


Cómo entrenar una red neuronal de perceptrón multicapa
Podemos mejorar enormemente el rendimiento de un Perceptron agregando una capa de nodos ocultos, pero esos nodos ocultos también hacen que el entrenamiento sea un poco más complicado.
Hasta ahora, en la serie AAC sobre redes neuronales, aprendió sobre la clasificación de datos utilizando redes neuronales, especialmente de la variedad Perceptron.
Póngase al día con la serie a continuación o sumérjase en esta nueva entrada que explicará los conceptos básicos de la red neuronal multicapa Perceptron (MLP).
- Cómo realizar la clasificación mediante una red neuronal:¿Qué es el perceptrón?
- Cómo utilizar un ejemplo de red neuronal de Perceptron simple para clasificar datos
- Cómo entrenar una red neuronal de perceptrón básica
- Comprensión del entrenamiento de redes neuronales simples
- Introducción a la teoría del entrenamiento para redes neuronales
- Comprensión de la tasa de aprendizaje en redes neuronales
- Aprendizaje automático avanzado con el perceptrón multicapa
- La función de activación sigmoidea:activación en redes neuronales de perceptrones multicapa
- Cómo entrenar una red neuronal de perceptrón multicapa
- Comprender las fórmulas de entrenamiento y la retropropagación para perceptrones multicapa
- Arquitectura de red neuronal para una implementación de Python
- Cómo crear una red neuronal de perceptrón multicapa en Python
- Procesamiento de señales mediante redes neuronales:validación en el diseño de redes neuronales
- Conjuntos de datos de entrenamiento para redes neuronales:cómo entrenar y validar una red neuronal Python
¿Qué es una red neuronal de perceptrón multicapa?
El artículo anterior demostró que un Perceptron de una sola capa simplemente no puede producir el tipo de rendimiento que esperamos de una arquitectura de red neuronal moderna. Un sistema que está limitado a funciones linealmente separables no podrá aproximarse a las complejas relaciones entrada-salida que ocurren en escenarios de procesamiento de señales de la vida real. La solución es un perceptrón multicapa (MLP), como este:
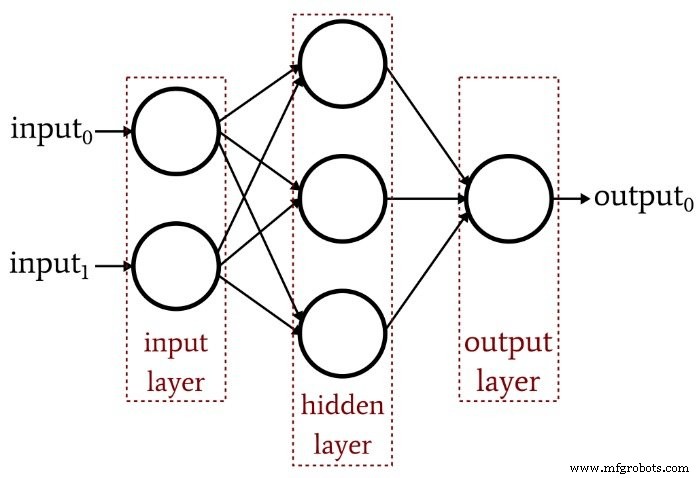
Al agregar esa capa oculta, convertimos la red en un "aproximador universal" que puede lograr una clasificación extremadamente sofisticada. Pero siempre debemos recordar que el valor de una red neuronal depende completamente de la calidad de su entrenamiento. Sin datos de entrenamiento abundantes y diversos y un procedimiento de entrenamiento efectivo, la red nunca "aprenderá" cómo clasificar las muestras de entrada.
¿Por qué la capa oculta complica el entrenamiento?
Veamos la regla de aprendizaje que usamos para entrenar un perceptrón de una sola capa en un artículo anterior:
\ [w_ {new} =w + (\ alpha \ times (salida_ {esperada} -salida_ {calculada}) \ veces entrada) \]
Observe la suposición implícita en esta ecuación:Actualizamos los pesos en función de la salida observada, por lo que para que esto funcione, los pesos en el Perceptron de una sola capa deben influir directamente en el valor de salida. Es como elegir la temperatura del agua del grifo girando las dos perillas para caliente y fría. La relación entre la temperatura general y la acción de las perillas es bastante sencilla, e incluso las personas a las que no les gustan las matemáticas pueden encontrar la temperatura del agua deseada jugando con las perillas durante un rato.
Pero ahora imagine que el flujo de agua a través de las tuberías fría y caliente está relacionado con la posición de la perilla de una manera compleja y altamente no lineal. Usted gira lenta y constantemente la perilla de agua caliente, pero el caudal resultante varía de forma errática. Prueba el pomo para agua fría y hace lo mismo. Establecer la temperatura ideal del agua en estas condiciones, especialmente porque la "salida" debe lograrse mediante una combinación de dos relaciones de control confusas, sería mucho más difícil.
Así es como entiendo el dilema de la capa oculta. Las ponderaciones que conectan los nodos de entrada a los nodos ocultos son conceptualmente análogas a esas perillas mecánicamente erráticas, porque las ponderaciones de entrada a oculta no tienen una ruta directa a la capa de salida, la relación entre estas ponderaciones y la salida de la red es tan complejo que la regla de aprendizaje simple que se muestra arriba no será efectiva.
Un nuevo paradigma de formación
Dado que la regla de aprendizaje original de Perceptron no se puede aplicar a redes multicapa, debemos repensar nuestra estrategia de capacitación. Lo que vamos a hacer es incorporar el descenso de gradiente y la minimización de una función de error.
Una cosa a tener en cuenta es que este procedimiento de entrenamiento no es específico de las redes neuronales multicapa. El descenso de gradiente proviene de la teoría de optimización general, y el procedimiento de entrenamiento que empleamos para MLP también es aplicable a redes de una sola capa. Sin embargo, según tengo entendido, el descenso de gradiente al estilo MLP es (al menos teóricamente) innecesario para un Perceptron de una sola capa, porque la regla más simple que se muestra arriba eventualmente hará el trabajo.
Derivar las ecuaciones de actualización de peso reales para un MLP implica algunas matemáticas intimidantes que no intentaré explicar de manera inteligente en este momento. Mi objetivo para el resto de este artículo es proporcionar una introducción conceptual a dos aspectos clave del entrenamiento MLP, el descenso de gradiente y la función de error, y luego continuaremos esta discusión en el próximo artículo incorporando una nueva función de activación.
Descenso en gradiente
Como su nombre lo indica, el descenso de gradiente es un medio de descender hacia el mínimo de una función de error basada en la pendiente. El siguiente diagrama transmite la forma en que un gradiente nos da información sobre cómo modificar pesos:la pendiente de un punto en la función de error nos dice en qué dirección debemos ir y qué tan lejos estamos del mínimo.
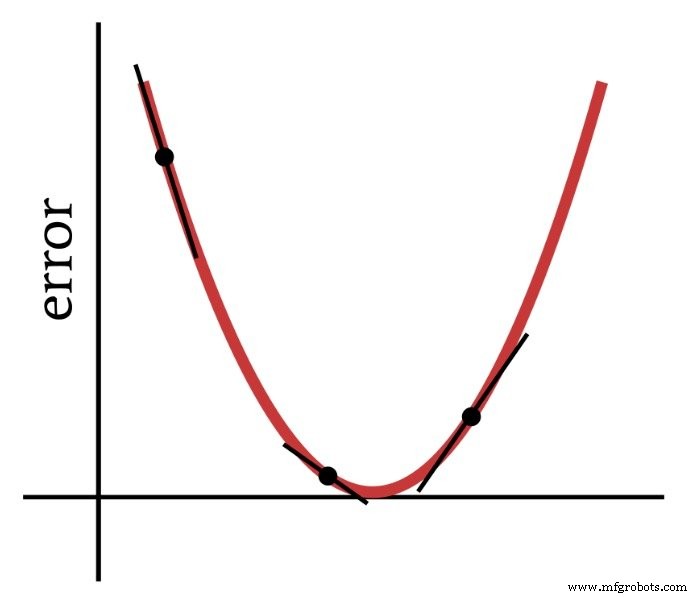
Por lo tanto, la derivada de la función de error es un elemento importante de los cálculos que usamos para entrenar un perceptrón multicapa. De hecho, necesitaremos parcial derivados aquí. Cuando implementamos el descenso de gradiente, hacemos que cada modificación de peso sea proporcional a la pendiente de la función de error con respecto al peso que se está modificando.
La función de error (también conocida como función de pérdida)
Un método común para cuantificar el error de una red neuronal es cuadrar la diferencia entre el valor esperado (o "objetivo") y el valor calculado para cada nodo de salida, y luego sumar todas estas diferencias cuadradas. Puede llamar a esto "suma de diferencia al cuadrado" o "error al cuadrado sumado" o tal vez varias otras cosas, y también verá la abreviatura LMS, que significa cuadrado mínimo medio, porque el objetivo del entrenamiento es minimizar la media error al cuadrado. Esta función de error (indicada por E) se puede expresar matemáticamente de la siguiente manera:
\ [E =\ frac {1} {2} \ sum_k (t_k-o_k) ^ 2 \]
donde k indica el rango de nodos de salida, t es el valor de salida objetivo y o es el valor de salida calculado.
Conclusión
Hemos sentado las bases para entrenar con éxito un perceptrón multicapa y continuaremos explorando este interesante tema en el próximo artículo.
Robot industrial
- Topología de red
- Cómo entrenarse para convertirse en electricista de automóviles
- Cómo reforzar sus dispositivos para prevenir ciberataques
- CEVA:procesador de inteligencia artificial de segunda generación para cargas de trabajo de redes neuronales profundas
- Comprender los mínimos locales en el entrenamiento de redes neuronales
- Cómo el ecosistema de red está cambiando el futuro de la granja
- ¿Qué es una red inteligente y cómo podría ayudar a su empresa?
- ¿Qué es una llave de seguridad de red? ¿Cómo encontrarlo?
- La red neuronal artificial puede mejorar la comunicación inalámbrica
- ¿Qué tan segura es su red de piso de producción?
- ¿Cómo capacita la industria 4.0 a la fuerza laboral del mañana?