


Qué tan extensas cadenas de procesamiento de señales hacen que los asistentes de voz "simplemente funcionen"
Los parlantes inteligentes y los dispositivos controlados por voz son cada vez más populares, y los asistentes de voz como Alexa de Amazon y el asistente de Google comprenden cada vez mejor nuestras solicitudes.
Uno de los principales atractivos de este tipo de interfaz es que "simplemente funciona":no hay una interfaz de usuario que aprender y cada vez más podemos hablar con un dispositivo en un lenguaje natural como si fuera una persona y obtener una respuesta útil. Pero para lograr esta capacidad, se está realizando una gran cantidad de procesamiento sofisticado.
En este artículo, analizaremos la arquitectura de las soluciones controladas por voz y analizaremos lo que está sucediendo bajo el capó y el hardware y software necesarios.
Arquitectura y flujo de señales
Si bien hay muchos tipos de dispositivos controlados por voz, los principios básicos y el flujo de señal son similares. Consideremos un altavoz inteligente, como el Echo de Amazon, y observemos los principales subsistemas y módulos de procesamiento de señales involucrados.
La Figura 1 muestra la cadena de señal general en un altavoz inteligente.
haga clic para ampliar la imagen
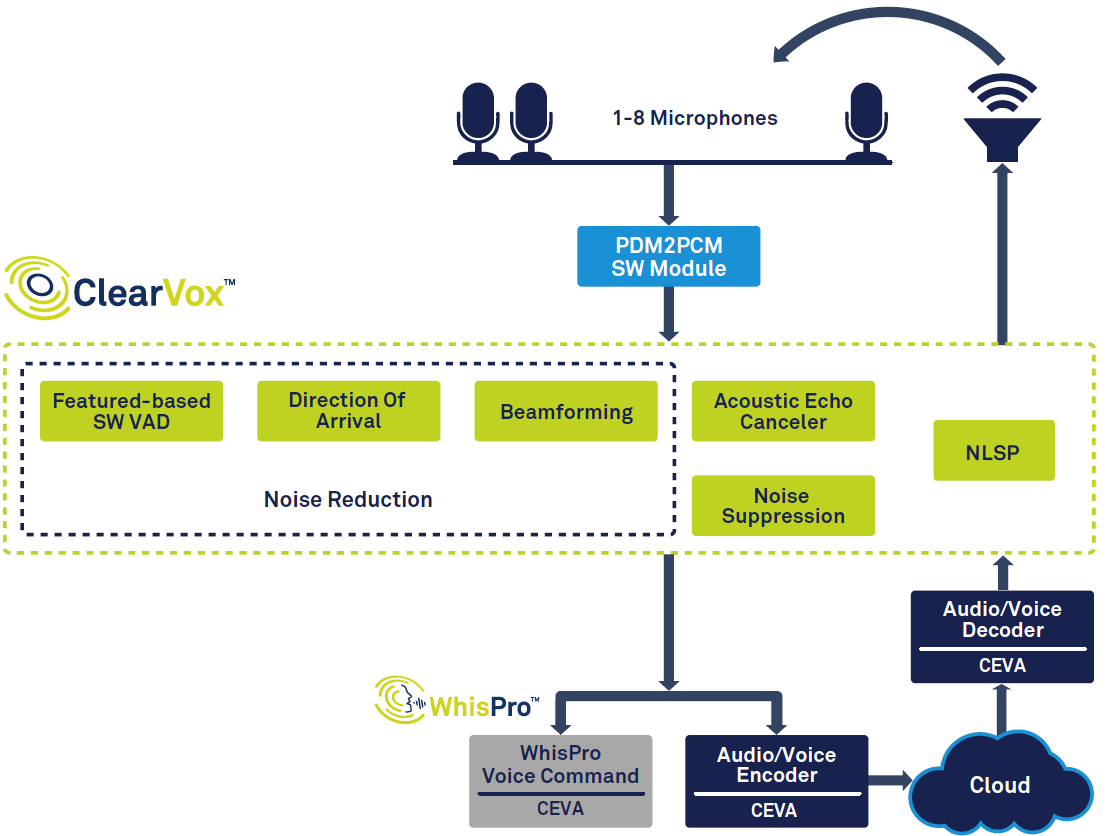
Figura 1:Cadena de señales para el asistente de voz, basada en ClearVox y WhisPro de CEVA. (Fuente:CEVA)
A partir de la izquierda del diagrama, puede ver que, una vez que se detecta una voz mediante la detección de actividad de voz (VAD), se digitaliza y pasa por múltiples etapas de procesamiento de señal para mejorar la claridad de la voz del hablante principal deseado. dirección de llegada. Los datos de voz procesados y digitalizados se pasan luego al procesamiento de voz de back-end, que puede tener lugar en parte en el borde (en el dispositivo) y en parte en la nube. Finalmente, si es necesario, se crea una respuesta y el altavoz la emite, lo que requiere decodificación y conversión de digital a analógico.
Para otras aplicaciones, puede haber algunas diferencias y prioridades variables; por ejemplo, una interfaz de voz en el vehículo debería optimizarse para manejar el ruido de fondo típico en los automóviles. También existe una tendencia general hacia una menor cantidad de energía y costos reducidos, impulsada por la demanda de dispositivos más pequeños, como dispositivos para escuchar en el oído y electrodomésticos de bajo costo.
Procesamiento de señal de front-end
Una vez que se ha detectado y digitalizado una voz, se requieren múltiples tareas de procesamiento de señales. Además del ruido externo, también debemos considerar los sonidos generados por el dispositivo de escucha, por ejemplo, un altavoz inteligente que emite música o una conversación con una persona que habla al otro lado de la línea. Para suprimir estos sonidos, el dispositivo utiliza la cancelación de eco acústico (AEC), por lo que el usuario puede irrumpir e interrumpir un altavoz inteligente, incluso cuando ya está reproduciendo música o hablando. Una vez que se eliminan estos ecos, los algoritmos de supresión de ruido se utilizan para limpiar el ruido externo.
Si bien hay muchas aplicaciones diferentes, podemos generalizarlas en dos grupos para dispositivos controlados por voz:captación de voz de campo cercano y campo lejano. Los dispositivos de campo cercano, como auriculares, audífonos, dispositivos audibles y dispositivos portátiles, se sostienen o usan cerca de la boca del usuario, mientras que los dispositivos de campo lejano, como altavoces inteligentes y televisores, están diseñados para escuchar la voz de un usuario desde el otro lado de la habitación.
Los dispositivos de campo cercano suelen utilizar uno o dos micrófonos, pero los dispositivos de campo lejano suelen utilizar entre tres y ocho. La razón de esto es que el dispositivo de campo lejano enfrenta más desafíos que el de campo cercano:a medida que el usuario se aleja, su voz que llega a los micrófonos se vuelve progresivamente más silenciosa, mientras que el ruido de fondo permanece en el mismo nivel. Al mismo tiempo, el dispositivo también debe separar la señal de voz directa de los reflejos de las paredes y otras superficies, también conocida como reverberación.
Para manejar estos problemas, los dispositivos de campo lejano emplean una técnica llamada formación de haces. Utiliza varios micrófonos y calcula la dirección de la fuente de sonido en función de las diferencias de tiempo entre las señales de sonido que llegan a cada micrófono. Esto permite que el dispositivo ignore los reflejos y otros sonidos, y solo escuche al usuario, así como rastrear su movimiento y acercar la voz correcta cuando haya varias personas hablando.
Para los altavoces inteligentes, otra tarea clave es reconocer la palabra "desencadenante", como "Alexa". Como el hablante siempre está escuchando, este reconocimiento de activación plantea problemas de privacidad:si el audio del usuario siempre se carga en la nube, incluso cuando no dice la palabra de activación, ¿se siente cómodo con que Amazon o Google escuchen todas sus conversaciones? En cambio, puede ser preferible manejar el reconocimiento del disparador, así como muchos comandos populares como "subir volumen" localmente en el altavoz inteligente, y el audio solo se envía a la nube después de que el usuario haya iniciado un comando más complejo.
Finalmente, la muestra de voz limpia debe codificarse antes de enviarse finalmente al back-end de la nube para su procesamiento posterior.
Soluciones especializadas
De la descripción anterior se desprende claramente que el procesamiento de voz de front-end debe poder manejar muchas tareas. Debe hacer esto de manera rápida y precisa, y para los dispositivos que funcionan con baterías, el consumo de energía debe mantenerse al mínimo, incluso cuando el dispositivo siempre está escuchando una palabra de activación.
Para satisfacer estas demandas, es poco probable que los procesadores de señales digitales (DSP) de uso general o los microprocesadores estén a la altura del trabajo, en términos de costo, rendimiento de procesamiento, tamaño y consumo de energía. En cambio, es probable que una mejor solución sea un DSP específico de la aplicación, con funciones de procesamiento de audio dedicadas y software optimizado. La elección de una solución de hardware / software que ya esté optimizada para las tareas de entrada de voz también reducirá los costos de desarrollo y reducirá sustancialmente el tiempo de comercialización, además de reducir los costos generales.
Por ejemplo, ClearVox de CEVA es un paquete de software de algoritmos de procesamiento de entrada de voz, que puede hacer frente a diferentes escenarios acústicos y configuraciones de micrófono, incluida la dirección de llegada de la voz del hablante, formación de haces de varios micrófonos, supresión de ruido y cancelación de eco acústico. ClearVox está optimizado para funcionar de manera eficiente en DSP de sonido CEVA, para proporcionar una solución rentable y de bajo consumo.
Además del procesamiento de voz, el dispositivo de borde necesitará la capacidad de manejar la detección de palabras de activación. Una solución especializada, como WhisPro de CEVA, es una manera excelente de lograr la precisión y el bajo consumo de energía necesarios (consulte la Figura 2). WhisPro es un paquete de software de reconocimiento de voz basado en redes neuronales, disponible exclusivamente para los DSP de CEVA, que permite a los fabricantes de equipos originales agregar activación por voz a sus productos habilitados para voz. Puede manejar la escucha siempre activa requerida, mientras que un procesador principal permanece inactivo hasta que sea necesario, lo que reduce significativamente el consumo de energía general del sistema.
haz clic para ampliar la imagen
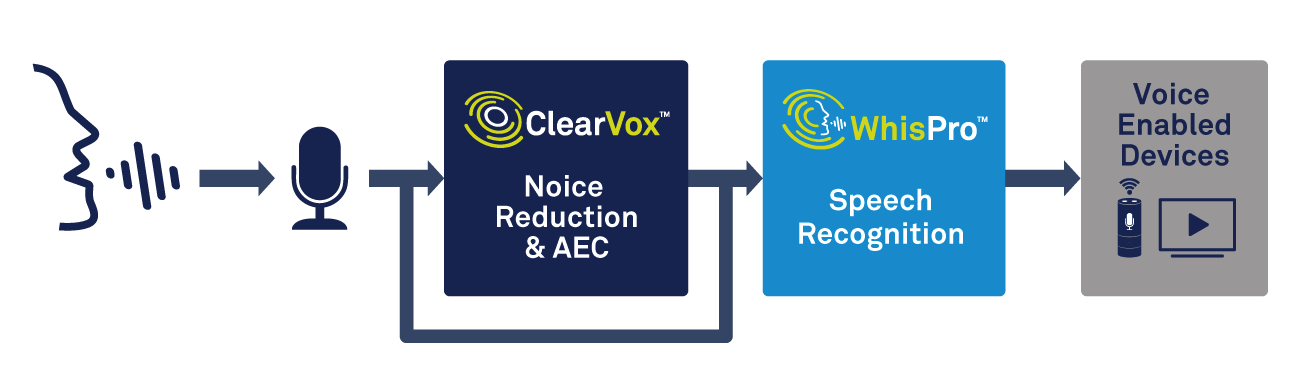
Figura 2:uso de procesamiento de voz y reconocimiento de voz para la activación por voz. (Fuente:CEVA)
WhisPro puede alcanzar una tasa de reconocimiento de más del 95% y puede admitir múltiples frases de activación, así como palabras de activación personalizadas. Como puede testificar cualquiera que haya usado un altavoz inteligente, lograr que responda de manera confiable a la palabra de activación, incluso en un entorno ruidoso, a veces puede ser una experiencia frustrante. Hacer que esta función sea correcta puede marcar una gran diferencia en la forma en que los consumidores perciben la calidad de un producto controlado por voz.
Reconocimiento de voz:local o en la nube
Una vez que la voz ha sido digitalizada y procesada, necesitamos algún tipo de capacidad de reconocimiento automático de voz (ASR). Existe una amplia gama de tecnologías ASR, que van desde la detección de palabras clave simples que requieren que el usuario diga palabras clave específicas, hasta el procesamiento sofisticado del lenguaje natural (NLP), donde un usuario puede hablar normalmente como si se dirigiera a otra persona.
La detección de palabras clave tiene muchos usos, incluso si su vocabulario es extremadamente limitado. Por ejemplo, un dispositivo doméstico inteligente simple, como un interruptor de luz o un termostato, puede responder a unos pocos comandos, como "encendido", "apagado", "más brillante", "atenuador", etc. Este nivel de ASR se puede manejar fácilmente de forma local, en el borde, sin una conexión a Internet, lo que reduce los costos, garantiza una respuesta rápida y evita problemas de seguridad y privacidad.
Otro ejemplo sería que a muchos teléfonos inteligentes Android se les puede decir que tomen una foto diciendo "queso" o "sonrisa", donde enviar el comando a la nube simplemente tomaría demasiado tiempo. Y eso suponiendo que haya una conexión a Internet disponible, lo que no siempre será el caso de un dispositivo como un reloj inteligente o audible.
Por otro lado, muchas aplicaciones requieren PNL. Si desea preguntarle a su altavoz Echo sobre el clima, o para encontrarle un hotel para esta noche, entonces puede formular su pregunta de muchas maneras diferentes. El dispositivo debe poder comprender los posibles matices y coloquialismos en el comando, y resolver de manera confiable lo que se le preguntó. En pocas palabras, debe poder convertir el habla en significado, en lugar de solo hablar en texto.
Para tomar nuestra consulta de hotel como ejemplo, existe una gran variedad de factores posibles sobre los que quizás desee preguntar:precio, ubicación, reseñas y muchos otros. El sistema de PNL tiene que interpretar toda esta complejidad, así como las muchas formas diferentes en que se puede formular una pregunta, y la falta de claridad de la solicitud:decir 'encuéntrame un buen precio, hotel central' significará cosas diferentes para diferentes personas. Para lograr resultados precisos también es necesario que el dispositivo considere el contexto de la pregunta y reconozca cuándo el usuario hace preguntas de seguimiento conectadas o solicita múltiples piezas de información dentro de una consulta.
Esto puede requerir una gran cantidad de procesamiento, generalmente utilizando inteligencia artificial (IA) y redes neuronales, que en su mayoría no es práctico para procesar solo en el borde. Un dispositivo de bajo costo con un procesador integrado no tendrá suficiente energía para realizar las tareas requeridas. En este caso, la opción correcta es enviar el discurso digitalizado para su procesamiento en la nube. Allí, se puede interpretar y enviar una respuesta adecuada al dispositivo controlado por voz.
Puede ver que existen compensaciones entre el procesamiento de borde en el dispositivo y el procesamiento remoto en la nube. Manejar todo localmente puede ser más rápido y no depende de tener una conexión a Internet, pero tendrá dificultades para lidiar con una gama más amplia de preguntas y búsqueda de información. Esto significa que para un dispositivo de uso general, como un altavoz inteligente en el hogar, es necesario enviar al menos parte del procesamiento a la nube.
Para abordar los inconvenientes del procesamiento en la nube, se están realizando desarrollos en las capacidades de los procesadores locales, y en un futuro cercano podemos esperar ver grandes mejoras en NLP e IA en dispositivos de borde. Las nuevas técnicas están reduciendo la cantidad de memoria requerida, y los procesadores continúan siendo más rápidos y consumen menos energía.
Por ejemplo, la familia NeuPro de CEVA de procesadores de inteligencia artificial de bajo consumo proporciona capacidades sofisticadas para el borde. Basándose en la experiencia de CEVA en redes neuronales para visión por computadora, esta familia ofrece una solución flexible y escalable para el procesamiento de voz en el dispositivo.
Conclusiones
Las interfaces controladas por voz se están convirtiendo rápidamente en una parte importante de nuestra vida cotidiana y se agregarán a más y más productos en un futuro próximo. Las mejoras están impulsadas por un mejor procesamiento de señales y capacidades de reconocimiento de voz, así como por recursos informáticos más potentes, tanto a nivel local como en la nube.
Para cumplir con los requisitos de los fabricantes de equipos originales (OEM), los componentes utilizados para el procesamiento de audio y el reconocimiento de voz deben enfrentar algunos desafíos difíciles en términos de rendimiento, costo y potencia. Para muchos diseñadores, las soluciones que se han optimizado específicamente para las tareas en cuestión pueden resultar el mejor enfoque:satisfacer las demandas del cliente final y reducir el tiempo de comercialización.
Cualquiera que sea la tecnología en la que se basen, las interfaces de voz serán más precisas y más fáciles de hablar en el lenguaje cotidiano, mientras que la caída de los costos las hará más atractivas para los fabricantes. Será un viaje interesante para ver exactamente para qué se utilizan a continuación.
Incrustado
- Cómo funcionan las ruedas
- Las tecnologías mejoradas acelerarán la aceptación de los asistentes de voz
- Cómo hacer fibra de vidrio
- Cómo aprovechar al máximo su cadena de suministro ahora mismo
- ¿Cómo funcionan los sistemas SCADA?
- Cómo hacer una brújula usando Arduino y Processing IDE
- Como hacer un prototipo
- ¿Cómo funcionan los secadores de aire?
- Cómo hacer la electrónica del mañana usando grafeno impreso con inyección de tinta
- Cómo funcionan los frenos eléctricos
- Cómo hacer que funcione un programa integral de seguridad