


¿Qué es Hadoop? Procesamiento de macrodatos de Hadoop
La evolución del big data ha producido nuevos desafíos que requerían nuevas soluciones. Como nunca antes en la historia, los servidores necesitan procesar, ordenar y almacenar grandes cantidades de datos en tiempo real.
Este desafío ha llevado al surgimiento de nuevas plataformas, como Apache Hadoop, que puede manejar grandes conjuntos de datos con facilidad.
En este artículo, aprenderá qué es Hadoop, cuáles son sus componentes principales y cómo ayuda Apache Hadoop en el procesamiento de big data.
¿Qué es Hadoop?
La biblioteca de software Apache Hadoop es un marco de código abierto que le permite administrar y procesar de manera eficiente grandes datos en un entorno informático distribuido.
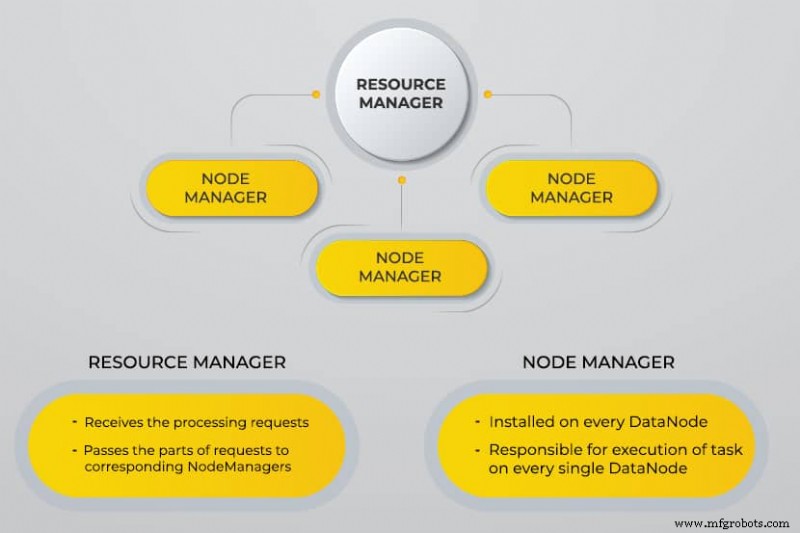
Apache Hadoop consta de cuatro módulos principales :
Sistema de archivos distribuidos de Hadoop (HDFS)
Los datos residen en el sistema de archivos distribuidos de Hadoop, que es similar al de un sistema de archivos local en una computadora típica. HDFS proporciona un mejor rendimiento de datos en comparación con los sistemas de archivos tradicionales.
Además, HDFS proporciona una excelente escalabilidad. Puede escalar desde una sola máquina a miles con facilidad y en hardware básico.
Otro negociador de recursos (YARN)
YARN facilita tareas programadas, administración completa y monitoreo de nodos de clúster y otros recursos.
MapaReducir
El módulo Hadoop MapReduce ayuda a los programas a realizar cálculos de datos en paralelo. La tarea Map de MapReduce convierte los datos de entrada en pares clave-valor. Las tareas de reducción consumen la entrada, la agregan y producen el resultado.
Común de Hadoop
Hadoop Common utiliza bibliotecas Java estándar en todos los módulos.
¿Por qué se desarrolló Hadoop?
La World Wide Web creció exponencialmente durante la última década y ahora consta de miles de millones de páginas. La búsqueda de información en línea se volvió difícil debido a su gran cantidad. Estos datos se convirtieron en big data y consisten en dos problemas principales:
- Dificultad para almacenar todos estos datos de manera eficiente y fácil de recuperar
- Dificultad en el procesamiento de los datos almacenados
Los desarrolladores trabajaron en muchos proyectos de código abierto para obtener resultados de búsqueda web de manera más rápida y eficiente al abordar los problemas anteriores. Su solución fue distribuir datos y cálculos a través de un grupo de servidores para lograr un procesamiento simultáneo.
Eventualmente, Hadoop llegó a ser una solución a estos problemas y trajo muchos otros beneficios, incluida la reducción de los costos de implementación del servidor.
¿Cómo funciona el procesamiento de Big Data de Hadoop?
Con Hadoop, utilizamos la capacidad de almacenamiento y procesamiento de los clústeres e implementamos el procesamiento distribuido para big data. Esencialmente, Hadoop proporciona una base sobre la cual construye otras aplicaciones para procesar big data.
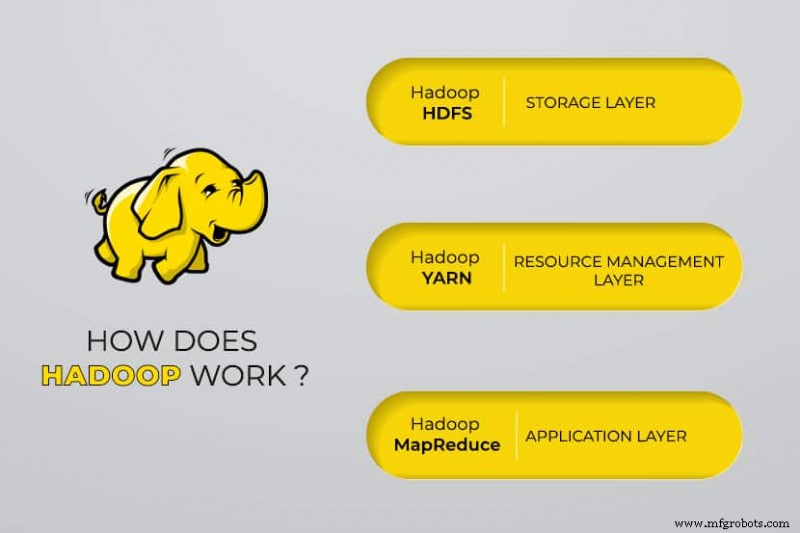
Las aplicaciones que recopilan datos en diferentes formatos los almacenan en el clúster de Hadoop a través de la API de Hadoop, que se conecta a NameNode. El NameNode captura la estructura del directorio de archivos y la ubicación de "fragmentos" para cada archivo creado. Hadoop replica estos fragmentos en DataNodes para el procesamiento paralelo.
MapReduce realiza consultas de datos. Mapea todos los DataNodes y reduce las tareas relacionadas con los datos en HDFS. El nombre, “MapReduce” en sí describe lo que hace. Las tareas de asignación se ejecutan en cada nodo para los archivos de entrada proporcionados, mientras que los reductores se ejecutan para vincular los datos y organizar la salida final.
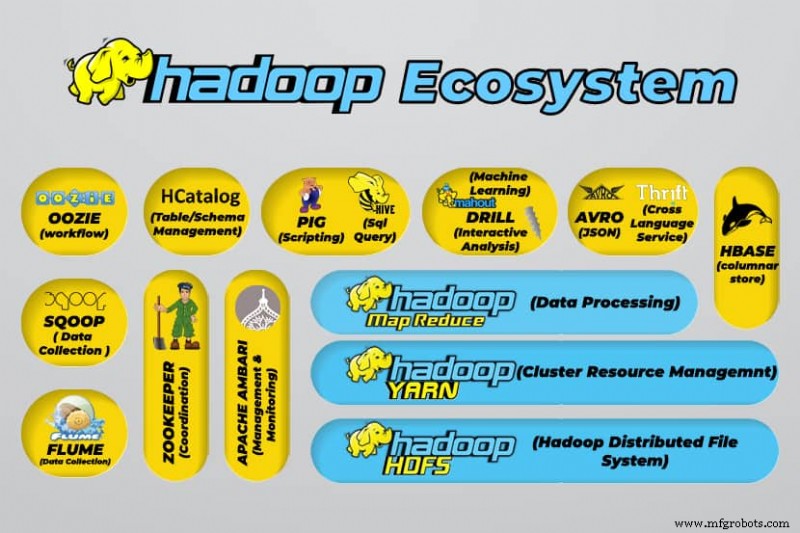
Herramientas de macrodatos de Hadoop
El ecosistema de Hadoop admite una variedad de herramientas de big data de código abierto. Estas herramientas complementan los componentes principales de Hadoop y mejoran su capacidad para procesar big data.
Las herramientas de procesamiento de big data más útiles incluyen:
- Colmena Apache
Apache Hive es un almacén de datos para procesar grandes conjuntos de datos almacenados en el sistema de archivos de Hadoop.
- Guardián Apache
Apache Zookeeper automatiza las conmutaciones por error y reduce el impacto de un NameNode fallido.
- Apache HBase
Apache HBase es una base de datos sin relaciones de código abierto para Hadoop.
- Canal Apache
Apache Flume es un servicio distribuido para transmitir grandes cantidades de datos de registro.
- Apache Sqoop
Apache Sqoop es una herramienta de línea de comandos para migrar datos entre Hadoop y bases de datos relacionales.
- Cerdo Apache
Apache Pig es la plataforma de desarrollo de Apache para desarrollar trabajos que se ejecutan en Hadoop. El idioma del software en uso es Pig Latin.
- Apache Oozie
Apache Oozie es un sistema de programación que facilita la gestión de trabajos de Hadoop.
- Catálogo H de Apache
Apache HCatalog es una herramienta de almacenamiento y administración de tablas para clasificar datos de diferentes herramientas de procesamiento de datos.
Ventajas de Hadoop
Hadoop es una solución robusta para el procesamiento de big data y es una herramienta esencial para las empresas que manejan big data.
Las principales características y ventajas de Hadoop se detallan a continuación:
- Almacenamiento y procesamiento más rápidos de grandes cantidades de datos
La cantidad de datos a almacenar aumentó drásticamente con la llegada de las redes sociales y el Internet de las cosas (IoT). El almacenamiento y el procesamiento de estos conjuntos de datos son fundamentales para las empresas que los poseen. - Flexibilidad
La flexibilidad de Hadoop le permite guardar tipos de datos no estructurados, como texto, símbolos, imágenes y videos. En bases de datos relacionales tradicionales como RDBMS, deberá procesar los datos antes de almacenarlos. Sin embargo, con Hadoop, el procesamiento previo de los datos no es necesario, ya que puede almacenarlos tal como están y decidir cómo procesarlos más adelante. En otras palabras, se comporta como una base de datos NoSQL. - Potencia de procesamiento
Hadoop procesa big data a través de un modelo de computación distribuida. Su uso eficiente de la potencia de procesamiento lo hace rápido y eficiente. - Coste reducido
Muchos equipos abandonaron sus proyectos antes de la llegada de frameworks como Hadoop, debido a los altos costos en los que incurrían. Hadoop es un marco de código abierto, es de uso gratuito y utiliza hardware básico económico para almacenar datos. - Escalabilidad
Hadoop le permite escalar rápidamente su sistema sin mucha administración, simplemente cambiando la cantidad de nodos en un clúster. - Tolerancia a errores
Una de las muchas ventajas de usar un modelo de datos distribuidos es su capacidad para tolerar fallas. Hadoop no depende del hardware para mantener la disponibilidad. Si un dispositivo falla, el sistema redirige automáticamente la tarea a otro dispositivo. La tolerancia a errores es posible porque los datos redundantes se mantienen guardando varias copias de datos en todo el clúster. En otras palabras, se mantiene una alta disponibilidad en la capa de software.
Los tres casos de uso principales
Procesamiento de grandes datos
Recomendamos Hadoop para grandes cantidades de datos, generalmente en el rango de petabytes o más. Es más adecuado para cantidades masivas de datos que requieren una enorme potencia de procesamiento. Es posible que Hadoop no sea la mejor opción para una organización que procesa pequeñas cantidades de datos en el rango de varios cientos de gigabytes.
Almacenamiento de un conjunto diverso de datos
Una de las muchas ventajas de usar Hadoop es que es flexible y admite varios tipos de datos. Independientemente de si los datos consisten en texto, imágenes o datos de video, Hadoop puede almacenarlos de manera eficiente. Las organizaciones pueden elegir cómo procesan los datos según sus requisitos. Hadoop tiene las características de un lago de datos ya que brinda flexibilidad sobre los datos almacenados.
Procesamiento de datos en paralelo
El algoritmo MapReduce utilizado en Hadoop organiza el procesamiento paralelo de los datos almacenados, lo que significa que puede ejecutar varias tareas simultáneamente. Sin embargo, las operaciones conjuntas no están permitidas ya que confunde la metodología estándar en Hadoop. Incorpora paralelismo siempre que los datos sean independientes entre sí.
Para qué se utiliza Hadoop en el mundo real
Empresas de todo el mundo utilizan los sistemas de procesamiento de big data de Hadoop. A continuación se enumeran algunos de los muchos usos prácticos de Hadoop:
- Comprensión de los requisitos del cliente
En la actualidad, Hadoop ha demostrado ser muy útil para comprender los requisitos de los clientes. Las principales empresas de la industria financiera y las redes sociales utilizan esta tecnología para comprender los requisitos de los clientes mediante el análisis de grandes datos sobre su actividad.
Las empresas utilizan esos datos para ofrecer ofertas personalizadas a los clientes. Es posible que haya experimentado esto a través de anuncios que se muestran en las redes sociales y sitios de comercio electrónico en función de nuestros intereses y actividad en Internet. - Optimización de procesos de negocio
Hadoop ayuda a optimizar el rendimiento de las empresas al analizar mejor sus transacciones y datos de clientes. El análisis de tendencias y el análisis predictivo pueden ayudar a las empresas a personalizar sus productos y existencias para aumentar las ventas. Tal análisis facilitará una mejor toma de decisiones y conducirá a mayores ganancias.
Además, las empresas usan Hadoop para mejorar su entorno de trabajo al monitorear el comportamiento de los empleados mediante la recopilación de datos sobre sus interacciones entre ellos. - Mejorar los servicios de salud
Las instituciones de la industria médica pueden usar Hadoop para monitorear la gran cantidad de datos sobre problemas de salud y resultados de tratamientos médicos. Los investigadores pueden analizar estos datos para identificar problemas de salud, predecir medicamentos y decidir sobre planes de tratamiento. Tales mejoras permitirán a los países mejorar sus servicios de salud rápidamente. - Comercio financiero
Hadoop posee un algoritmo sofisticado para escanear datos de mercado con configuraciones predefinidas para identificar oportunidades comerciales y tendencias estacionales. Las empresas financieras pueden automatizar la mayoría de estas operaciones a través de las sólidas capacidades de Hadoop. - Uso de Hadoop para IoT
Los dispositivos IoT dependen de la disponibilidad de datos para funcionar de manera eficiente. Los fabricantes e inventores utilizan Hadoop como almacén de datos para miles de millones de transacciones. Como IoT es un concepto de transmisión de datos, Hadoop es una solución adecuada y práctica para administrar la gran cantidad de datos que abarca.
Hadoop se actualiza continuamente, lo que nos permite mejorar las instrucciones utilizadas con las plataformas IoT.
Otros usos prácticos de Hadoop incluyen mejorar el rendimiento del dispositivo, mejorar la cuantificación personal y la optimización del rendimiento, mejorar los deportes y la investigación científica.
¿Cuáles son los desafíos de usar Hadoop?
Cada aplicación viene con ventajas y desafíos. Hadoop también presenta varios desafíos:
- El algoritmo MapReduce no siempre es la solución
El algoritmo MapReduce no admite todos los escenarios. Es adecuado para solicitudes de información simples y problemas que se fragmentan en unidades independientes, pero no para tareas iterativas.
MapReduce es ineficiente para la informática analítica avanzada, ya que los algoritmos iterativos requieren una intercomunicación intensiva y crea varios archivos en la fase de MapReduce. - Gestión de datos completamente desarrollada
Hadoop no proporciona herramientas integrales para la gestión de datos, metadatos y gobierno de datos. Además, carece de las herramientas necesarias para la estandarización de datos y la determinación de la calidad. - Brecha de talento
Debido a la pronunciada curva de aprendizaje de Hadoop, puede ser difícil encontrar programadores de nivel de entrada con conocimientos de Java que sean suficientes para ser productivos con MapReduce. Esta intensidad es la razón principal por la que los proveedores están interesados en poner la tecnología de base de datos relacional (SQL) por encima de Hadoop porque es mucho más fácil encontrar programadores con conocimientos sólidos en SQL en lugar de habilidades MapReduce.
La administración de Hadoop es tanto un arte como una ciencia, y requiere un conocimiento de bajo nivel de los sistemas operativos, el hardware y la configuración del kernel de Hadoop. - Seguridad de datos
El protocolo de autenticación Kerberos es un paso importante para hacer que los entornos de Hadoop sean seguros. La seguridad de los datos es fundamental para proteger los grandes sistemas de datos de los problemas de seguridad de datos fragmentados.
Conclusión
Hadoop es muy efectivo para abordar el procesamiento de big data cuando se implementa de manera efectiva con los pasos necesarios para superar sus desafíos. Es una herramienta versátil para empresas que manejan grandes cantidades de datos.
Una de sus principales ventajas es que puede ejecutarse en cualquier hardware y un clúster de Hadoop puede distribuirse entre miles de servidores. Esta flexibilidad es particularmente importante en entornos de infraestructura como código.
Computación en la nube
- Big Data y Cloud Computing:una combinación perfecta
- ¿Qué es la seguridad en la nube y por qué es necesaria?
- ¿Cuál es la relación entre big data y computación en la nube?
- Uso de Big Data y Cloud Computing en las empresas
- Qué esperar de las plataformas de IoT en 2018
- Mantenimiento predictivo:lo que necesita saber
- ¿Qué es exactamente la RAM DDR5? Funciones y disponibilidad
- ¿Qué es IIoT?
- Big Data vs Inteligencia Artificial
- Creación de grandes datos a partir de pocos datos
- Big Data remodela la industria de servicios públicos