


Los microcontroladores asumen un papel cada vez mayor en la inteligencia artificial de borde
Hace solo unos años, se asumió que el aprendizaje automático (ML), e incluso el aprendizaje profundo (DL), solo se podía realizar en hardware de gama alta, con entrenamiento e inferencia en el borde ejecutados por puertas de enlace, servidores de borde o datos. centros. Era una suposición válida en ese momento porque la tendencia hacia la distribución de recursos computacionales entre la nube y el borde estaba en sus primeras etapas. Pero este escenario ha cambiado drásticamente gracias a los intensos esfuerzos de investigación y desarrollo realizados por la industria y el mundo académico.
El resultado es que hoy en día, los procesadores capaces de entregar muchos billones de operaciones por segundo (TOPS) no están obligados a realizar ML. En un número cada vez mayor de casos, los microcontroladores más recientes, algunos con aceleradores de ML integrados, pueden llevar ML a los dispositivos periféricos.
Estos dispositivos no solo pueden realizar ML, también pueden hacerlo bien, a bajo costo, con muy bajo consumo de energía, conectándose a la nube solo cuando es absolutamente necesario. En resumen, los microcontroladores con aceleradores ML integrados representan el siguiente paso para llevar la computación a sensores como micrófonos, cámaras y aquellos que monitorean las condiciones ambientales, que generan los datos sobre los cuales se obtienen todos los beneficios de IoT.
¿Qué profundidad tiene el borde?
Si bien el borde se considera en general el punto más lejano en una red de IoT, generalmente se lo considera una puerta de enlace avanzada o un servidor de borde. Sin embargo, ahí no es donde realmente termina la ventaja. Termina en los sensores cercanos al usuario. Se vuelve lógico colocar tanta potencia analítica cerca del usuario como sea posible, una tarea para la que los microcontroladores son ideales.
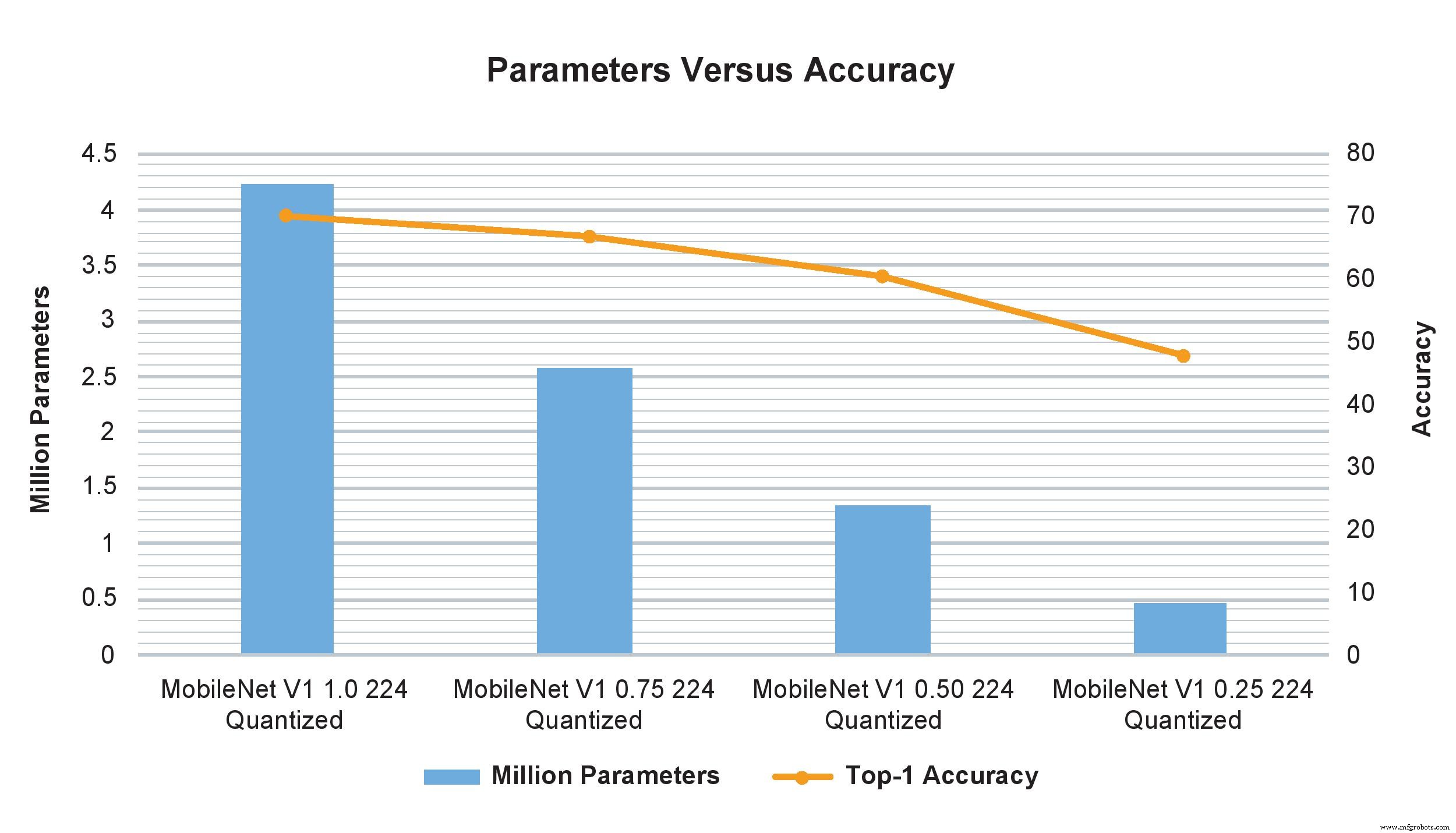
Los ejemplos del modelo MobileNet V1 de multiplicadores de ancho variable muestran un impacto drástico en el número de parámetros, cálculos y precisión. Sin embargo, solo cambiar el multiplicador de ancho de 1.0 a 0.75 afecta mínimamente la precisión de TOP-1 pero impacta significativamente la cantidad de parámetros y cálculos (Imagen:NXP)
Se podría argumentar que las computadoras de placa única también se pueden usar para el procesamiento de borde, ya que son capaces de un rendimiento notable y, cuando están en grupos, pueden rivalizar con una pequeña supercomputadora. Pero todavía son demasiado grandes y costosos para implementarlos en los cientos o miles requeridos en aplicaciones a gran escala. También requieren una fuente externa de alimentación de CC que, en algunos casos, puede estar más allá de lo que está disponible, mientras que una MCU consume solo milivatios y puede funcionar con baterías de tipo botón o incluso con unas pocas células solares.
Por lo tanto, no es sorprendente que el interés en los microcontroladores para realizar ML en el borde se haya convertido en un área de desarrollo muy activa. Incluso tiene un nombre:TinyML. El objetivo de TinyML es permitir que la inferencia y, en última instancia, el entrenamiento, se ejecuten en dispositivos pequeños de baja potencia con recursos limitados, y especialmente en microcontroladores, en lugar de plataformas más grandes o en la nube. Esto requiere que los modelos de redes neuronales se reduzcan en tamaño para adaptarse al procesamiento, almacenamiento y recursos de ancho de banda comparativamente modestos de estos dispositivos, sin reducir significativamente la funcionalidad y la precisión.
Estos esquemas de recursos optimizados permiten que los dispositivos ingieran suficientes datos de sensores para cumplir su propósito mientras ajustan la precisión y reducen los requisitos de recursos. Por lo tanto, si bien los datos aún se pueden enviar a la nube (o quizás primero a una puerta de enlace de borde y luego a la nube), habrá muchos menos porque ya se han realizado un análisis considerable.
Un ejemplo popular de TinyML en acción es un sistema de detección de objetos basado en cámara que, si bien es capaz de capturar imágenes de alta resolución, tiene un almacenamiento limitado y requiere una reducción en la resolución de la imagen. Sin embargo, si la cámara incluye análisis en el dispositivo, solo se capturan los objetos de interés en lugar de la escena completa, y como las imágenes relevantes son menos, se puede retener su resolución más alta. Esta capacidad generalmente se asocia con dispositivos más grandes y potentes, pero la pequeña tecnología ML permite que suceda en microcontroladores.
Pequeño pero poderoso
Aunque TinyML es un paradigma relativamente nuevo, ya está produciendo resultados sorprendentes para la inferencia (incluso con microcontroladores relativamente modestos) y el entrenamiento (en los más potentes) con una mínima pérdida de precisión. Los ejemplos recientes incluyen reconocimiento facial y de voz, comandos de voz y procesamiento del lenguaje natural, e incluso ejecutar varios algoritmos de visión complejos en paralelo.
En términos prácticos, esto significa que un microcontrolador que cueste menos de $ 2 con un núcleo Arm Cortex-M7 de 500 MHz y de 28 Kbytes a 128 Kbytes de memoria puede ofrecer el rendimiento necesario para que los sensores sean realmente inteligentes.
Incluso a este precio y nivel de rendimiento, estos microcontroladores tienen múltiples funciones de seguridad, incluido AES-128, soporte para múltiples tipos de memoria externa, Ethernet, USB y SPI, e incluyen o soporte para varios tipos de sensores, así como Bluetooth, Wi-Fi, SPDIF y I 2 Interfaces de audio C. Gaste un poco más, y el dispositivo generalmente tendrá un Arm Cortex-M7 de 1 GHz, Cortex-M4 de 400 MHz, 2 Mbytes de RAM y aceleración de gráficos. El consumo de energía no suele ser superior a unos pocos miliamperios con un suministro de 3,3 V CC.
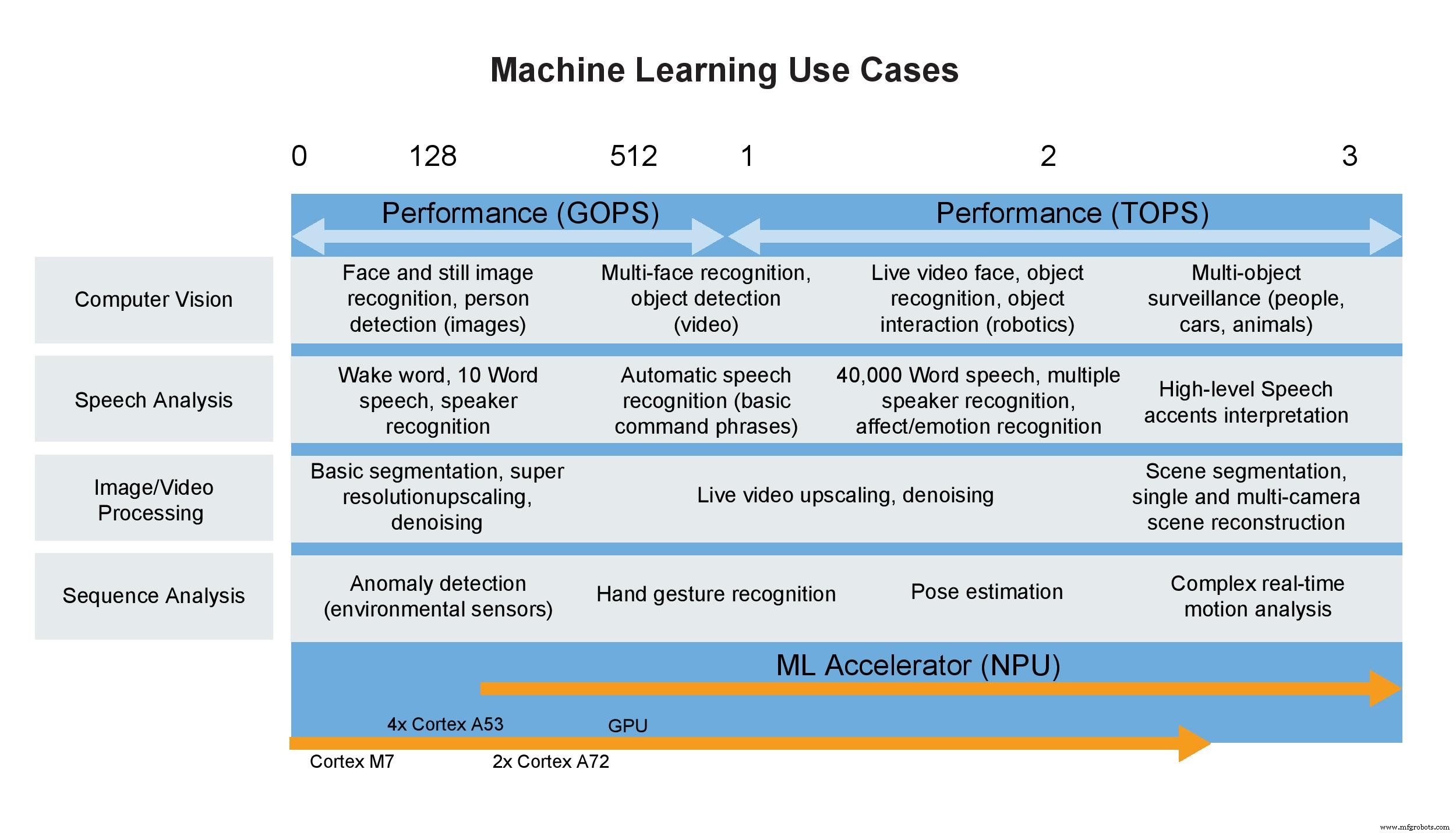
Casos de uso de aprendizaje automático (Imagen:NXP)
Algunas palabras sobre TOPS
Los consumidores no están solos cuando utilizan una única métrica para definir el rendimiento; los diseñadores lo hacen todo el tiempo y a los departamentos de marketing les encanta. Esto se debe a que una especificación de título simplifica la diferenciación entre dispositivos, o eso parece. Un ejemplo clásico es la CPU, que durante muchos años se definió por su frecuencia de reloj. Afortunadamente tanto para los diseñadores como para los consumidores, este ya no es el caso. Usar solo una métrica para calificar una CPU es similar a evaluar el rendimiento de un automóvil según la línea roja del motor. No es insignificante, pero tiene poco que ver con la potencia del motor o el rendimiento del coche, porque muchos otros factores juntos determinan estas características.
Desafortunadamente, lo mismo es cada vez más cierto para los aceleradores de redes neuronales, incluidos aquellos dentro de MPU o microcontroladores de alto rendimiento, que se especifican en miles de millones o billones de operaciones por segundo porque, una vez más, es un número fácil de recordar. Pero en la práctica, GOPS y TOPS por sí solos son métricas relativamente sin sentido y representan una medición (sin duda la mejor) realizada en un laboratorio en lugar de representar un entorno operativo real. Por ejemplo, TOPS no considera las limitaciones del ancho de banda de la memoria, la sobrecarga requerida de la CPU, el pre y posprocesamiento y otros factores. Cuando se consideran todos estos y otros, como el rendimiento cuando se emplea en una placa específica en la operación real, el rendimiento a nivel del sistema probablemente podría ser el 50% o el 60% del valor TOPS en la hoja de datos.
Todos estos números le indican el número de elementos de cálculo en el hardware multiplicado por su velocidad de reloj, en lugar de la frecuencia con la que tendrá los datos disponibles cuando necesite funcionar. Si los datos estuvieran siempre disponibles de inmediato, el consumo de energía no fuera un problema, las restricciones de memoria no existieran y el algoritmo se asignara sin problemas al hardware, serían más significativos. Pero el mundo real no presenta tales entornos ideales.
Cuando se aplica a los aceleradores ML en microcontroladores, la métrica es aún menos valiosa. Estos pequeños dispositivos suelen tener un valor de 1 a 3 TOPS, pero aún pueden ofrecer las capacidades de inferencia necesarias en muchas aplicaciones de aprendizaje automático. Estos dispositivos también se basan en procesadores Arm Cortex diseñados específicamente para aplicaciones ML de bajo consumo. Junto con el soporte para operaciones tanto enteras como flotantes y muchas otras características en el microcontrolador, resulta obvio que TOPS, o cualquier otra métrica individual, es incapaz de definir adecuadamente el desempeño ya sea solo o en un sistema.
Conclusión
El deseo de realizar inferencias en microcontroladores directamente en sensores o conectados a ellos, como cámaras fijas y de video, ahora está surgiendo a medida que el dominio de IoT se acerca a realizar la mayor cantidad de procesamiento posible en el borde. Dicho esto, el ritmo de desarrollo de los procesadores de aplicaciones y los aceleradores de redes neuronales dentro de los microcontroladores es rápido y con frecuencia aparecen soluciones más competentes. La tendencia es consolidar una funcionalidad más centrada en la inteligencia artificial, como el procesamiento de redes neuronales junto con un procesador de aplicaciones en el microcontrolador, sin aumentar drásticamente el consumo de energía o el tamaño.
En la actualidad, los modelos se pueden entrenar en una CPU o GPU más potente y luego implementar en un microcontrolador utilizando motores de inferencia como TensorFlow Lite para reducir su tamaño y cumplir con los requisitos de recursos del microcontrolador. El escalado se puede realizar fácilmente para adaptarse a mayores requisitos de ML. Pronto debería ser posible realizar no solo inferencias sino también entrenamiento en estos dispositivos, lo que hará que el microcontrolador sea un competidor aún más formidable para soluciones informáticas más grandes y caras.
>> Este artículo se publicó originalmente el nuestro sitio hermano, EE Times.
Incrustado
- Papel de la computación en la nube en la inteligencia
- Rol de los sistemas integrados en automóviles
- ¿Dónde está la ventaja en la informática de borde?
- El enfriamiento de la cámara de vapor tiene un papel cada vez más importante en los productos calientes
- La recolección de energía de RF encuentra un papel cada vez mayor en las aplicaciones impulsadas por IA
- USB-C encuentra un papel cada vez mayor en los wearables y los productos móviles
- Pequeño módulo de IA basado en Google Edge TPU
- La placa del sensor inteligente acelera el desarrollo de la IA de borde
- La cámara inteligente ofrece inteligencia artificial de borde de visión artificial de borde llave en mano
- Los robots desempeñan un papel en la Industria 4.0
- El papel de Edge Computing en implementaciones comerciales de IoT