


Unión en lenguaje C para empaquetar y desempaquetar datos
Aprenda a empaquetar y desempaquetar datos con uniones en lenguaje C.
Obtenga información sobre cómo empaquetar y desempaquetar datos con uniones en lenguaje C.
En un artículo anterior, discutimos que la aplicación original de uniones había sido la creación de un área de memoria compartida para variables mutuamente excluyentes. Sin embargo, a lo largo del tiempo, los programadores han utilizado ampliamente las uniones para una aplicación completamente diferente:extraer partes más pequeñas de datos de un objeto de datos más grande. En este artículo, veremos esta aplicación particular de los sindicatos con mayor detalle.
Uso de uniones para empaquetar / desempaquetar datos
Los miembros de un sindicato se almacenan en un área de memoria compartida. Esta es la característica clave que nos permite encontrar aplicaciones interesantes para los sindicatos.
Considere la unión a continuación:
unión {uint16_t palabra; struct {uint8_t byte1; uint8_t byte2; };} u1; Hay dos miembros dentro de esta unión:El primer miembro, "palabra", es una variable de dos bytes. El segundo miembro es una estructura de dos variables de un byte. Los dos bytes asignados para la unión se comparten entre sus dos miembros.
El espacio de memoria asignado puede ser como se muestra en la Figura 1 a continuación.
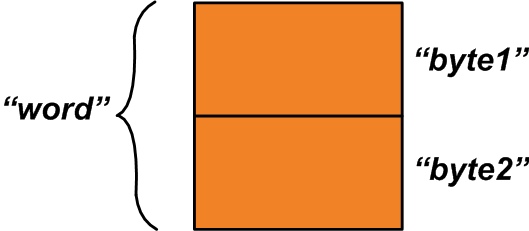
Figura 1
Mientras que la variable "palabra" se refiere a todo el espacio de memoria asignado, las variables "byte1" y "byte2" se refieren a las áreas de un byte que construyen la variable "palabra". ¿Cómo podemos utilizar esta función? Suponga que tiene dos variables de un byte, "x" e "y", que deben combinarse para producir una sola variable de dos bytes.
En este caso, puede usar la unión anterior y asignar "x" e "y" a los miembros de la estructura de la siguiente manera:
u1.byte1 =y; u1.byte2 =x; Ahora, podemos leer el miembro "palabra" de la unión para obtener una variable de dos bytes compuesta por variables "x" e "y" (Ver Figura 2).
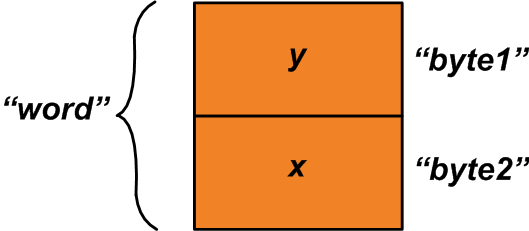
Figura 2
El ejemplo anterior muestra el uso de uniones para empaquetar dos variables de un byte en una sola variable de dos bytes. También podríamos hacer lo contrario:escribir un valor de dos bytes en "palabra" y descomprimirlo en dos variables de un byte leyendo las variables "x" e "y". Escribir un valor para un miembro de un sindicato y leer a otro miembro a veces se denomina "juego de palabras".
Endianness del procesador
Al usar uniones para empaquetar / desempaquetar datos, debemos tener cuidado con la endianidad del procesador. Como se analiza en el artículo de Robert Keim sobre endianidad, este término especifica el orden en el que los bytes de un objeto de datos se almacenan en la memoria. Un procesador puede ser little endian o big endian. Con un procesador big-endian, los datos se almacenan de manera que el byte que contiene el bit más significativo tiene la dirección de memoria más baja. En los sistemas little-endian, el byte que contiene el bit menos significativo se almacena primero.
El ejemplo que se muestra en la Figura 3 ilustra el almacenamiento de little endian y big endian de la secuencia 0x01020304.
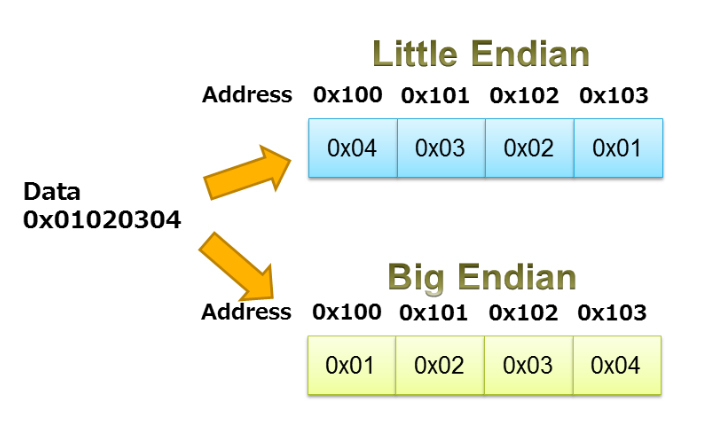
Figura 3. Imagen cortesía de IAR.
Usemos el siguiente código para experimentar con la unión de la sección anterior:
#include <stdio.h > # include <stdint.h >int main () {union {struct {uint8_t byte1; uint8_t byte2; }; uint16_t palabra; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf ("Word es:% # X", u1.word); return 0;} Al ejecutar este código, obtengo el siguiente resultado:
La palabra es:0X4321
Esto muestra que el primer byte del espacio de memoria compartida ("u1.byte1") se utiliza para almacenar el byte menos significativo (0X21) de la variable "palabra". En otras palabras, el procesador que estoy usando para ejecutar el código es little endian.
Como puede ver, esta aplicación particular de uniones puede exhibir un comportamiento dependiente de la implementación. Sin embargo, esto no debería ser un problema serio porque para una codificación de tan bajo nivel, generalmente conocemos el endianness del procesador. En caso de que no conozcamos estos detalles, podemos usar el código anterior para averiguar cómo se organizan los datos en la memoria.
Solución alternativa
En lugar de usar uniones, también podemos usar los operadores bit a bit para realizar el empaquetado o desempaquetado de datos. Por ejemplo, podemos usar el siguiente código para combinar dos variables de un byte, "byte3" y "byte4", y producir una sola variable de dos bytes ("palabra2"):
palabra2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); Comparemos el resultado de estas dos soluciones en los casos de little endian y big endian. Considere el siguiente código:
#include <stdio.h > # include <stdint.h >int main () {union {struct {uint8_t byte1; uint8_t byte2; }; uint16_t palabra1; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf ("Word1 es:% # X \ n", u1.word1); uint8_t byte3, byte4; uint16_t palabra2; byte3 =0x21; byte4 =0x43; palabra2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); printf ("Palabra2 es:% # X \ n", palabra2); return 0;} Si compilamos este código para un procesador big endian como TMS470MF03107 , la salida será:
Word1 es: 0X2143
Word2 es: 0X2143
Sin embargo, si lo compilamos para un pequeño procesador endian como STM32F407IE , la salida será:
Word1 es: 0X4321
Word2 es: 0X2143
Mientras que el método basado en la unión exhibe un comportamiento dependiente del hardware, el método basado en la operación de cambio conduce al mismo resultado independientemente de la endianidad del procesador. Esto se debe al hecho de que, con el último enfoque, estamos asignando un valor al nombre de una variable ("palabra2") y el compilador se encarga de la organización de la memoria empleada por el dispositivo. Sin embargo, con el método basado en la unión, estamos cambiando el valor de los bytes que construyen la variable "palabra1".
Aunque el método basado en unión exhibe un comportamiento dependiente del hardware, tiene la ventaja de ser más legible y fácil de mantener. Es por eso que muchos programadores prefieren usar uniones para esta aplicación.
Un ejemplo práctico de "data Punning"
Cuando trabajamos con protocolos de comunicación en serie comunes, es posible que debamos realizar el empaquetado o desembalaje de datos. Considere un protocolo de comunicación en serie que envía / recibe un byte de datos durante cada secuencia de comunicación. Siempre que estemos trabajando con variables de un byte de longitud, es fácil transferir los datos, pero ¿qué pasa si tenemos una estructura de tamaño arbitrario que debe atravesar el enlace de comunicación? En este caso, tenemos que representar de alguna manera nuestro objeto de datos como una matriz de variables de un byte de largo. Una vez que obtenemos esta representación de matriz de bytes, podemos transferir los bytes a través del enlace de comunicación. Luego, en el extremo del receptor, podemos empaquetarlos apropiadamente y reconstruir la estructura original.
Por ejemplo, suponga que necesitamos enviar una variable flotante, "f1", a través de la comunicación UART. Una variable flotante suele ocupar cuatro bytes. Por lo tanto, podemos usar la siguiente unión como búfer para extraer los cuatro bytes de "f1":
union {float f; struct {uint8_t byte [4]; };} u1; El transmisor escribe la variable "f1" en el miembro flotante de la unión. Luego, lee la matriz de "bytes" y envía los bytes por el enlace de comunicación. El receptor hace lo contrario:escribe los datos recibidos en la matriz de "bytes" de su propia unión y lee la variable flotante de la unión como el valor recibido. Podríamos hacer esta técnica para transferir un objeto de datos de tamaño arbitrario. El siguiente código puede ser una prueba simple para verificar esta técnica.
#include <stdio.h > # include <stdint.h >int main () {float f1 =5.5; buffer de unión {float f; struct {uint8_t byte [4]; }; }; unión búfer buff_Tx; unión búfer buff_Rx; buff_Tx.f =f1; buff_Rx.byte [0] =buff_Tx.byte [0]; buff_Rx.byte [1] =buff_Tx.byte [1]; buff_Rx.byte [2] =buff_Tx .byte [2]; buff_Rx.byte [3] =buff_Tx.byte [3]; printf ("Los datos recibidos son:% f", buff_Rx.f); return 0;} La Figura 4 a continuación visualiza la técnica discutida. Tenga en cuenta que los bytes se transfieren secuencialmente.
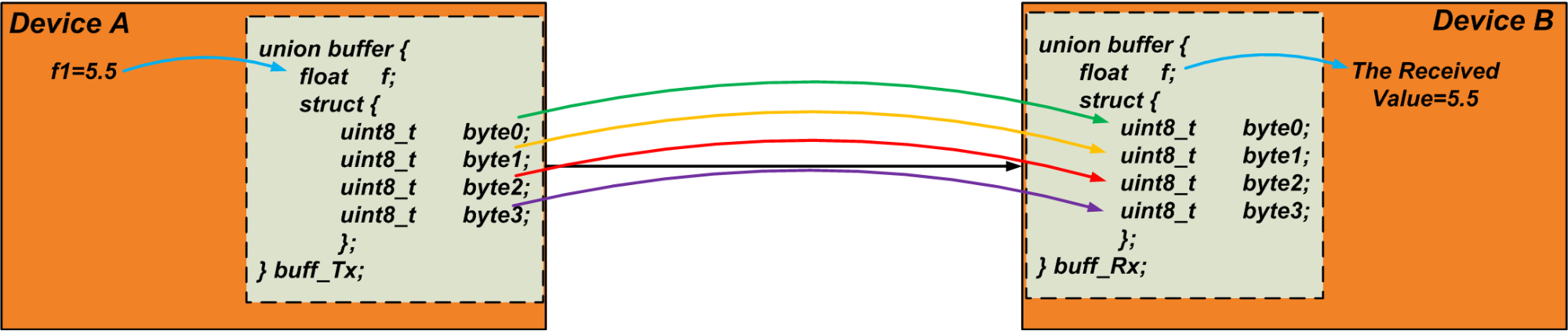
Figura 4
Conclusión
Si bien la aplicación original de las uniones era la creación de un área de memoria compartida para variables mutuamente excluyentes, a lo largo del tiempo, los programadores han utilizado ampliamente las uniones para una aplicación completamente diferente:usar uniones para empaquetar / desempaquetar datos. Esta aplicación particular de los sindicatos implica escribir un valor a un miembro del sindicato y leer a otro miembro del mismo.
El "juego de datos" o el uso de uniones para el empaquetado / desempaquetado de datos puede conducir a un comportamiento dependiente del hardware. Sin embargo, tiene la ventaja de ser más legible y fácil de mantener. Es por eso que muchos programadores prefieren usar uniones para esta aplicación. El "juego de palabras" puede ser particularmente útil cuando tenemos un objeto de datos de tamaño arbitrario que debe pasar por un enlace de comunicación en serie.
Para ver una lista completa de mis artículos, visite esta página.
Incrustado
- Mejorar el rendimiento de las aplicaciones para los usuarios y clientes en CyrusOne
- Semáforos:servicios públicos y estructuras de datos
- Estrategia y soluciones del ejército para el mantenimiento basado en condiciones
- Los beneficios de adaptar IIoT y soluciones de análisis de datos para EHS
- Construyendo una IA responsable y confiable
- ¿Qué es la computación en la niebla y qué significa para IoT?
- C - Uniones
- Por qué los datos y el contexto son esenciales para la visibilidad de la cadena de suministro
- Para la gestión de flotas, IA e IoT son mejores juntos
- AIoT industrial:combinación de inteligencia artificial e IoT para la Industria 4.0
- Litmus y Oden Fuse IIoT Solutions para fabricación inteligente