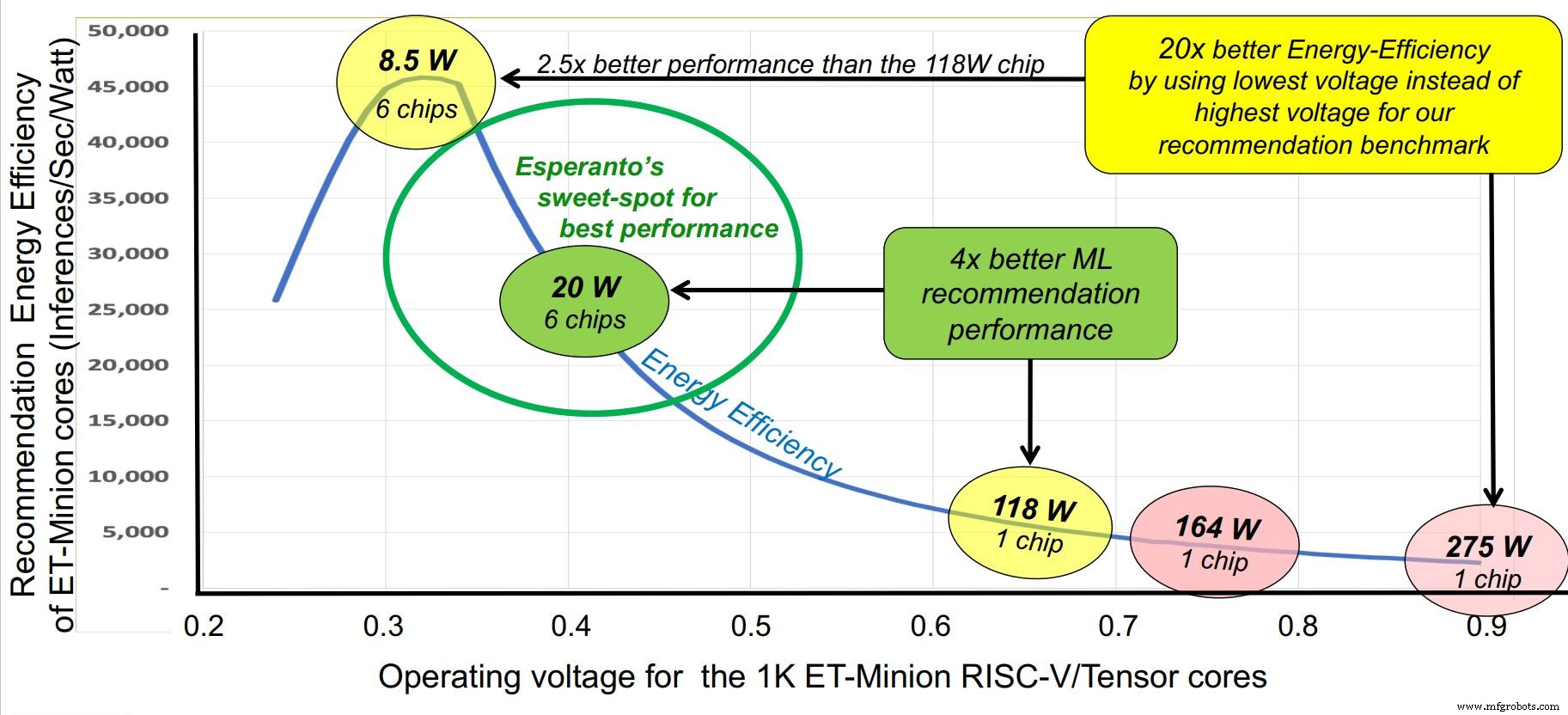
Esperanto identificó un "punto óptimo" para la operación en alrededor de 1 GHz. (Fuente:Esperanto)
Diseño básico
El chip de Esperanto incluye 1.088 núcleos ET-Minion, que procesan la carga de trabajo de la IA. Los núcleos son procesadores RISC-V en orden de 64 bits con la propia unidad de tensor y vector optimizada para IA de Esperanto que ocupa gran parte del espacio del chip. Los MAC de coma flotante dominan la configuración. Inusualmente, los MAC enteros tienen el doble del ancho de procesamiento del punto flotante (según los requisitos del cliente, señaló Ditzel). También son compatibles las instrucciones trascendentales vectoriales, como las funciones sigmoides, comunes en los modelos de aprendizaje profundo. Dado que los núcleos se ejecutan en un único dominio de bajo voltaje, se utilizaron más transistores con SRAM en la pequeña caché L1 para garantizar un rendimiento sólido.
haga clic para ver la imagen a tamaño completo
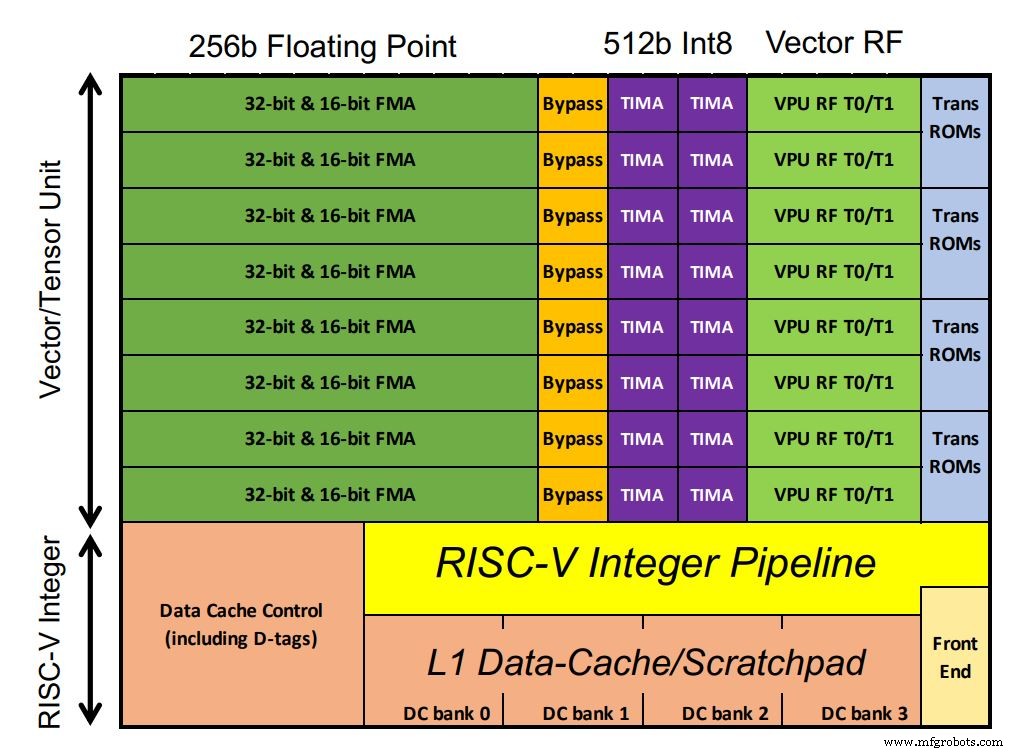
El chip de esperanto contiene 1.088 núcleos ET-Minion (haz clic en la imagen para ampliarla) (Fuente:Esperanto)
Cada núcleo es capaz de 128 GOPS por GHz. Una instrucción tensorial de ciclos múltiples personalizada realiza grandes multiplicaciones de matrices con un controlador separado que se hace cargo y ejecuta hasta 512 ciclos utilizando el ancho completo de 512 bits. Esto permite que la instrucción de un solo tensor realice más de 64.000 operaciones aritméticas antes de que el controlador obtenga la siguiente instrucción RISC-V. Eso reduce el ancho de banda de la instrucción, ya que la mayor parte de la carga de trabajo utiliza la instrucción tensorial. Por lo tanto, solo se requiere una instrucción por 512 ciclos de reloj.
Ocho núcleos ET-Minion constituyen un "vecindario" y las instrucciones modificadas aprovechan su proximidad física. Otra característica llamada "cargas cooperativas" permite que los núcleos transfieran datos directamente entre sí sin una búsqueda de caché. Esa configuración ahorra energía. Los ocho núcleos también comparten una gran caché L2 para la eficiencia energética.
Al alejarnos de nuevo, cuatro vecindarios de 8 núcleos forman una “Comarca Minion”, con 34 comarcas en cada chip, lo que suma un total de 1.088 núcleos. (También es posible realizar cálculos con solo 1.024 núcleos para mejorar el rendimiento, dijo Ditzel). Cuatro núcleos ET-Maxion, cada uno con un rendimiento aproximadamente comparable a un Arm A-72, están pensados para una operación independiente futura, en lugar de la configuración actual del acelerador.
La variación de voltaje de umbral se mitiga proporcionando a cada Shire su propio suministro de voltaje para que los voltajes individuales puedan ajustarse con precisión.
Sistema de memoria
Cada chip tiene cuatro interfaces DDR de 64 bits; de hecho, cada interfaz representa cuatro canales de 16 bits, para un total de 96 canales de 16 bits. El diseño utiliza LPDDR4x desarrollado como memoria de bajo consumo para teléfonos inteligentes. La energía por bit es aproximadamente equivalente a HBM, pero mantener el total en 1536 bits en la interfaz de memoria para la tarjeta aceleradora de seis chips produce un mayor ancho de banda de memoria total.
El esperanto montó sus chips en tarjetas M.2 de doble zócalo; seis caben en una tarjeta aceleradora OCP Glacier Point v2 (tres en el frente, tres en la parte posterior). Eso ofrece alrededor de 800 TOPS con los chips funcionando a 1 GHz. También se pueden montar en tarjetas PCIe de perfil bajo (media altura, media longitud) que aumentan el presupuesto de energía de cada chip a alrededor de 60 W. Los chips pueden funcionar entre 300 MHz y 2 GHz, según la aplicación.
Según los resultados de la emulación de hardware, Ditzel afirmó que seis chips de esperanto en una tarjeta Glacier Point pueden superar a sus competidores. La ventaja de la puesta en marcha es pronunciada para los puntos de referencia de recomendación cuando se consideran el diseño del sistema de memoria y las cifras de rendimiento por vatio, una consecuencia del enfoque en un diseño de bajo voltaje.
Las versiones futuras podrían incluir una versión reducida de ET-SoC-1 para aplicaciones de borde. Ditzel dijo que la versión actual debería lanzarse en "los próximos meses".
>> Este artículo se publicó originalmente en nuestro sitio hermano, EE. Tiempos.
Contenidos relacionados:
- Los SoC habilitados para IA manejan múltiples transmisiones de video
- Xilinx apunta a la descarga del centro de datos con hardware "componible"
- Computación de conjunto de operaciones reducido (ROSC) para cobertura funcional NNA
- La arquitectura híbrida acelera la IA y las cargas de trabajo de visión
- Los aceleradores de hardware sirven aplicaciones de inteligencia artificial
Para obtener más información sobre Embedded, suscríbase al boletín informativo semanal por correo electrónico de Embedded.
Incrustado
- Revólver
- Una perspectiva brillante para EDA en la nube
- Cumbre RISC-V:aspectos destacados de la agenda
- Arm habilita instrucciones personalizadas para núcleos Cortex-M
- Cuando un DSP supera a un acelerador de hardware
- Diseñar con Bluetooth Mesh:¿Chip o módulo?
- La arquitectura del chip AI apunta al procesamiento de gráficos
- El pequeño módulo Bluetooth 5.0 integra una antena de chip
- Los investigadores crean una pequeña etiqueta de identificación de autenticación
- Se estrena el procesador de radar de imágenes automotrices de 30 fps
- El chip de radar de baja potencia utiliza redes neuronales con picos