


Los investigadores muestran un chip de IA con entrenamiento de precisión reducido
En ISSCC, IBM Research presentó un chip de prueba que representa la manifestación de hardware de sus años de trabajo en algoritmos de inferencia y entrenamiento de IA de baja precisión. El chip de 7 nm admite entrenamiento de 16 y 8 bits, así como inferencia de 4 y 2 bits (el entrenamiento de 32 o 16 bits y la inferencia de 8 bits son el estándar de la industria actual).
Reducir la precisión puede reducir la cantidad de cómputo y potencia requeridos para el cómputo de IA, pero IBM tiene algunos otros trucos arquitectónicos bajo la manga que también ayudan a la eficiencia. El desafío es reducir la precisión sin afectar negativamente el resultado del cálculo, algo en lo que IBM ha estado trabajando durante varios años a nivel de algoritmos.
El Centro de hardware de inteligencia artificial de IBM se creó en 2019 para respaldar el objetivo de la compañía de aumentar el rendimiento de cómputo de inteligencia artificial 2.5 veces por año, con un ambicioso objetivo general de mejorar la eficiencia del rendimiento de 1000 veces (FLOPS / W) para 2029. Los objetivos ambiciosos de rendimiento y potencia son necesarios desde el tamaño de los modelos de IA y la cantidad de computación necesaria para entrenarlos está creciendo rápidamente. Los modelos de procesamiento del lenguaje natural (NLP) en particular ahora son gigantes de un billón de parámetros, y la huella de carbono que acompaña al entrenamiento de estas bestias no ha pasado desapercibida.
Este último chip de prueba de IBM Research muestra el progreso que IBM ha logrado hasta ahora. Para el entrenamiento de 8 bits, el chip de 4 núcleos es capaz de 25,6 TFLOPS, mientras que el rendimiento de inferencia es de 102,4 TOPS para el cálculo de números enteros de 4 bits (estas cifras son para una frecuencia de reloj de 1,6 GHz y una tensión de alimentación de 0,75 V). Reducir la frecuencia del reloj a 1 GHz y el voltaje de suministro a 0,55 V aumenta la eficiencia energética a 3,5 TFLOPS / W (FP8) o 16,5 TOPS / W (INT4).
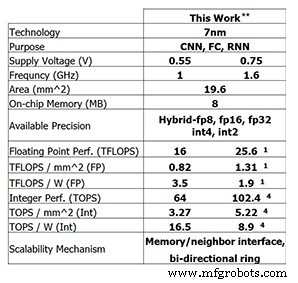
Rendimiento del chip de prueba de IBM Research (Imagen:IBM Research) ** Rendimiento informado con 0% de escasez. (1) FP8. (4) INT4.
Entrenamiento de baja precisión
Este rendimiento se basa en años de trabajo algorítmico en técnicas de inferencia y entrenamiento de baja precisión. El chip es el primero en admitir el formato de punto flotante híbrido especial de 8 bits de IBM (FP8 híbrido) que se presentó por primera vez en NeurIPS 2019. Este nuevo formato ha sido desarrollado especialmente para permitir el entrenamiento de 8 bits, reduciendo a la mitad el cálculo requerido para 16 bits. entrenamiento, sin afectar negativamente los resultados (lea más sobre los formatos numéricos para el procesamiento de IA aquí).
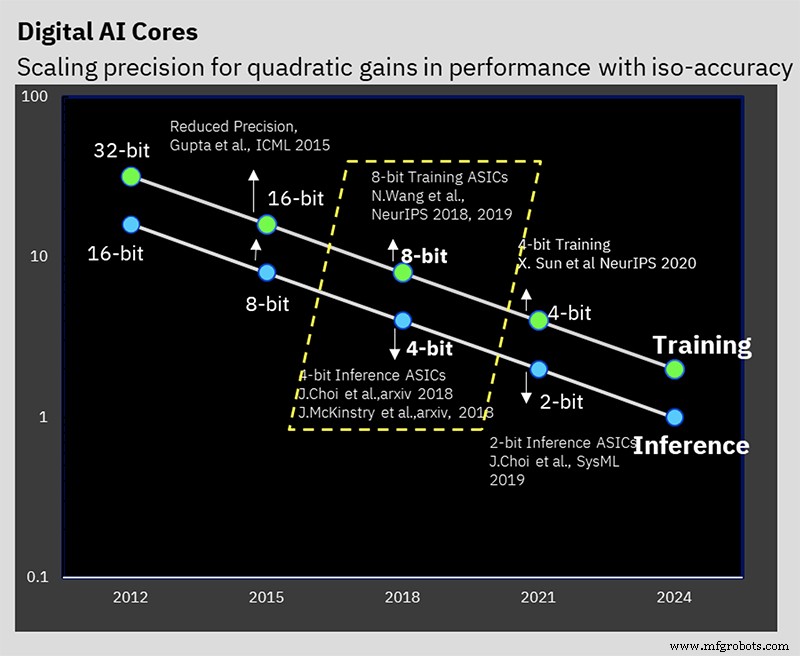
IBM Research ha estado trabajando para resolver el problema de mantener la precisión mientras se reduce la precisión (Imagen:IBM)
"Lo que hemos aprendido en nuestros diversos estudios a lo largo de los años es que la capacitación de baja precisión es muy desafiante, pero puede realizar una capacitación de 8 bits si tiene los formatos numéricos correctos", Kailash Gopalakrishnan, miembro de IBM y gerente senior de arquitecturas de aceleradores y el aprendizaje automático en IBM Research dijeron EE Times . "La comprensión de los formatos numéricos correctos y la puesta en los tensores adecuados en el aprendizaje profundo fue una parte fundamental".
Hybrid FP8 es en realidad una combinación de dos formatos diferentes. Un formato se usa para ponderaciones y activaciones en el pase hacia adelante del aprendizaje profundo, y otro se usa en el pase hacia atrás. La inferencia usa solo el pase hacia adelante, mientras que el entrenamiento requiere fases hacia adelante y hacia atrás.
“Lo que aprendimos es que se necesita más fidelidad, más precisión, en términos de la representación de pesos y activaciones en el paso hacia adelante del aprendizaje profundo”, dijo Gopalakrishnan. “En el otro lado de las cosas [la fase hacia atrás], los gradientes tienen un alto rango dinámico, y ahí es donde reconocemos la necesidad de tener un exponente [más grande] ... este es el compromiso entre cómo algunos tensores en el aprendizaje profundo necesitan más precisión, representación de mayor fidelidad, mientras que otros tensores necesitan un rango dinámico más amplio. Esta es la génesis del formato híbrido FP8 que presentamos a finales de 2019, que ahora se ha traducido en hardware ”.
El trabajo de IBM determinó que la mejor manera de dividir los 8 bits entre el exponente y la mantisa es 1-4-3 (un bit de signo, un exponente de cuatro bits y una mantisa de tres bits) para la fase directa, con una alternativa 5- versión de exponente de bits para la fase hacia atrás, que da un rango dinámico de 2 32 . El hardware híbrido compatible con FP8 está diseñado para admitir ambos formatos.
Acumulación jerárquica
Una innovación que los investigadores denominan "acumulación jerárquica" permite que la acumulación se reduzca en precisión junto con los pesos y las activaciones. Los esquemas de entrenamiento típicos de FP16 se acumulan en aritmética de 32 bits para preservar la precisión, pero el entrenamiento de 8 bits de IBM puede acumularse en FP16. Mantener la acumulación en FP32 habría limitado las ventajas obtenidas de pasar al FP8 en primer lugar.
"Lo que sucede en la aritmética de punto flotante es que si sumas un gran conjunto de números, digamos que es un vector de longitud de 10,000 y lo estás sumando todo, la precisión de la representación de punto flotante en sí misma comienza a limitar la precisión de tu suma ”, explicó Gopalakrishnan. “Llegamos a la conclusión de que la mejor forma de hacerlo es no hacer sumas de forma secuencial, pero tendemos a dividir la acumulación larga en grupos, lo que llamamos fragmentos. Y luego agregamos los fragmentos entre sí, y eso minimiza la probabilidad de tener este tipo de errores ".
Inferencia de baja precisión
La mayoría de las inferencias de IA utilizan el formato entero de 8 bits (INT8) en la actualidad. El trabajo de IBM ha demostrado que el número entero de 4 bits es el estado del arte en términos de cuán baja puede ser la precisión sin perder una precisión de predicción significativa. Después de la cuantificación (el proceso de convertir el modelo a números de menor precisión), se realiza el entrenamiento consciente de la cuantificación. Este es efectivamente un esquema de reentrenamiento que mitiga cualquier error resultante de la cuantificación. Este reentrenamiento puede minimizar la pérdida de precisión; IBM puede cuantificar a aritmética de números enteros de 4 bits "fácilmente" con solo medio porcentaje de pérdida de precisión, lo que Gopalakrishnan dijo que es "muy aceptable" para la mayoría de las aplicaciones.
Anillo en chip
Aparte del enfoque en la aritmética de baja precisión, existen otras innovaciones de hardware que contribuyen a la eficiencia del chip.
Una es la comunicación en anillo en chip, una red en chip optimizada para el aprendizaje profundo que permite que cada uno de los núcleos transmita datos a los demás. La comunicación multidifusión es fundamental para el aprendizaje profundo, ya que los núcleos necesitan compartir pesos y comunicar los resultados a otros núcleos. También permite que los datos cargados desde la memoria fuera del chip se transmitan a varios núcleos. Esto reduce la cantidad de veces que se necesita leer la memoria y la cantidad de datos enviados en general, minimizando el ancho de banda de memoria requerido.
“Nos dimos cuenta de que podíamos hacer funcionar los núcleos más rápido que los anillos, porque los anillos involucran muchos cables largos”, dijo Ankur Agrawal, miembro del personal de investigación en aprendizaje automático y arquitecturas de aceleradores en IBM Research. “Desacoplamos la frecuencia de funcionamiento del anillo de la frecuencia de funcionamiento de los núcleos ... eso nos permite optimizar de forma independiente el rendimiento del anillo con respecto a los núcleos”.
Gestión de energía
Otra de las innovaciones de IBM fue introducir un esquema de escalado de frecuencia para maximizar la eficiencia.
"Las cargas de trabajo de aprendizaje profundo son un poco especiales, porque incluso durante la fase de compilación, sabes qué fases de cálculo vas a encontrar en esta gran carga de trabajo", dijo Agrawal. "Podemos hacer alguna preconfiguración para averiguar cómo se verá el perfil de potencia en diferentes partes del cálculo".
El perfil de poder del aprendizaje profundo generalmente tiene grandes picos (para operaciones con gran cantidad de cómputo como convolución) y valles (quizás para funciones de activación).
El esquema de IBM establece el voltaje y la frecuencia de operación inicial del chip de manera bastante agresiva, de modo que incluso para los modos de potencia más bajos, el chip está casi al límite de su envolvente de potencia. Luego, cuando se requiere más energía, se reduce la frecuencia de operación.
“El resultado neto es un chip que opera casi a la potencia máxima durante todo el cálculo, incluso en las diferentes fases”, explicó Agrawal. “En general, al no tener estas fases de bajo consumo de energía, puede hacer todo más rápido. Ha traducido cualquier caída en el consumo de energía en ganancias de rendimiento al mantener su consumo de energía casi en el consumo máximo de energía para todas las fases de operación ".
La escala de voltaje no se usa porque es más difícil de hacer sobre la marcha; el tiempo necesario para estabilizarse en el nuevo voltaje es demasiado largo para el cálculo de aprendizaje profundo. Por lo tanto, IBM generalmente elige ejecutar el chip al voltaje de suministro más bajo posible para ese nodo de proceso.
Chip de prueba
El chip de prueba de IBM tiene cuatro núcleos, en parte para permitir la prueba de todas las diferentes características. Gopalakrishnan describió cómo el tamaño del núcleo se elige deliberadamente para que sea óptimo; una arquitectura de miles de núcleos diminutos es compleja de conectar entre sí, mientras que dividir el problema entre núcleos grandes también puede ser difícil. Este núcleo intermedio fue diseñado para satisfacer las necesidades de IBM y sus socios en el Centro de hardware de IA, encontrando un punto óptimo en términos de tamaño.
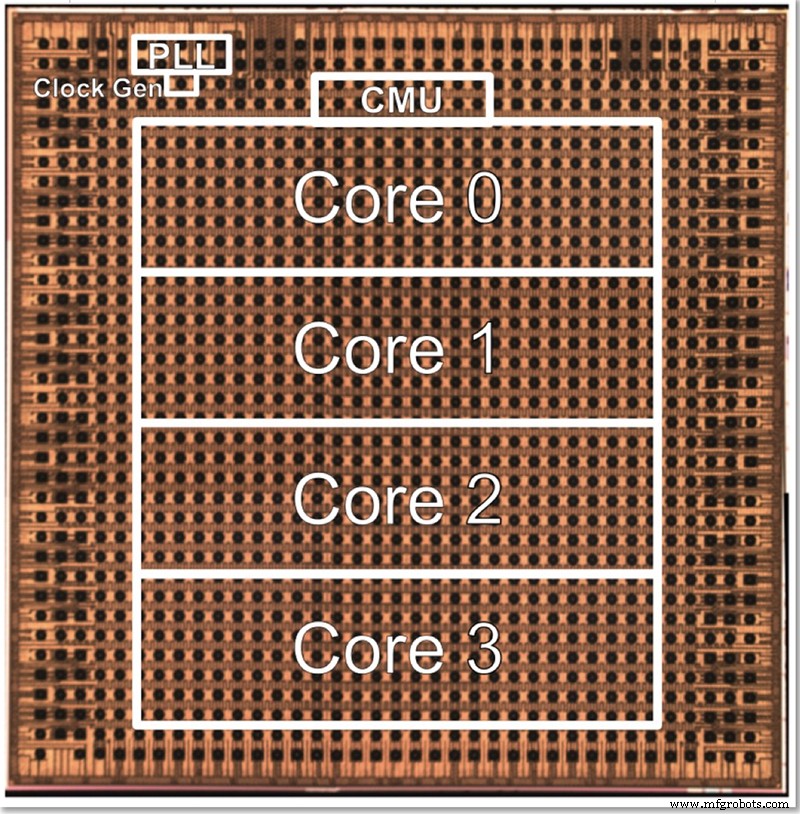
Una foto del chip de prueba de baja precisión de cuatro núcleos de IBM (Imagen:IBM)
La arquitectura se puede escalar hacia arriba o hacia abajo cambiando el número de núcleos. Eventualmente, Gopalakrishnan imagina que los chips de 1-2 núcleos serían adecuados para los dispositivos de borde, mientras que los chips de 32-64 núcleos podrían funcionar en el centro de datos. El hecho de que admita múltiples formatos (FP16, FP8 híbrido, INT4 e INT2) también lo hace lo suficientemente versátil para la mayoría de las aplicaciones, dijo.
"Diferentes dominios [de aplicación] tendrían diferentes requisitos de eficiencia energética y precisión, etc.", dijo. “Nuestra navaja suiza de precisión, cada una de ellas optimizada individualmente, nos permite apuntar a estos núcleos en varios dominios sin renunciar necesariamente a la eficiencia energética en ese proceso”.
Junto con el hardware, IBM Research también ha desarrollado una pila de herramientas ("Deep Tools") cuyo compilador permite una alta utilización del chip (60-90%).
EE Times La entrevista anterior con IBM Research reveló que el entrenamiento de IA de baja precisión y los chips de inferencia basados en esta arquitectura deberían llegar al mercado en unos dos años.
>> Este artículo se publicó originalmente el nuestro sitio hermano, EE Times.
Contenidos relacionados:
- Los chips de IA mantienen la precisión con la reducción del modelo
- Entrenamiento de modelos de IA en el borde
- Ha comenzado la carrera para la IA en el límite
- Edge AI desafía la tecnología de la memoria
- El grupo de ingeniería busca llevar la IA de 1 mW al límite
- Aplicación de redes neuronales para tareas a pequeña escala
- La investigación de AI IC explora arquitecturas alternativas
Para obtener más información sobre Embedded, suscríbase al boletín informativo semanal por correo electrónico de Embedded.
Incrustado
- Diseñar con Bluetooth Mesh:¿Chip o módulo?
- Los investigadores crean una pequeña etiqueta de identificación de autenticación
- Tratar con un personal de mantenimiento reducido
- La alianza de Rockwell con Minnesota College amplía el acceso a la capacitación en automatización
- Los investigadores muestran cómo explotar las fallas de seguridad de Bluetooth Classic
- Cómo IBM Watson impulsa a todos los demás negocios con IA
- Eleve sus esfuerzos de marketing para funcionar con precisión de agencia
- Eleve sus esfuerzos de marketing para funcionar con precisión de agencia
- IBM:Garantía proactiva de confiabilidad y seguridad con EAM
- Creación de sistemas hidráulicos superiores con mecanizado de precisión
- 10 Componentes de Precisión fabricados con Máquinas Herramienta CNC