


Interrupción de la nube:¿por qué y cómo ocurre?
Cuanto más dependa TI de los servicios en la nube, más probable es que sufra tiempo de inactividad y pérdidas de ingresos debido a una interrupción de la nube. Más del 60 % de las organizaciones que utilizan la nube pública informan pérdidas en 2022 debido a estos incidentes, por lo que es poco probable que las empresas se enfrenten a las interrupciones.
Pero, ¿las interrupciones son razón suficiente para dejar la nube para siempre? ¿O debería quedarse con este tipo de infraestructura a pesar del riesgo de tiempo de inactividad ocasional?
Este artículo repasa todo lo que necesita saber sobre las interrupciones de la nube . Describimos sus causas principales, examinamos estadísticas reveladoras, mostramos cómo minimizar el impacto del tiempo de inactividad de la nube y observamos las interrupciones más impactantes que ocurrieron en los últimos años.

¿Qué es una interrupción de la nube?
Una interrupción de la nube es un período de tiempo durante el cual los servicios de un proveedor de la nube no están disponibles para los usuarios finales. La infraestructura del proveedor deja de funcionar (debido a un error, falla de energía, etc.) y los clientes pierden el acceso a los activos basados en la nube hasta que el proveedor soluciona el problema.
En cuanto al impacto, no hay diferencia entre la caída de un centro de datos en el sitio y una interrupción de la nube. Pierde el acceso a los activos de TI en ambos casos, pero el enfoque de no intervención para la computación en la nube agrega algunas consideraciones únicas:
- Las interrupciones en la nube tienen poca o ninguna visibilidad de fallas, por lo que los usuarios normalmente no saben qué salió mal.
- El equipo del proveedor es responsable de corregir el error, por lo que los clientes no participan en el proceso de recuperación.
- Dado que no tiene visibilidad ni control sobre el problema, no hay forma de saber cuándo volverán a estar en línea los servicios.
Al igual que con el hardware local, existen dos tipos de posibles interrupciones:
- Planificado (generalmente ocurre debido a un mantenimiento programado).
- No planificado (sucede cuando el proveedor se encuentra con un error inesperado y debe realizar medidas de restauración).
Estudios recientes revelan que las interrupciones no planificadas cuestan un 35 % más que el tiempo de inactividad planificado (tanto en las instalaciones como en la nube). La diferencia de precio existe porque los incidentes inesperados tardan más en identificarse y solucionarse, y cuanto más dura una interrupción, mayor es el daño.
En comparación con el hardware in situ, la infraestructura basada en la nube genera tiempos de inactividad más frecuentes pero con menos gravedad. . Dado que ningún sistema de alojamiento proporciona un tiempo de actividad del 100 %, los clientes están dispuestos a tolerar interrupciones ocasionales a cambio de las ventajas de la computación en la nube. Esta voluntad también es evidente en el crecimiento del mercado:la nube representará el 14,2 % del gasto global total en TI en 2024 (frente al 9,1 % en 2020).
Causas de interrupción de la nube
Las interrupciones de la nube son el resultado de una serie de causas tanto dentro como fuera del control del proveedor. Aquí hay una lista de los más comunes:
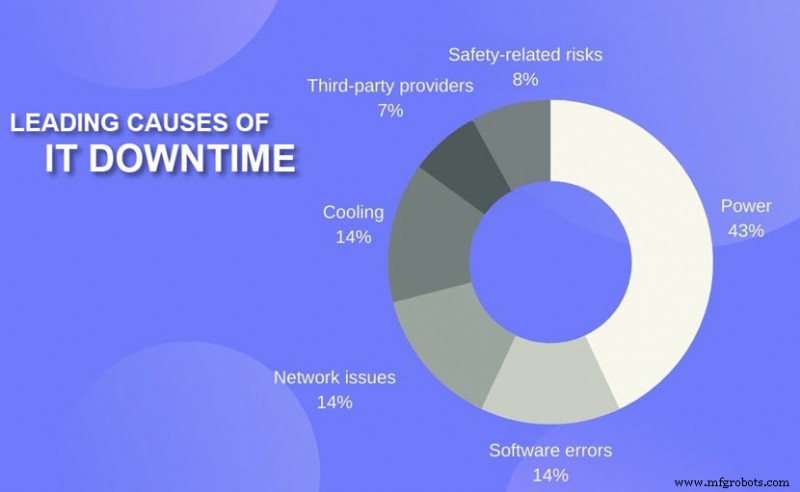
- Corte de energía: Los problemas relacionados con la energía causan el 43 % de todas las interrupciones de la nube con un tiempo de inactividad significativo y pérdidas financieras. Las fallas del sistema de alimentación ininterrumpida (UPS) son la principal causa de incidentes de energía.
- Ciberseguridad: Los ataques cibernéticos como la denegación de servicio distribuida (DDoS) sobrecargan los centros de datos con tráfico entrante. En ese caso, los usuarios finales no pueden acceder al servicio a través de la misma infraestructura de red. Otras amenazas (como el ransomware o una inyección SQL) pueden obligar al proveedor a cerrar los servicios y solucionar el problema sin conexión.
- Error humano: Un solo comando incorrecto o un error con el cableado puede hacer caer toda la infraestructura de TI. Los errores humanos causan problemas tanto físicos como de software que provocan interrupciones.
- Problemas técnicos: Los servicios en la nube se basan en un sistema complejo de tecnología de hardware, por lo que un error que logra pasar desapercibido el tiempo suficiente puede provocar una interrupción de la nube.
- Errores de software: Las fallas y los errores son comunes en los centros de datos en la nube. Los culpables habituales detrás de los problemas son errores de formato de datos, errores relacionados con fallas, errores de tiempo y errores de valor constante.
- Problemas de red: Los problemas asociados con la comunicación de la red y los socios de telecomunicaciones de terceros son otra causa común de las interrupciones de la nube.
- Mantenimiento: El mantenimiento programado y las actualizaciones del sistema a veces provocan una interrupción del servicio, aunque los usuarios finales generalmente conocen estas situaciones con anticipación.
- Causas ambientales: Eventos como huracanes, incendios, tormentas eléctricas y terremotos también desencadenan el tiempo de inactividad de la nube, ya sea poniendo en peligro la instalación o dañando la red eléctrica de la región.
- Despliegues más complejos: Los modelos de implementación más complejos (como híbridos, distribuidos y multinube) complican las operaciones del centro de datos, lo que genera más oportunidades de errores.
¿Qué sucede cuando la nube se cae?
En el mejor de los casos, una interrupción de la nube dura solo unos minutos y afecta a una pequeña cantidad de usuarios o servicios. En el peor de los casos, una interrupción paraliza el negocio de un cliente durante medio día o más. Una empresa pierde el acceso a todos los activos basados en la nube y permanece desconectada hasta que finaliza la interrupción.
Aunque amenazantes, los errores de los proveedores externos fueron la causa de "solo" el 7 % de las interrupciones graves en 2021 . Una interrupción grave debe incluir uno (o varios) de los siguientes:
- Pérdidas financieras significativas.
- Daño reputacional.
- Infracciones de cumplimiento.
- Pérdida de vida.
Si bien existen preocupaciones más apremiantes (como se muestra en el gráfico de anillos a continuación), recuerde que un minuto promedio de tiempo de inactividad cuesta $ 5,600 (esta cifra por minuto asciende a $9,000 para empresas). Si no está preparado (es decir, no tiene copias de seguridad de datos, recuperación ante desastres, etc.), una interrupción de la nube podría detener su servicio y causar impactos masivos en el resultado final.
Una empresa que mantiene un pequeño segmento de operaciones en la nube es menos vulnerable a las interrupciones. Por ejemplo, si solo aloja correos electrónicos en la nube, incluso una interrupción de un día no es catastrófica. Puede esperar el incidente o ejecutar aplicaciones con funcionalidad reducida, una estrategia que no funciona si usa la nube para ejecutar una plataforma IoT o realizar el procesamiento de pagos.
En algunos casos, la interrupción de la nube conduce a la pérdida permanente de datos (la cantidad de datos perdidos depende de la frecuencia de las copias de seguridad). Además, los clientes en industrias estrictas son responsables de multas legales si una interrupción conduce a una violación o fuga de datos, así que tenga cuidado al decidir qué guardar en el almacenamiento en la nube.
¿Qué pueden hacer los usuarios?
Esto es lo que hacen las empresas para mitigar el impacto de las interrupciones de la nube:
- Eliminar puntos únicos de error: Prepare una copia de seguridad de cada componente de TI de misión crítica, ya sea en una sala de servidores en el sitio o en un proveedor secundario. Si la nube deja de funcionar, realiza una conmutación por error (el proceso de cambiar a un servidor en espera, un componente de hardware, una red, etc.) para garantizar la continuidad del negocio.
- Tenga un plan de contingencia: Un plan de recuperación ante desastres describe una estrategia paso a paso para lo que hace el equipo en caso de una interrupción. Este plan proporciona instrucciones para proteger los datos, realizar la conmutación por error, garantizar la continuidad del negocio y restaurar las operaciones. La planificación oportuna para una interrupción de la nube evita perder tiempo evaluando el mejor curso de acción durante el tiempo de inactividad.
- Invierta en un SLA de mayor disponibilidad: Si sus tareas críticas para el negocio no pueden permitirse largas interrupciones en la nube, busque un Acuerdo de nivel de servicio (SLA) de mayor disponibilidad, como el que garantiza un tiempo de actividad del 99,999 % (máximo de 5,25 minutos de tiempo de inactividad por año). Estos contratos son más caros, pero mantener sus servicios en línea se convierte en una prioridad más grande para el proveedor de la nube.
- Realice copias de seguridad periódicas de los datos: Una copia de seguridad garantiza que su equipo tenga una forma de restaurar una versión reciente de los archivos si una interrupción de la nube corrompe o elimina una base de datos. Idealmente, las copias de seguridad deberían realizarse automáticamente y en cualquier lugar entre una vez por hora y una vez por día (dependiendo de la misión crítica).
- Detectar interrupciones lo antes posible: Cualquier capacidad adicional de monitoreo en la nube que configure su equipo ayuda a identificar una interrupción en tiempo real en lugar de esperar la notificación del proveedor. Aquí hay una lista de las mejores herramientas de monitoreo en la nube para mejorar la detección del tiempo de inactividad y garantizar una conmutación por error oportuna.
Las mayores interrupciones recientes en la nube
Las interrupciones de la nube son inevitables cuando se usa la nube, e incluso los proveedores más populares (como Azure, AWS y Google Cloud) no son inmunes al tiempo de inactividad. Veamos algunas de las interrupciones en la nube más importantes de la historia reciente.
Apagón de Azure (octubre de 2021)
En octubre de 2021, Microsoft Azure sufrió una interrupción que desactivó los servicios de máquinas virtuales durante seis horas. . Mientras duró la interrupción, muchos usuarios no pudieron implementar nuevas máquinas virtuales o actualizar extensiones. Las operaciones básicas de administración de servicios (como iniciar, crear y eliminar) también generaron errores.
La causa de la interrupción de la nube fue la incapacidad de las consultas de VM para recuperar los datos de la versión requerida de un artefacto. Un informe posterior a la recuperación reveló que el error basado en el software ocurrió cuando Microsoft migró una de sus arquitecturas de VM.
Interrupción de Google Cloud (noviembre de 2021)
Google Cloud dejó de funcionar durante unas dos horas a mediados de noviembre del año pasado, afectando a empresas como:
- Home Depot.
- Snapchat.
- Etsy.
- Discordia.
- Spotify.
Los sitios web afectados mostraban errores 404 cuando los visitantes intentaban acceder a ellos. Google informó que la causa de la interrupción de la nube fue una falla en una configuración de red responsable del equilibrio de carga.
Interrupción de AWS (diciembre de 2021)
Un gran aumento de la actividad de conexión abrumó los dispositivos de red en una de las instalaciones emblemáticas de AWS, lo que afectó a varios sitios web y aplicaciones. Algunas de las "víctimas" más notables fueron:
- Sitio web de Amazon.
- Primer vídeo.
- Netflix.
- IMDb.
- Red de PlayStation.
El problema del centro de datos causó una latencia severa dentro de las redes internas de AWS. Las aplicaciones de los clientes sintieron el efecto dominó, sufriendo retrasos en el tráfico o cierres totales durante unas siete horas. .
Dos interrupciones posteriores de IBM (enero de 2022)
Un problema con la infraestructura de IBM afectó los servicios en la nube en la región de Dallas durante más de cinco horas. . El equipo interno resolvió el problema, pero accidentalmente provocó un problema adicional de una hora con la nube privada virtual. El problema secundario afectó a usuarios de todo el mundo, incluidos EE. UU., Japón, Canadá y Alemania.
Interrupción de AWS/Slack (febrero de 2022)
Slack sufrió una interrupción de sus recursos en la nube de AWS en febrero que impidió el uso normal de la plataforma de comunicación durante cinco horas. . Más de 11 000 usuarios denunciados no pudieron:
- Enviar o recibir mensajes.
- Subir archivos.
- Únete a los canales.
- Inicie la aplicación de escritorio.
El equipo de Slack nunca compartió el motivo de la interrupción de la nube y solicitó a todos los usuarios afectados que reiniciaran la aplicación y borraran su caché después de la recuperación.
Interrupción de iCloud (marzo de 2022)
Quince servicios importantes de Apple dejaron de funcionar durante cuatro horas en marzo debido a una interrupción de la nube, que incluye:
- Tienda de aplicaciones.
- Mapas de Apple.
- Apple TV.
Los sistemas corporativos y minoristas de Apple también fallaron. Más tarde, la empresa reveló que la causa raíz era un problema relacionado con el sistema de nombres de dominio (DNS) de la empresa.
Interrupción de Google Cloud (marzo de 2022)
El 8 de marzo de 2022, los usuarios de Google Cloud sufrieron errores de servicio durante dos horas y media . Spotify y Discord estuvieron entre los afectados por la interrupción.
Un cambio en el código de Traffic Director para procesar configuraciones provocó el error. Según el informe posterior a la recuperación, los cambios de código incorrectos ignoraron las migraciones de formato de datos de configuración, por lo que la plataforma eliminó inadvertidamente la programación del usuario.
Apagón de Atlassian (abril de 2022)
La mayor interrupción de Atlassian del año comenzó el 5 de abril y finalizó el 18 de abril (aunque algunos usuarios comenzaron a restaurar los servicios el 8 de abril). La empresa explicó que la interrupción ocurrió debido a una comunicación inadecuada del equipo y un plan de respuesta a incidentes mal planificado.
Aunque esta interrupción de la nube duró casi dos semanas para algunos usuarios, no hubo informes de pérdidas significativas de datos de clientes. Sin embargo, los usuarios de los dos productos estrella de Atlassian, Trello y Jira, se vieron afectados por el problema.
Interrupción de Microsoft Azure (junio de 2022)
El 7 de junio, los clientes de Azure no pudieron conectarse a los recursos alojados en la región Este de EE. UU. 2 (principalmente Virginia). El apagón duró unas doce horas y no afectó a los consumidores que dependen de la infraestructura con redundancia de zona. Servicios comprometidos incluidos:
- Perspectivas de la aplicación.
- Análisis de registros.
- Servicio de identidad administrada.
- Servicios multimedia.
- Archivos de NetApp.
El culpable fue una oscilación de energía repentina en uno de los centros de datos locales, lo que provocó el cierre de las unidades de tratamiento de aire (AHU).
Interrupción de Cloudflare (junio de 2022)
En junio, una interrupción accidental en Cloudflare provocó importantes interrupciones que duraron una hora y media , eliminando sitios populares como:
- Discordia.
- Shopify.
- Fitbit.
- Pelotón.
El proveedor con sede en San Francisco explicó que el tiempo de inactividad no planificado se debió a un cambio en la configuración de la red en 19 de sus centros de datos.
No pase por alto el valor de la planificación de interrupciones de la nube
Los ejemplos de interrupciones de la nube en los últimos años envían un mensaje claro:aunque la nube cambia las reglas del juego de TI, la tecnología no es infalible . Las empresas que se preocupan por los usuarios finales y la disponibilidad de las aplicaciones deben estar preparadas para tiempos de inactividad ocasionales, lo que hace que la copia de seguridad y la recuperación ante desastres (BDR) sean una parte integral del uso de recursos basados en la nube.
Computación en la nube
- ¿Qué es el moldeo por transferencia y cómo funciona?
- Cómo (y por qué) comparar el rendimiento de su nube pública
- ¿Qué es la seguridad en la nube y por qué es necesaria?
- La nube y cómo está cambiando el mundo de las TI
- Arquitecturas basadas en agentes o sin agentes:¿por qué es importante?
- Qué es un servidor VPN ofuscado y cómo funciona
- ¿Cómo funciona Google Cloud Storage?
- ¿Qué es una transmisión y cómo funciona?
- Por qué y cómo realizar una auditoría de vacío
- ¿Qué es un embrague industrial y cómo funciona?
- Inspecciones de grúas:¿cuándo, por qué y cómo?