


Profundización en el ciclo de vida de la ciencia de datos
Desde la llegada del big data, la informática moderna ha estado alcanzando nuevas capacidades y puntos de referencia de potencia de procesamiento. Hoy en día, no es raro encontrar aplicaciones que produzcan conjuntos de datos de 100 terabytes o más, lo que se considera big data.
Con volúmenes tan grandes de información a mano, es fácil desorganizarse y perder el tiempo con contenido inútil. Estas son dos razones por las que es muy importante seguir una metodología que aumente la eficacia y la eficiencia de un proyecto de big data.

Figura 1. La ciencia de datos moderna trabaja con conjuntos de datos muy grandes, también conocidos como macrodatos.
El ciclo de vida de la ciencia de datos proporciona un marco que ayuda a definir, recopilar, organizar, evaluar e implementar proyectos de big data. Es un proceso iterativo que consta de una serie de pasos organizados en una secuencia lógica, que facilitan la retroalimentación y la rotación.
¿Cómo se ve la secuencia del ciclo de vida? La respuesta es que no existe un modelo universal único que todos sigan. Muchas empresas que emprenden proyectos de big data adaptan el ciclo de vida de la ciencia de datos a sus procesos comerciales, por lo general, incluyen más pasos. A pesar de esto, todos los muchos modelos y flujos de procesos tienen denominadores comunes. Este artículo utilizará el modelo de proceso CRISP-DM, que es uno de los primeros y más populares modelos de ciclo de vida de ciencia de datos.
El modelo CRISP-DM
CRISP-DM son las siglas de Cross Industry Standard Process for Data Mining. Fue publicado por primera vez en 1999 por ESPRIT, un programa europeo para impulsar la investigación en tecnologías de la información (TI). El modelo CRISP-DM consta de seis pasos o fases que guían el proyecto de big data. Anima a las partes interesadas a pensar en el negocio planteando y respondiendo preguntas importantes sobre el problema.
Repasemos en detalle las seis fases del modelo CRISP-DM.
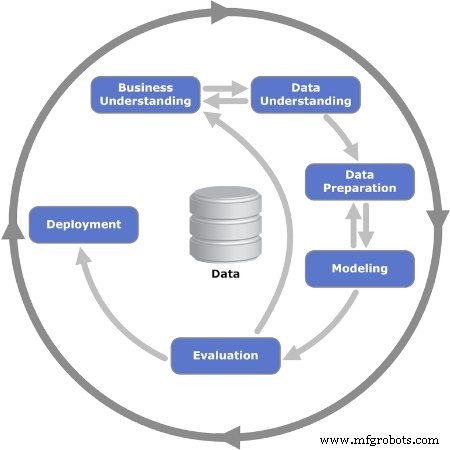
Figura 2. Se muestran las seis fases iterativas del modelo CRISP-DM. Imagen utilizada por cortesía de Kenneth Jensen
Fase 1:Comprensión empresarial
La primera fase consta de varias tareas que definen el problema y establecen metas. Aquí es cuando los objetivos del proyecto se establecen con el enfoque en el negocio o, en otras palabras, el cliente. Normalmente, el equipo reunido para trabajar en un proyecto de big data debe entregar una solución al cliente, que puede ser otra área o departamento dentro de la empresa.
Una vez que se ha establecido la necesidad o el problema empresarial, el siguiente paso es definir los criterios de éxito. Estos pueden ser indicadores clave de rendimiento (KPI) o acuerdos de nivel de servicio (SLA), que proporcionan medios objetivos para evaluar el progreso y la finalización.
A continuación, es necesario analizar la situación empresarial para identificar riesgos, planes de reversión, medidas de contingencia y, lo que es más importante, la disponibilidad de recursos. Se presenta un plan de proyecto, incluidos los recursos de hitos.
Fase 2:comprensión de los datos
Una vez que se han establecido los fundamentos en la fase anterior, es el momento de centrarse en los datos. Esta fase comienza con una definición inicial de qué datos se cree que son necesarios y luego documenta algunos detalles al respecto:dónde encontrarlos, tipo de datos, formato, relaciones entre diferentes campos de datos, etc.
Con la primera documentación lista, el siguiente paso es ejecutar la primera ejecución de recopilación de datos. Esto proporciona una instantánea útil de cómo se está formando la estructura. Luego, se evalúa la calidad de esta instantánea de información.
Fase 3:preparación de datos
La tercera fase refuerza la fase anterior y prepara el conjunto de datos para el modelado. Los campos de datos de la primera colección se curan aún más y cualquier información que se considere innecesaria se elimina del conjunto:esto se denomina limpieza de datos.
Además, es posible que deba derivarse un dato específico de otra información disponible; otras veces, debe combinarse. En otras palabras, los datos deben procesarse para producir un formato final.
Fase 4:modelado
La tarea más importante en esta fase es seleccionar un algoritmo para procesar los datos recopilados. En este contexto, un algoritmo es un conjunto de reglas y pasos de secuencia programados en un software de computadora diseñado para proyectos de big data.
Se pueden usar muchos algoritmos:regresiones lineales, árboles de decisión y máquinas de vectores de soporte son algunos ejemplos. Elegir el algoritmo adecuado para resolver el problema requiere habilidades que los científicos de datos experimentados tienen.
Figura 3. La regresión lineal es un tipo de algoritmo que se utiliza en el modelado de macrodatos.
El siguiente paso es codificar el algoritmo en la aplicación de software. Aquí es también cuando se planea la fase de prueba, que consiste en asignar conjuntos de datos específicos para prueba y validación.
Fase 5:evaluación
A veces, es difícil elegir un algoritmo desde el principio. Cuando esto sucede, los científicos ejecutan varios algoritmos y analizan los resultados para llegar a una decisión final. Una vez que se completa la fase de prueba, los resultados se revisan para verificar que estén completos y sean precisos.
Más importante aún, esta es una oportunidad para evaluar si los resultados conducen a una solución. En el modelo iterativo, esta es una intersección crucial donde se pueden lanzar secuencias de iteración importantes, o se puede llegar a la decisión de avanzar hacia la fase final.
Fase 6:implementación
Esto es cuando el proyecto pasa de un entorno de prueba a un entorno de producción en vivo. La planificación del programa y la estrategia de implementación es muy importante para reducir los riesgos y el posible tiempo de inactividad del sistema.
Aunque el diagrama modelo sugiere que este es el final del proyecto, aún quedan numerosos pasos a seguir después:monitoreo y mantenimiento. El monitoreo es un período de observación cercana, también conocido como hipercuidado, inmediatamente después de la puesta en funcionamiento. El mantenimiento es un proceso semipermanente para mantener y actualizar la solución implementada.
Big data se llama así por una razón:hay una gran cantidad de datos para analizar. La implementación de uno de los modelos del ciclo de vida de la ciencia de datos ayuda a decidir qué información es digna de conservar y usar para procesos como el mantenimiento predictivo.
Tecnología de Internet de las cosas
- Más allá del teléfono inteligente:convertir datos en sonido
- IA subcontratada y aprendizaje profundo en la industria de la salud:¿está en riesgo la privacidad de los datos?
- Mantenimiento en el mundo digital
- Optimización del ciclo de vida de la SIM
- Democratizando el IoT
- Maximización del valor de los datos de IoT
- Poner la ciencia de datos en manos de expertos en el dominio para brindar información más valiosa
- Por qué la conexión directa es la siguiente fase del IoT industrial
- El valor de la medición analógica
- Tableau, los datos detrás de la información
- Preparando el escenario para el éxito de la ciencia de datos industriales