


Si los datos son el aceite nuevo, ¿quién es su refinador?
Para los equipos empresariales, los datos parecen estar en todas partes, esperando ser desbloqueados para impulsar sus objetivos comerciales. Recientemente, nos sentamos con dos de las principales autoridades de IoT de Nokia, Marc Jadoul, director de desarrollo de mercado de IoT, Denny Lee, director de estrategia de análisis, para hablar sobre cómo los datos de su empresa podrían ser el petróleo que lo impulse.
Leer y escribir: Así que esta expresión - "Los datos son el nuevo petróleo" - es algo que he escuchado en conferencias y planteado varias veces. Pero la cuestión es que el aceite podría ser un combustible y también podría ser un lubricante, en su mente, con sus clientes, ¿qué significa eso?
Marc Jadoul: La forma en que lo veo es desde un punto de vista de valor. Si compara el precio de un barril de petróleo crudo con el precio de un barril de combustible para aviones, hay una gran diferencia. Los datos, como el petróleo, pueden y deben pasar por un proceso de refinamiento similar.
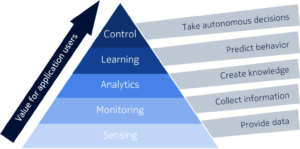
Cuanto más refinado, más valor puede proporcionar porque, al igual que el combustible, admitirá aplicaciones más sofisticadas. Otra forma de pensar en esto es como una pirámide:si está comenzando en la parte inferior de la pirámide, básicamente está recopilando datos sin procesar a nivel de sensor. En la siguiente etapa, comienza a monitorear estos datos y comienza a descubrir qué se incluye en ellos. Probablemente descubrirá algunas anomalías o tendencias y, en función de su análisis, puede descubrir información crítica que lo ayude a crear valor para la empresa que impulsa una mejor toma de decisiones, la denominada toma de decisiones basada en datos (DDDM).
Entonces, si realiza esta toma de decisiones en una especie de fase de aprendizaje basada en el análisis cognitivo, no solo ayudará a tomar decisiones, sino que también predecirá el comportamiento. Una vez que pueda predecir el comportamiento, habrá llegado al punto de los datos más refinados, donde los datos son lo suficientemente puros como para transformarse en conocimiento para ayudar a sus máquinas y aplicaciones a tomar decisiones autónomas.
Lo que he descrito es una cadena de valor en la que los datos brindan información y conocimiento para ayudar a las empresas a tomar mejores decisiones y, en última instancia, automatizar algunos procesos y la toma de decisiones. Estoy haciendo el paralelo con la industria del petróleo, no como una metáfora de la función lubricante ( risas ), pero en comparación con el proceso de refinamiento. Cuanto más lo refines, más útil se vuelve y más valor recuperas.
Denny Lee: Cuando la gente usa la nueva frase del petróleo, siempre pienso en la década de 1970:cuando controlas el petróleo, controlas la economía. Creo que cuando uno dice que "los datos son el nuevo aceite" se basa en esta similitud. Los datos son el nuevo petróleo también significa que si puede tomar ese control, puede controlar mejor esa economía y su sector.
Cuando escucho ese término, también se remonta a la idea de que "los datos son la moneda". Los datos son bastante crudos en su forma y la gente a menudo usa este término de manera bastante vaga. Algunos podrían pensar que los datos, el conocimiento y la inteligencia se refieren a lo mismo. Pero, de hecho, hacemos una gran distinción entre estos. En última instancia, defendemos que los datos son el ingrediente básico y queremos procesar datos que conduzcan a conocimientos. Los conocimientos y la inteligencia son lo que necesita la empresa. Estoy seguro de que hablaremos más adelante sobre cómo utilizar esta inteligencia para fines comerciales procesables.
RW: Entonces, cuando se sienta con un cliente para discutir cómo hacer que visualice una innovación basada en datos dentro de su organización, ¿qué es lo primero que necesita saber, lo primero que debe preguntar?
MJ: Creo que lo primero que deben hacer es comprender su propio negocio y cuáles son los desafíos y problemas que quieren resolver. En lugar de lo contrario, intenta encontrar un problema para su solución. Citando a Simon Sinek, uno debería comenzar con el "¿por qué?" en su lugar con el "¿cómo?" o el "¿qué?" pregunta.
DL: El resultado comercial es definitivamente una cosa, pero antes de eso, debe hacer la pregunta con quién está hablando en la organización. Cada uno tendrá un límite organizacional diferente o un ámbito de responsabilidad que generará un conjunto diferente de preguntas.
Por ejemplo, si está hablando con un CEO, su caja de arena es enorme. Por otro lado, podría estar hablando con una parte aislada de la organización donde su propio universo está muy definido. Luego, debe comprender su contexto comercial y el resultado comercial final deseado. Luego, trabaje al revés y diga "bien, ¿qué tipo de datos tiene realmente?"; e intentas conectar el problema con una solución. Obviamente, cuando hablamos del contexto analítico, se trata de procesar los datos hasta el punto en que puedan impulsar sus resultados comerciales.
Luego, eventualmente, deberíamos hablar sobre cruzar los límites de la organización. Este es un punto muy importante que no debemos perdernos. A veces, las pepitas de la inteligencia solo se obtienen al derribar las barreras entre las organizaciones.
RW: Ha dicho en términos del CEO que tiene una caja de arena más grande en la que trabajar, pero cuando hablo con otras personas que están tratando de implementar una solución basada en datos de algún tipo alrededor de IoT, la idea de quién es el campeón dentro una organización es a menudo el centro de quién sabe realmente que los desafíos están dentro de la organización, ¿hay algo que pueda decir sobre cómo se vería un campeón organizacional típico y cómo orientar esos objetivos en toda la organización?
DL: Bueno, en el contexto de IoT, la organización a menudo se puede dividir en dos ámbitos. El lado de la tecnología de operaciones (OT) y el lado de la tecnología de la información (TI). En el lado de OT, su solución podría estar dirigida a la persona que controla la infraestructura de su empresa. Dependiendo de la persona con la que hable dentro de ese grupo, tendrá diferentes necesidades.
Tomemos como ejemplo al cliente que se centra en el mantenimiento predictivo. En este caso, es posible que solo tenga presupuesto para enfocarse en el mantenimiento y usar big data y aprendizaje automático para respaldar el ciclo de mantenimiento y minimizar las interrupciones de la máquina. Este es un caso de uso muy limitado con un objetivo específico. Pero si habla con su gerente, el alcance y el contexto del problema que están tratando de resolver es mucho más amplio y podría traspasar los límites de la organización
MJ: Realmente me gustaría complementar esta visión con una mirada a una parte diferente de la organización. Además de los líderes que necesitan la analítica para tomar buenas decisiones, veo la importancia del papel del analista de datos emergente en varias organizaciones. Estos expertos saben cómo lidiar con los datos, o usando la metáfora que usamos antes:controlar el proceso de refinamiento. Estamos hablando de un conjunto de habilidades diferente al que tiene la gente de TI tradicional. Mi formación académica es informática y hace 20 años, la base de la educación informática eran las matemáticas. Cuando miré el plan de estudios 5-10 años después, el énfasis se había desplazado hacia algoritmos y lenguajes de programación. Hoy, mi hijo está haciendo su doctorado en IA y, créanme, estos estudiantes deben tener una comprensión muy sólida de las matemáticas y la estadística nuevamente. Y no olvidemos que, dado que los científicos de datos deben respaldar las decisiones comerciales de las empresas, también deben tener un buen nivel de conocimiento del dominio y perspicacia comercial.
RW: Entonces, ¿se ha completado el círculo?
MJ: Con la mayoría de los problemas complejos en los que no puede simplemente usar datos de computadora sin procesar y procesar números para hacer algo con los datos. Realmente necesita el conocimiento del dominio para saber qué es significativo y qué no lo es. Y estas son las personas que lo están logrando en las organizaciones, ya que tienen un rol de apoyo a los tomadores de decisiones internos como lo describió Denny.
RW: Vemos muchas soluciones de IoT orientadas a la enorme cantidad de datos que tiene o podría analizar. Entonces, hasta cierto punto, si tiene ese conocimiento de datos en casa, eso es genial, pero si no lo tiene, ¿existe el riesgo de abrumar a un cliente y ofrecer demasiadas opciones de datos? ¿Realmente necesitan ese talento en casa?
MJ: Depende del tipo de soluciones que desee crear, por supuesto. Y dónde puede filtrar y establecer umbrales en algunos de los datos, por ejemplo, si tiene un sensor de temperatura en una instalación de refrigeración, los únicos datos que realmente desea obtener son las excepciones o anomalías porque si todo es normal allí No es necesario abrumarse con grandes volúmenes de datos normales. Entonces, lo importante es que realice una recopilación de datos inteligente e intente filtrar, analizar previamente y procesar los números lo antes posible. Para iniciar el proceso de refinamiento lo más cerca posible del dispositivo donde se generan los datos.
DL: Permítanme compartir con ustedes una visión de nuestro pensamiento. Esto también se aplica a IoT. En resumen, la forma en que vemos la inteligencia de datos es similar a un cerebro humano. De hecho, estamos impulsando una noción de pila de inteligencia. Si lo piensa en términos de su propio cerebro, hay cosas que tienen un tiempo de respuesta más rápido y son más autónomas. En esta capa, está procesando los datos del entorno pero con un alcance limitado. Ahora dibujemos la similitud con IoT. Las cosas están sucediendo por sí solas y cuando necesita algunos ajustes de retroalimentación, está tomando una decisión local autónoma.
En la siguiente capa, puede haber una acción de tiempo de respuesta moderado y es algo autónoma. Y luego está la capa superior que llamamos inteligencia aumentada. Sirve para ayudar al humano; porque en la capa superior más extrema sigue estando el administrador humano, el ejecutivo humano que realiza cambios de política a más largo plazo. Y esa capa aumentada es la capa superior del software donde descubre información oculta para que el ser humano realice ajustes mejores, diferentes y a más largo plazo.
Entonces, si piensa en estas diferentes capas como parte de una pila, incluso si lo piensa en un contexto de IoT, digamos a nivel de fábrica:cuanto más cerca esté del fondo, estamos hablando en términos de robótica, donde las cosas son automáticas. . Y a medida que sube, es más humano; y el software juega un papel más importante en términos de descubrimiento de conocimientos para que el ser humano pueda emitir mejores juicios.
MJ: Lo interesante es que esto también se refleja a nivel de infraestructura. Probablemente haya oído hablar de la nube perimetral o la computación perimetral de múltiples accesos o MEC, donde en realidad va a realizar parte del procesamiento de datos lo más cerca posible de la fuente. Y es por dos razones:primero, desea reducir la latencia en la red y reducir el tiempo de respuesta para la toma de decisiones. En segundo lugar, no desea trombonizar todas estas cantidades masivas de datos a través del núcleo de su nube. Solo desea que sus usuarios y tomadores de decisiones se ocupen de las cosas realmente útiles. Cuando tengo que explicar la computación en el borde, a veces la describo como CDN inversa (red de entrega de contenido).
Eche un vistazo a lo que hicimos hace años cuando el video a pedido y la transmisión en vivo se hicieron populares. De repente, nos enfrentamos al problema de que es posible que no tengamos suficiente ancho de banda para servir a cada usuario con una transmisión individual y con una posible latencia. Por lo tanto, acercamos los servidores de almacenamiento en caché al usuario final en el que colocaríamos el contenido más popular y podríamos realizar alguna navegación y procesamiento de contenido local, como el avance y retroceso rápido, y la adaptación del contenido. Así que esto fue optimización de recursos informáticos y almacenamiento descendente. Y hoy tenemos varios jugadores en Internet, por ejemplo, Akamai, que están ganando mucho dinero con estos servicios de optimización y almacenamiento en caché.
Ahora, si nos fijamos en Internet de las cosas, el problema no está en términos de la cantidad de datos descendentes como en el video, sino que el desafío está en la cantidad de fuentes de datos y en el volumen de datos ascendentes. Debido a que tiene una gran cantidad de dispositivos de IoT que generan una gran cantidad de registros de datos y lo que realmente va a hacer es instalar algún tipo de servicio de almacenamiento en caché ascendente que esté cerca de la fuente para recopilar los datos, realice análisis de bajo nivel y asegúrese de enviar solo información que tenga sentido más abajo en la nube para su posterior procesamiento y refinamiento, para usar la metáfora de la industria petrolera una vez más. Y, por lo tanto, llamo a la computación perimetral a menudo una especie de "CDN inversa" porque proporciona el mismo tipo de funciones pero utiliza una arquitectura diferente y opera con flujos en una dirección diferente.
RW: Bien, entonces tenemos a alguien que quiere invertir en un proyecto de cualquier tipo, por lo general alguien tiene un ahorro de costos o una nueva fuente de ingresos, supongo, pero creo que la mayoría de las veces no, parece una decisión de ir / no ir. suele estar impulsado por la reducción de costes o la eficiencia, lo que siempre resulta atractivo en la mayoría de las organizaciones. ¿Pueden ambos dar un ejemplo de un proceso impulsado por datos que pueda desbloquear no solo los ahorros de costos sino también la vía de decisión, como un ejemplo para cada uno?
MJ: Podría comenzar con lo que estamos haciendo con nuestra solución de análisis de video. Este es un ejemplo de una aplicación que utiliza volúmenes masivos de datos transmitidos por p. Ej. cámaras de videovigilancia de circuito cerrado.
En las ciudades, tiene cientos o miles de estas cámaras que están creando una gran cantidad de transmisiones de video en vivo. Generalmente, no hay suficiente personal para mirar todas las pantallas simultáneamente, porque sería extremadamente costoso e ineficiente que la gente vea todas estas transmisiones de video las 24 horas del día, los 7 días de la semana. Entonces, lo que hace la solución de Nokia es analizar estos videos y buscar anomalías. Hay muchos ejemplos de casos de uso, como un automóvil que conduce en la dirección incorrecta, una confusión en un aeropuerto, algunas personas u objetos que realizan movimientos inusuales. Lo que realmente estamos haciendo es recopilar estos datos de video y pasarlos por la cadena de refinamiento, procesados a través de una serie de algoritmos que reconocen situaciones específicas y detectan anomalías. Al agregarle capacidades de inteligencia artificial, el sistema se convierte en autoaprendizaje y puede identificar, alertar y predecir cualquier tipo de "suceso" que esté fuera de lo común. Esto ayuda a la toma de decisiones pero, al mismo tiempo, también supone un enorme ahorro de costes porque las ciudades y las empresas de seguridad solo necesitan una fracción de las personas. Las tecnologías analíticas están haciendo posible y asequible este tipo de soluciones de videovigilancia.
RW: Correcto, los ojos humanos no son muy escalables.
MJ: Correcto, los ojos humanos no son muy escalables y probablemente el 99,99% de este contenido de video de CCTV no necesita atención. Por lo tanto, debe aprender a filtrar los datos lo más cerca posible de la fuente y solo continuar trabajando con lo que sea relevante.
DL: Entonces, Trevor, también te daré algunos conjuntos de ejemplos. El primer grupo sería el de acelerar la resolución más rápidamente:como el mantenimiento predictivo, "Siguiente mejor acción", en el ámbito de la atención predictiva para recomendar acciones de flujo de trabajo al agente de atención y el análisis automatizado de la causa raíz. Estos casos de uso de ejemplo se realizaron anteriormente de forma manual. Esperas a que ocurran algunas fallas y luego lo investigas. Con automatización y predicción; en cambio, alguna solución de aprendizaje automático puede predecir la ocurrencia de fallas potenciales con anticipación y puede minimizar las costosas acciones de mantenimiento para solucionar el problema después del hecho.
Otro conjunto de ejemplos se encuentra en la categoría de centrado en el cliente con el uso de inteligencia artificial. Muchos clientes están interesados en este tema porque al final del día reconocen que su competencia también está tratando de apaciguar a sus clientes finales lo mejor que pueden. Y quien pueda hacer eso mejor gana el día. Por lo tanto, apreciar y comprender la experiencia del cliente y poder predecir eso y responder a sus necesidades sería un aspecto importante de la solución de análisis de big data. Por ejemplo, en el contexto de los proveedores y operadores de soluciones de red, sería importante saber de antemano que se producirá una congestión y reaccionar ante ella. Quizás tener un desempeño bien administrado, pero degradado, sea mejor que no tener ningún servicio en determinadas circunstancias. Por lo tanto, adelantarse al problema del enfoque en el cliente también es una forma de aplicación de inteligencia artificial:comprender su experiencia y luego actuar en consecuencia. El tercero, diría yo, son los casos de uso de realidad aumentada que atraen al ejecutivo de nivel superior y a los propietarios de políticas de los operadores de la empresa de IoT.
Otra clase de problemas encajaría en la categoría de "optimización". Si observa un conjunto de resultados comerciales, puede configurar el problema como un problema de optimización:estos son mis entornos aislados, aquí están mis datos sin procesar y mis KPI y eso es lo que quiero optimizar como objetivos. A continuación, el sistema se puede configurar para optimizarlo. Esto está relacionado con el punto en el que uno tiene la oportunidad de romper los silos organizacionales y optimizar ciertos resultados que antes no se podían descubrir cuando las organizaciones están en silos. Este tipo de inteligencia atrae más al ejecutivo y a los propietarios de políticas de las organizaciones.
Este artículo se produjo en asociación con Nokia. Es parte de una serie de artículos en los que el equipo de Nokia brindará asesoramiento experto y profundizará en el análisis de datos, la seguridad y las plataformas de IoT.
Tecnología de Internet de las cosas
- Sea el experto en la nube que su empresa necesita
- Cómo aprovechar al máximo sus datos
- Concepto erróneo n. ° 3:la nube es una forma irresponsable de administrar su negocio
- ¡¿Qué hago con los datos ?!
- La transmisión de datos abre nuevas posibilidades en la era de IoT
- Democratizando el IoT
- Hacer que los datos de IoT funcionen para su empresa
- Es hora de cambiar:una nueva era en el límite
- Amazon quiere los datos de su empresa por lotes ... literalmente
- Maximización del poder del comercio electrónico para hacer crecer su negocio
- El futuro de los centros de datos