


Red de predicción de metamaterial con resonador de anillo dividido basada en aprendizaje profundo
Resumen
La introducción de "metamateriales" ha tenido un profundo impacto en varios campos, incluido el electromagnético. Sin embargo, diseñar la estructura de un metamaterial a pedido es un proceso que requiere mucho tiempo. Como método eficiente de aprendizaje automático, el aprendizaje profundo se ha utilizado ampliamente para la clasificación y regresión de datos en los últimos años y, de hecho, ha mostrado un buen rendimiento de generalización. Hemos construido una red neuronal profunda para el diseño bajo demanda. Con la reflectancia requerida como entrada, los parámetros de la estructura se calculan automáticamente y luego se emiten para lograr el propósito de diseñar bajo demanda. Nuestra red ha logrado errores cuadráticos medios (MSE) bajos, con MSE de 0,005 tanto en los conjuntos de entrenamiento como en los de prueba. Los resultados indican que al utilizar el aprendizaje profundo para entrenar los datos, el modelo entrenado puede guiar con mayor precisión el diseño de la estructura, acelerando así el proceso de diseño. En comparación con el proceso de diseño tradicional, el uso del aprendizaje profundo para guiar el diseño de metamateriales puede lograr propósitos más rápidos, precisos y convenientes.
Introducción
La nanoóptica es un tema interdisciplinario de nanotecnología y óptica. En los últimos años, al diseñar constantemente estructuras con diferentes tamaños de sub-longitud de onda para lograr interacciones especiales con la luz incidente, los científicos han logrado manipular ciertas características de transmisión de la luz [1, 2, 3]. Desde que se propusieron los metamateriales, han atraído la atención de muchos académicos en este campo y, al mismo tiempo, su estudio teórico relacionado [4, 5], el proceso [6, 7] y la investigación aplicada [8] están avanzando a la misma velocidad. Se han realizado muchas funciones peculiares, incluyendo imágenes holográficas, absorción perfecta [9] y lentes planas [10]. Debido al rápido desarrollo de la tecnología de terahercios y sus características únicas, también se ha convertido en un tema de investigación popular en el campo de los metamateriales en los últimos años [11,12,13].
Aunque la aplicación de metamateriales es muy amplia, el método de diseño tradicional requiere que el diseñador realice repetidamente cálculos numéricos complejos sobre la estructura que se está diseñando. Este proceso consume una gran cantidad de tiempo y recursos informáticos. Por lo tanto, es urgente encontrar nuevas formas de simplificar o incluso reemplazar los métodos de diseño tradicionales.
Como campo interdisciplinario, el aprendizaje automático cubre muchas disciplinas, incluidas las ciencias de la vida, las ciencias de la computación y la psicología, se ha estado trabajando para usar computadoras para imitar e implementar procesos de aprendizaje humano para adquirir nuevos conocimientos o habilidades. El principio básico del aprendizaje automático se puede describir simplemente como el uso de algoritmos informáticos para obtener la correlación entre una gran cantidad de datos o para predecir las reglas entre datos similares y finalmente lograr el propósito de clasificación o regresión. Hasta ahora, muchos algoritmos de aprendizaje automático se han aplicado a la designación de metamateriales y han logrado resultados significativos, incluidos algoritmos genéticos [14], algoritmos de regresión lineal [15] y redes neuronales superficiales. A medida que la estructura se vuelve cada vez más compleja y los cambios en la estructura se vuelven más diversos, los problemas requerirán más tiempo para resolverse. Al mismo tiempo, la naturaleza altamente no lineal de los problemas dificulta que los algoritmos simples de aprendizaje automático obtengan predicciones precisas. Además, diseñar una estructura de metamaterial coincidente para un efecto electromagnético específico requiere que los diseñadores intenten realizar cálculos numéricos complejos en la estructura. Estos procesos consumirán una enorme cantidad de tiempo y recursos informáticos.
Como uno de los algoritmos más destacados en el campo del aprendizaje automático, el aprendizaje profundo ha logrado logros de renombre mundial en varios campos relacionados, como la visión por computadora [16], la extracción de características [17] y el procesamiento del lenguaje natural [18]. Al mismo tiempo, los éxitos en otros campos no relacionados con la informática son numerosos, incluidas muchas disciplinas básicas como las ciencias de la vida, la química [19] y la física [20] [21]. Por lo tanto, aplicar el aprendizaje profundo al diseño de metamateriales también es una dirección de investigación candente en la actualidad, y han aparecido muchos trabajos destacados [22, 23, 24].
Inspirado en el aprendizaje profundo, este documento informa un estudio que utiliza un algoritmo de aprendizaje automático basado en una red neuronal profunda para predecir la estructura del resonador de anillo dividido (SRR) para lograr el propósito de diseñar bajo demanda. Además, la red directa y la red inversa se entrenan de manera innovadora por separado, lo que no solo puede mejorar la precisión de la red, sino que también puede lograr diferentes funciones a través de una combinación flexible. Los resultados muestran que el método puede lograr un MSE de 0,0058 y 0,0055 en el conjunto de entrenamiento y el conjunto de validación, respectivamente, y muestra una buena solidez y generalización. Con el modelo entrenado que guía el diseño de estructuras de metamateriales, el ciclo de diseño se puede acortar a días o incluso a horas, y la mejora en la eficiencia es obvia. Además, este método también tiene una buena escalabilidad y solo necesita cambiar los datos del conjunto de entrenamiento para diseñar diferentes entradas o diferentes estructuras bajo demanda.
Teoría y método
Construcción de modelos COMSOL
Para mostrar que el aprendizaje profundo se puede aplicar al diseño inverso de estructuras de metamateriales, modelamos una estructura SRR de tres capas que consta de un anillo de oro, un fondo de sílice y un fondo de oro para observar su respuesta electromagnética bajo la acción del Incidente de luz. Como se muestra en la Fig.1, el ángulo de apertura θ del anillo de oro, el radio interior r del anillo y el ancho de línea d del anillo se seleccionan como variables independientes de esta estructura. Cuando un haz de luz linealmente polarizada ingresa normalmente a los metamateriales, las curvas de longitud de onda-reflectancia bajo diferentes estructuras se obtienen cambiando las variables estructurales. El espesor del anillo de Au es de 30 nm, del fondo de SiO 2 es de 100 nm, y de la parte inferior de Au es de 50 nm, y el tamaño de los metaátomos es de 200 nm por 200 nm.
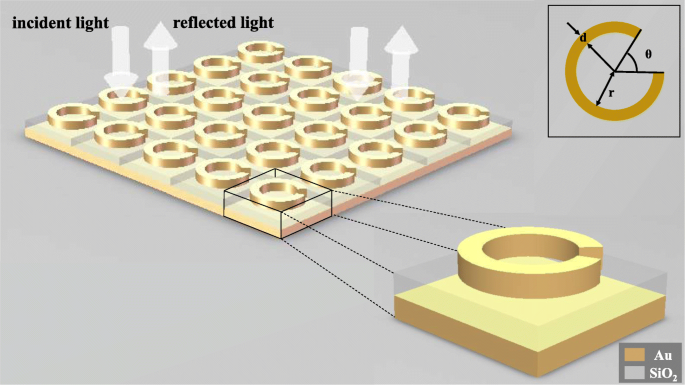
Diagrama esquemático de la estructura. Toda la metasuperficie está compuesta por metaátomos dispuestos repetidamente en dos direcciones, y la luz polarizada linealmente incide perpendicularmente a la metasuperficie. Cada metaátomo está compuesto por un anillo de oro, una base de sílice y una base de oro en orden de arriba hacia abajo. El anillo de oro superior contiene tres parámetros estructurales, a saber, el ancho de línea d , el ángulo de apertura θ y el radio del anillo interior r
Utilice COMSOL Multiphysics 5.4 [25] para modelar, elija dimensión espacial tridimensional, elija óptica ≥ óptica de onda ≥ dominio de frecuencia de onda electromagnética (ewfd) para el campo físico y seleccione el dominio de longitud de onda para la investigación. Crea el modelo anterior en geometría. El material de cada parte y su índice de refracción se definen en orden en el material, y los puertos y las condiciones periódicas se agregan en el dominio de frecuencia de ondas electromagnéticas.
Creación de un modelo de red neuronal de aprendizaje profundo
Hemos construido una red inversa y una red directa para la estructura del metamaterial. La red inversa puede predecir los parámetros estructurales del SRR a partir de los dos conjuntos dados de curvas de reflectancia de longitud de onda con diferentes direcciones de polarización. La red directa puede predecir las curvas de reflectancia de longitud de onda en dos direcciones de polarización mediante los parámetros estructurales dados. La función de la red inversa es el cuerpo principal de la función de predicción. El papel de la red directa es verificar los resultados de la predicción de la red inversa para observar si los resultados de la predicción cumplen con la respuesta electromagnética requerida.
Utilice eclipse 2019 como plataforma de desarrollo, python3.7 como lenguaje de programación y TensorFlow 1.12.0 como marco de desarrollo.
Las dos redes se entrenan por separado para evitar que los resultados del entrenamiento de cada red se vean afectados por el error de la otra red, lo que garantiza la precisión respectiva de las dos redes.
Como se muestra en la Fig.2, otra ventaja de entrenar las dos redes por separado es que se pueden usar para diferentes propósitos a través de diferentes secuencias de conexión:(a) red inversa + red directa, que puede usar la curva de reflectancia de longitud de onda dada para calcular la estructurar parámetros, hacer predicciones y verificar si los resultados de la predicción satisfacen las necesidades, y (b) el uso de la red directa solo puede simplificar el proceso de cálculo del método de cálculo numérico y reducir el tiempo de cálculo.
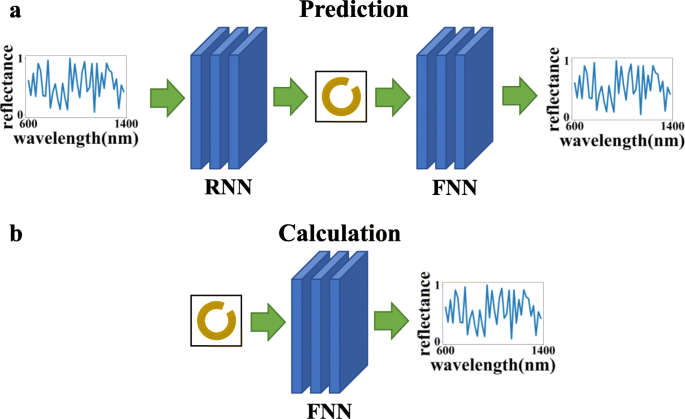
En esta figura, FNN se refiere a la red neuronal directa y RNN se refiere a la red neuronal inversa. El gráfico superior ( a ) indica que las dos redes se pueden conectar para lograr el efecto de predicción y verificación, y el gráfico inferior ( b ) indica que la red de respuesta directa solo se puede utilizar para calcular la respuesta óptica
Vale la pena señalar que el proceso de ingresar y obtener los resultados del modelo entrenado utilizando el método de aprendizaje profundo toma un tiempo extremadamente corto. Y siempre que se obtengan nuevos datos mediante simulación o experimentación, el modelo se puede utilizar para formación adicional. Los estudios han demostrado que con el aumento continuo de los datos de entrenamiento, la precisión del modelo será cada vez mayor y el rendimiento de la generalización será cada vez mejor [26].
Los parámetros de la estructura son múltiples conjuntos de valores propios continuos, que pertenecen al problema de regresión. En los últimos años, las redes completamente conectadas han sido el foco de las redes de aprendizaje profundo en problemas de regresión y han mostrado las características de alta confiabilidad, gran rendimiento de datos y baja latencia. Hacer algunos ajustes en una red completamente conectada permitirá que la red prediga mejor la estructura.
Como se muestra en la Fig. 3b, la red directa es una red completamente conectada en la que todos los nodos de las dos capas adyacentes están conectados entre sí. Los datos de entrada son el parámetro estructural y la salida es la curva de longitud de onda-reflectancia de las dos direcciones de polarización. Como se muestra en la Fig. 3a, la red inversa consta de una capa de extracción de características (capa FE) y una capa completamente conectada (capa FC). La capa FE incluye dos conjuntos de redes completamente conectadas que no están conectadas entre sí y procesa las curvas de reflectancia de longitud de onda de la luz polarizada linealmente en las dos direcciones para extraer algunas características de los datos de entrada. La capa FC aprenderá las características extraídas y generará los parámetros estructurales. Debido a las características de alta cohesión y bajo acoplamiento entre las curvas de longitud de onda y reflectancia en diferentes estados de polarización, separar las entradas de dos conjuntos de datos de luz polarizada en diferentes direcciones puede evitar que la red se vea perturbada por la estandarización de datos durante el proceso de extracción de datos. La red directa no implica varios conjuntos de entradas y no necesita considerar la interferencia mutua entre los datos, por lo que no tiene una capa de extracción de características.
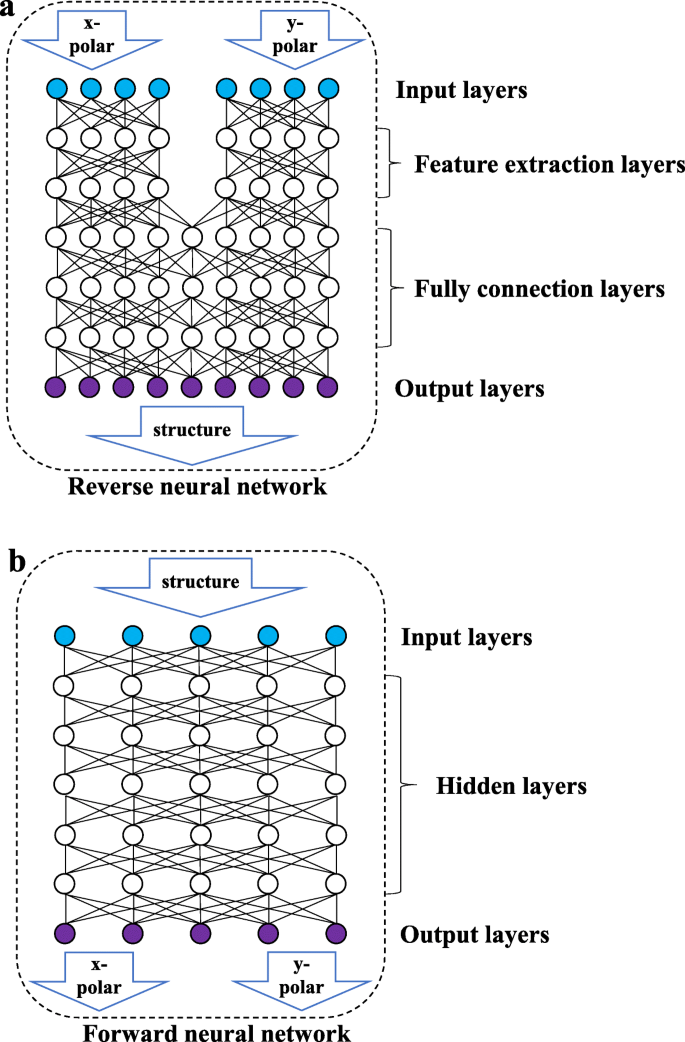
Diagrama esquemático de la estructura de la red. La figura anterior muestra la red inversa. La red inversa consta de una capa de entrada, una capa de extracción de características, una capa completamente conectada y una capa de salida. La siguiente figura muestra la red directa, que consta de una capa de entrada, una capa oculta y una capa de salida
Para determinar la estructura de red óptima, las redes en diferentes estructuras se entrenan utilizando el mismo conjunto de datos. Como se muestra en la Fig. 4, después de que los datos hayan experimentado 50 épocas (cuando todos los datos han pasado por un entrenamiento completo, se denomina época), el MSE alcanzado por la red directa de diferentes estructuras. Como se puede ver en la imagen de la izquierda de la Fig.4, cuando la red directa contiene 5 capas ocultas, cada capa contiene 100 nodos, el MSE más bajo alcanzado es aproximadamente 0.0174, por lo que se seleccionará la red directa de esta estructura.
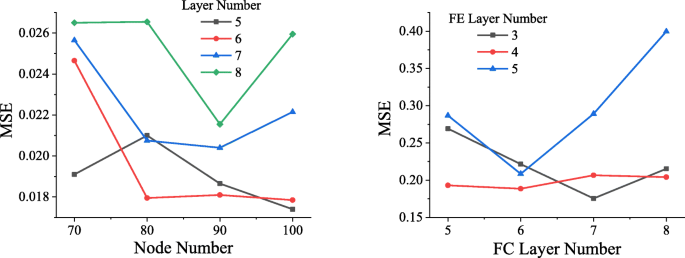
Comparación de estructuras de red. En la figura de la izquierda, el eje horizontal representa el número de nodos en cada capa, el eje vertical representa MSE y el negro, rojo, azul y verde representan la situación cuando la capa oculta contiene 5, 6, 7 y 8 capas, respectivamente. En la figura de la derecha, el eje horizontal indica el número de capas en la capa completamente conectada, el eje vertical indica MSE y las líneas negra, roja y azul indican la situación en la que la capa FE incluye 3, 4 y 5 , respectivamente
De manera similar, se entrenaron diferentes redes de redes inversas y el volumen de entrenamiento aún se estableció en 50 épocas. El resultado se muestra en la figura de la derecha de la Fig. 4. Cuando el número de capas FC es 7 y el número de capas FE es 3, la red alcanza el MSE más bajo, que es aproximadamente 0,1756.
Descubrimos que una mayor cantidad de capas de red producirá un fenómeno de explosión de gradiente, lo que hará que la red no converja, y la pérdida es infinita, por lo que no se incluye en la figura.
Procesamiento previo de datos
Para entrenar una red directa más confiable, los datos de reflectancia se vuelven a dividir y se cosen con la refractividad de Au y SiO 2 correspondiente a cada frecuencia. Luego, los datos recopilados se normalizan y se ingresan en la red de reenvío, lo que puede mejorar en gran medida la precisión de la red de reenvío.
Para garantizar que los datos con valores más grandes no tengan un impacto mayor en la red que los datos con valores más pequeños, los datos de entrada deben normalizarse para que cada columna de datos se ajuste a la distribución normal estándar (el valor medio es 0, la varianza es 1), y luego los datos procesados x se puede expresar de la siguiente manera:
$$ x =\ frac {\ left ({x} _0 \ hbox {-} \ mu \ right)} {\ sigma} $$ (1)En la expresión, x 0 son los datos originales de la muestra, μ la media de la muestra y σ la desviación estándar de la muestra. Si los datos de entrada no se vuelven a dividir, la reflectancia se distorsionará después de la normalización, lo que reducirá la precisión de la red. Los datos re-divididos no afectarán su distribución debido a la normalización.
Método de red neuronal
El principio de la red neuronal es construir muchas neuronas (nodos) imitando la forma en que funciona y aprende el cerebro humano [27]. Las neuronas están conectadas entre sí y la salida se ajusta ajustando el peso de la conexión. La salida de j El nodo de una capa se puede expresar de la siguiente manera:
$$ {y} _j =\ frac {\ sum \ limits_ {i =1} ^ nf \ left ({w} _i {x} _i + {b} _j \ right)} {n} $$ (2)f es la función de activación, w i es el peso de conexión del i de la capa anterior th nodo conectado al j th nodo, x i es la salida de i el nodo de la capa anterior, b j es el término de sesgo de este nodo, y n es el número de nodos en la capa anterior conectados al j th nodo.
Elección de una función de activación
Para resolver la alta no linealidad del problema inverso, la función ELU [28] se utiliza como función de activación de cada capa de neuronas [28]. La salida f ( x ) de la función ELU se puede expresar por partes de la siguiente manera:
$$ f (x) =\ left \ {\ begin {array} {c} x \\ {} \ alpha \ left ({e} ^ x-1 \ right) \ end {array} \ right. {\ Displaystyle \ begin {array} {c}, \\ {}, \ end {array}} {\ displaystyle \ begin {array} {c} x \ ge 0 \\ {} x <0 \ end {array}} $$ (3)En esta función, x es la entrada original y el valor del parámetro para α varía de 0 a 1.
La razón para usar la función de activación es que la función de activación cambia la capacidad de expresión no lineal de cada capa de la red, mejorando así la capacidad de ajuste no lineal general de la red. Como se muestra en la Fig. 5, la función ELU combina las ventajas de las funciones de activación Sigmoid y unidad lineal rectificada (ReLU). Cuando x <0, tiene una mejor saturación suave, lo que hace que la red sea más robusta a los cambios de entrada y al ruido. Cuando x > 0, no hay saturación, lo que ayuda a paliar la desaparición del gradiente de la red. La característica de que el valor medio de ELU está cerca de 1 puede facilitar la instalación de la red. El resultado demuestra que al usar ELU como la función de activación del aprendizaje profundo, la red neuronal mejora significativamente la robustez de la red.
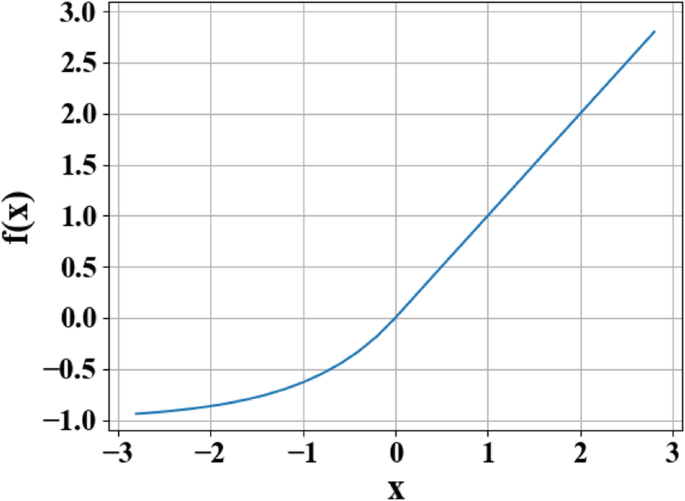
Curva de función de unidades lineales exponenciales (ELU). En la figura, x representa la entrada original y f ( x ) representa la salida de la función
Esquema de inicialización de peso
El método de inicialización del peso de la red de cada capa determina la velocidad del ajuste de la red e incluso determina si la red puede encajar o no. La inicialización de la escala de varianza se basa en la cantidad de datos de entrada en cada capa y extrae ponderaciones de una distribución normal truncada centrada en 0, de modo que la varianza se puede reducir a un cierto rango, luego los datos se pueden distribuir más profundamente en la red [29 ]. En esta estructura de red, el uso de la inicialización del escalado de varianza puede hacer que la velocidad de convergencia de la red sea significativamente más rápida.
Solución de sobreajuste
Debido a la insuficiencia de datos, la red producirá un sobreajuste. Con un sobreajuste reducido, la red puede tener un buen rendimiento de generalización en datos fuera del conjunto de entrenamiento. La regularización L2 (también llamada pérdida de peso en problemas de regresión) se usa para procesar el peso w . La salida regularizada L se puede expresar de la siguiente manera:
$$ L ={L} _0 + \ frac {\ lambda} {2n} \ sum {w} ^ 2 $$ (4)En Eq. (4), L 0 representa la función de pérdida original, y un término de regularización \ (\ frac {\ lambda} {2n} \ sum {w} ^ 2 \) se agrega sobre esta base, donde λ representa el coeficiente de regularización, n el rendimiento de los datos y w el peso. Después de agregar el término de regularización, el valor del peso w tiende a disminuir en general, y se puede evitar la aparición de valores excesivos, por lo que w también se llama atenuación de peso. La regularización L2 puede reducir el peso para evitar una gran pendiente de la curva ajustada, lo que alivia de manera efectiva el fenómeno de sobreajuste de la red y ayuda a la convergencia.
Sobre esta base, también se utiliza el método de abandono. Este método puede considerarse visualmente como "ocultar" una cierta escala de nodos de red para cada entrenamiento, y ocultar diferentes nodos durante cada entrenamiento, para lograr el objetivo de entrenar múltiples "redes parciales". Y a través del entrenamiento, la mayoría de las "redes parciales" pueden representar con precisión los objetivos, y los resultados de todas las "redes parciales" se pueden clasificar para obtener la solución de los objetivos.
El uso de los métodos de regularización y abandono de L2 mencionados anteriormente no solo puede aliviar de manera efectiva la baja generalización causada por datos insuficientes, sino también reducir el impacto de una pequeña cantidad de datos erróneos en el conjunto de datos sobre los resultados del entrenamiento.
En esta estructura de red y conjunto de datos, con deserción =0.2 y coeficiente de regularización L2 λ =0.0001, la red puede obtener una precisión similar en el conjunto de entrenamiento y el conjunto de prueba, logrando así un alto rendimiento de generalización.
Resultado y discusión
Después del entrenamiento, nuestra red directa puede alcanzar un alto grado de ajuste, con un MSE de 0.0015, lo que muestra que la salida es muy similar a los resultados de la simulación, como se muestra en la Fig. 6. Esto también asegura que al entrenar la red inversa, el los resultados de la red inversa se pueden verificar de manera confiable.
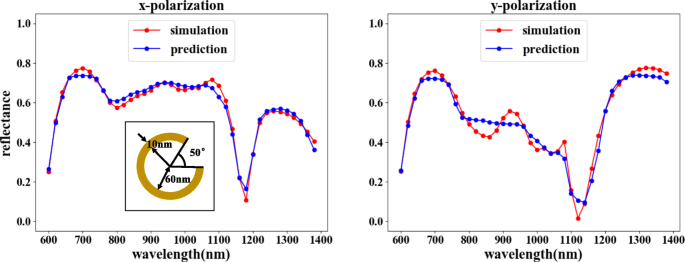
Resultados del entrenamiento de la red avanzada. Los parámetros estructurales correspondientes son θ =50 °, r =60 nm y d =10 nm. En la figura, el eje horizontal representa la longitud de onda de la luz incidente, el eje vertical representa la reflectividad, la línea roja representa el resultado de la simulación COMSOL y la línea azul representa el resultado del entrenamiento de la red. La figura de la izquierda muestra la curva de reflectividad correspondiente a la x -Entrada polarizada, y la figura de la derecha muestra la curva de reflectividad correspondiente a la y -entrada polarizada
Finalmente, generaremos dos modelos a partir de la red aprendida y conectaremos los dos modelos para lograr la función de predicción.
La función de predicción puede elegir la combinación que se muestra en la Fig. 2a. La red inversa predice la estructura correspondiente de acuerdo con la curva de reflectancia de longitud de onda requerida, y la red directa verifica la respuesta óptica de la estructura. Como se muestra en la Fig. 7, al comparar la reflectancia verificada con la reflectancia de entrada, las características de reflectancia de la luz incidente en las dos direcciones de polarización son básicamente consistentes. Aunque se puede observar una discrepancia de reflectancia menor para ciertos valores de longitud de onda, la tendencia de coincidencia general es claramente irrefutable, ya que los errores están dentro de un rango aceptable.
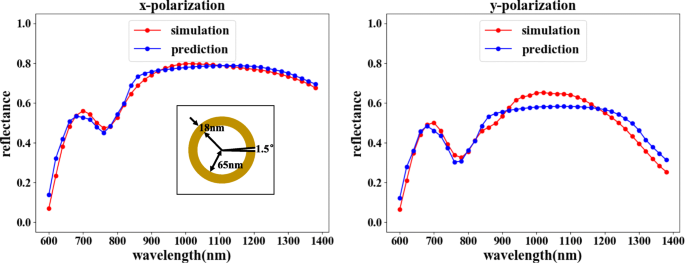
La red inversa seguida de una red directa puede lograr el propósito de predicción. En la figura, el eje horizontal representa la longitud de onda de la luz incidente, el eje vertical representa la reflectividad, la línea roja representa el resultado de la simulación COMSOL y la línea azul representa el resultado del entrenamiento de la red. La figura de la izquierda muestra la curva de reflectividad correspondiente a la x -Entrada polarizada, y la figura de la derecha muestra la curva de reflectividad correspondiente a la y -Entrada polarizada. Los resultados predichos para la curva de reflectancia de longitud de onda de entrada son θ =1,5 °, r =65 nm y d =18 millas náuticas
Conclusión
En este artículo, presentamos nuestra red de aprendizaje profundo diseñada, capaz de crear varios efectos mediante el empleo de combinaciones flexibles de configuraciones de red. Nuestra red inversa diseñada puede predecir la estructura requerida utilizando la curva de refracción de longitud de onda de entrada, lo que puede reducir en gran medida el tiempo requerido para resolver el problema inverso y satisfacer diferentes necesidades mediante la utilización de combinaciones flexibles. Los resultados indican que la red ha logrado una mayor precisión en las predicciones, lo que implica además que el diseño bajo demanda se puede resolver a través de nuestro método. El uso del aprendizaje profundo para guiar el diseño de metamateriales puede obtener automáticamente estructuras de metamateriales más precisas, un resultado inalcanzable con los métodos de diseño tradicionales.
Disponibilidad de datos y materiales
La fecha en que el manuscrito proviene de nuestra red de simulación y no podemos compartirlo por razones personales.
Abreviaturas
- ELU:
-
Unidades lineales exponenciales
- Capa FC:
-
Capa completamente conectada
- Capa FE:
-
Capa de extracción de características
- FNN:
-
Red neuronal de avance
- MSE:
-
Errores cuadrados medios
- ReLU:
-
Unidad lineal rectificada
- RNN:
-
Red neuronal inversa
- SRR:
-
Resonador de anillo partido
Nanomateriales
- Aprovechamiento de FPGA para el aprendizaje profundo
- El procesador automotriz cuenta con un acelerador de inteligencia artificial integrado
- Reconocimiento de dígitos AI con PiCamera
- Un robot móvil con evitación de obstáculos basada en la visión
- Mejora del rendimiento de los activos con aprendizaje automático
- Aprendizaje no supervisado con neuronas artificiales
- WND se asocia con Sigfox para suministrar al Reino Unido la red de IoT
- Método Split() String en Java:cómo dividir una cadena con un ejemplo
- Las propiedades eléctricas de los compuestos híbridos basados en nanotubos de carbono de paredes múltiples con nanoplaquetas de grafito
- Nanoesferas de carbono monodispersas con estructura porosa jerárquica como material de electrodo para supercondensador
- Prediga la vida útil de la batería con el aprendizaje automático