


Dominar los desafíos de la programación y depuración multinúcleo
En este artículo discutiremos varios aspectos del procesamiento multinúcleo, incluido un vistazo a los diferentes tipos de procesadores multinúcleo y por qué estos dispositivos se están volviendo comunes y populares en la actualidad. Luego, veremos algunos de los desafíos que presenta tener más de un núcleo en un chip y cómo los depuradores modernos con reconocimiento de múltiples núcleos pueden ayudar a que estas tareas complejas sean más manejables.
Rendimiento de los sistemas
Hay muchas formas de aumentar el rendimiento de un sistema informático integrado, desde algoritmos de compilación inteligentes hasta soluciones de hardware eficientes. Las optimizaciones del compilador son importantes para obtener la programación de instrucciones más eficiente a partir de un código de lenguaje de alto nivel que sea fácil de leer y comprender. Además de esto, los sistemas pueden aprovechar el paralelismo disponible en el proyecto para procesar más de una cosa a la vez. Y, por supuesto, escalar la frecuencia del reloj puede ser una forma eficaz de obtener más rendimiento de su sistema informático.
Desafortunadamente, han pasado los días en que se podía suponer que las velocidades del reloj aumentaban geométricamente. Y la optimización del código solo puede brindarle muchas mejoras, particularmente ahora, después de muchas generaciones de desarrollo de tecnología de compiladores. Esto nos deja para considerar el paralelismo como la mejor oportunidad para continuar escalando el rendimiento de nuestro sistema a medida que pasa el tiempo.
Paralelismo

Cavar un pozo es una tarea difícil de paralelizar. Otros pueden ayudar quitando la tierra con una pala, pero la excavación real en el hoyo es típicamente un trabajo de una sola persona. Como resultado, agregar más personas al pozo no hará el trabajo más rápido. De hecho, es posible que los demás se interpongan en el camino y ralenticen el proceso. Algunas tareas no son adecuadas para la paralelización.
Otras tareas se paralelizan fácilmente. Cavar una zanja es una tarea adecuada para la paralelización. Muchas personas pueden trabajar juntas.

Esta imagen muestra una forma de paralelismo llamada MIMD, Multiple Instruction Multiple Data. Cada excavadora es una unidad separada y puede realizar diferentes tareas. En este caso, puede imaginar que cuatro excavadoras pueden hacer el trabajo en aproximadamente 1/4 th el tiempo de una sola excavadora.
Con SIMD, datos múltiples de instrucción única, un solo excavador podría usar una pala como esta.
La unidad SIMD solo puede realizar un tipo de cálculo a la vez, pero puede realizarlo en varios datos en paralelo. Estos tipos de instrucciones son comunes en las unidades de procesamiento de vectores en muchos procesadores. Esto es útil si sus datos son muy regulares y necesita realizar las mismas operaciones una y otra vez en un gran conjunto de datos, como en el procesamiento de imágenes. Sin embargo, para tareas informáticas más generales, este modelo carece de flexibilidad y no producirá mejoras en el rendimiento.
Esto nos lleva a la opción de colocar múltiples subsistemas de CPU completos en un solo chip, creando procesadores multinúcleo. Varios núcleos en un chip pueden escalar el rendimiento. Cada núcleo es una CPU completa y puede funcionar de forma independiente o en conjunto con otros núcleos.
Diferentes tipos de procesamiento multinúcleo
Existen diferentes combinaciones de tipos de núcleos que puede tener en un chip de procesador, así como también cómo se distribuye el trabajo entre ellos.
Los procesadores homogéneos de varios núcleos tienen dos o más copias del mismo núcleo de procesador. Cada núcleo se ejecuta de forma autónoma y puede comunicarse y sincronizarse con otros núcleos a través de una serie de mecanismos como la memoria compartida o los sistemas de buzón de correo. Cada procesador tiene sus propios registros y unidades de función, y puede tener su propia memoria o caché local. Sin embargo, lo que hace que esto sea homogéneo es el hecho de que todos los núcleos que estamos viendo son del mismo tipo.
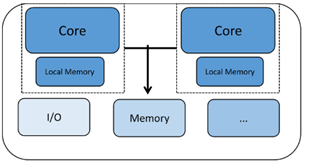
Otro tipo de chip de múltiples núcleos se denomina multinúcleo heterogéneo con dos o más tipos diferentes de núcleos de CPU. Aquí los núcleos pueden tener características muy diferentes que los hacen muy adecuados para diferentes partes de las necesidades de procesamiento del sistema. Un ejemplo podría ser un chip de comunicaciones Bluetooth donde un núcleo está dedicado a administrar la pila de protocolos Bluetooth mientras que el otro núcleo puede administrar las comunicaciones externas, el procesamiento de aplicaciones, la interfaz humana, etc. Este tipo de chip de múltiples núcleos se puede utilizar para aplicaciones que necesitan ambos rendimiento dedicado en tiempo real en un núcleo y capacidades de administración del sistema en el otro.
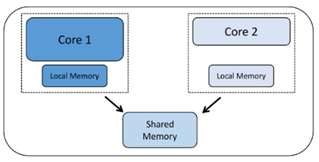
Ahora veremos cómo se utilizan los núcleos. El multiprocesamiento simétrico (SMP) ocurre cuando tiene más de un núcleo y los núcleos ejecutan la misma base de código de proyecto. Diferentes núcleos pueden ejecutar diferentes partes del código al mismo tiempo, pero el código se construye como un solo proyecto y se envía a los núcleos separados por algún programa de control como un sistema operativo en tiempo real (RTOS). Por necesidad, los núcleos que funcionan de esta manera deben ser del mismo tipo, ya que todos usan el mismo código de proyecto compilado para un tipo de procesador.
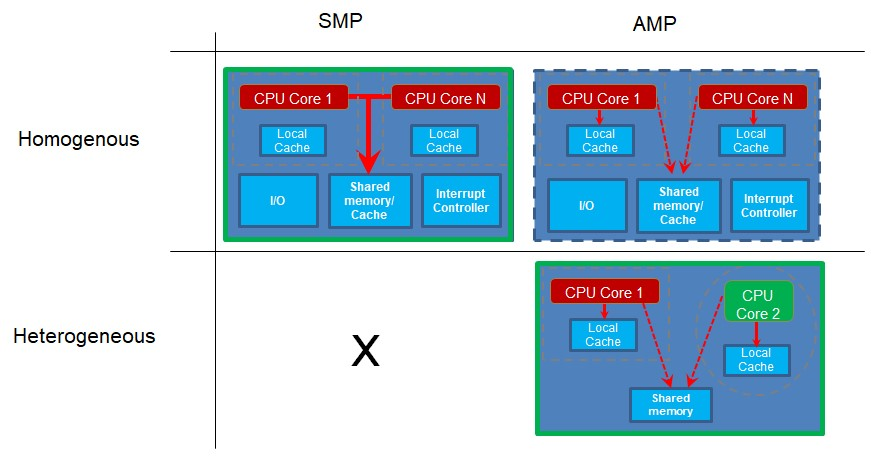
El multiprocesamiento asimétrico (AMP) ocurre cuando tiene más de un núcleo o procesador y cada procesador ejecuta su propia aplicación de proyecto. Los núcleos separados pueden sincronizarse o comunicarse de vez en cuando, pero cada uno tiene su propia base de código que ejecuta. Dado que cada uno está ejecutando su propio proyecto, estos núcleos pueden ser de diferentes tipos o núcleos heterogéneos. Sin embargo, esto no es un requisito. Si dos o más del mismo tipo de núcleos ejecutan un código de proyecto diferente, son núcleos homogéneos que ejecutan AMP.
Tenga en cuenta que para la operación SMP debe tener varios núcleos homogéneos, ya que todos ejecutan código desde la misma base de código de proyecto. Sin embargo, si tiene varios proyectos con diferentes bases de código para que se ejecuten los diferentes núcleos, estos pueden ser núcleos diferentes, como en un sistema heterogéneo. Sin embargo, si los núcleos son iguales, también funciona.
Razones para utilizar multinúcleo
Durante los últimos años, la ley de Moore, acuñada a mediados de la década de 1960, finalmente parece estar perdiendo fuerza, o al menos desacelerándose. Las velocidades de reloj del procesador ya no se duplican cada 2-3 años y, de hecho, las CPU de mayor velocidad han alcanzado un techo en el rango bajo de GHz de un solo dígito durante muchos años.
Una forma de continuar impulsando el rendimiento es tener más núcleos de CPU trabajando juntos si puede usarlos de manera eficiente.
Si bien las velocidades se han estancado, el tamaño del transistor ha seguido reduciéndose. Aunque son más lentos que en el pasado, los pequeños transistores permiten empaquetar más lógica en un solo chip. Como resultado, el uso de estos transistores para colocar varios núcleos de CPU en un solo chip puede aprovechar las interconexiones de bus mucho más rápidas y más amplias entre los diversos subsistemas de CPU y memoria.
El multiprocesamiento asimétrico heterogéneo es muy útil cuando una aplicación tiene dos o más cargas de trabajo que tienen características y requisitos muy diferentes. Uno podría depender del tiempo real y de la latencia de interrupciones, mientras que el otro podría depender más del rendimiento que del tiempo de respuesta. Este modelo funciona muy bien:por ejemplo, un dispositivo puede dedicar un núcleo para administrar una pila de protocolos de comunicaciones como Bluetooth o Zigbee, mientras que otro núcleo actúa como un procesador de aplicaciones que ejecuta interacciones humanas y operaciones generales de administración del sistema. El procesador de comunicaciones, al estar aislado, puede proporcionar una excelente respuesta en tiempo real que necesita la pila de protocolos. Además, el software de comunicación se puede certificar según un estándar que hace que todo el producto sea fácil de certificar manteniendo las modificaciones funcionales separadas de esta parte del sistema.
Desafíos con el uso de varios núcleos
¿Qué tipo de desafíos se presentan cuando coloca más de un núcleo de CPU en un chip? Bueno, profundicemos en ello.
Es posible que una aplicación o software monolítico no pueda utilizar los recursos informáticos disponibles de manera eficiente. Debe organizar la aplicación en tareas paralelas que se pueden ejecutar al mismo tiempo para utilizar recursos de más de un núcleo. Esto puede requerir una forma desconocida para que los ingenieros de software piensen en el diseño integrado. Es posible que la migración del código de bucle único existente no sea muy fácil. Muy pocos subprocesos o incluso demasiados subprocesos pueden convertirse en barreras de rendimiento.
Las aplicaciones que comparten estructuras de datos o dispositivos de E / S entre varios subprocesos o procesos pueden tener cuellos de botella en serie. Para mantener la integridad de los datos, es posible que sea necesario serializar el acceso a estos recursos compartidos mediante técnicas de bloqueo, por ejemplo, bloqueo de lectura, bloqueo de lectura y escritura, bloqueo de escritura, bloqueo de giro, mutex, etc. Los bloqueos diseñados de manera ineficiente podrían crear cuellos de botella debido a un alto nivel de contención de bloqueos entre varios subprocesos o procesos que intentan adquirir el bloqueo para utilizar un recurso compartido. Esto podría degradar potencialmente el rendimiento de la aplicación o el software. El rendimiento de una aplicación podría incluso degradarse a medida que aumenta la cantidad de núcleos o procesadores si algunos núcleos están bloqueando a otros esperando bloqueos comunes, lo que hace que dos núcleos funcionen peor que uno.
Una carga de trabajo distribuida de manera desigual puede resultar ineficaz a la hora de utilizar los recursos informáticos. Es posible que deba dividir las tareas grandes en otras más pequeñas que se puedan ejecutar en paralelo. Es posible que deba cambiar los algoritmos seriales a paralelos para mejorar el rendimiento y la escalabilidad. Sin embargo, si algunas tareas se ejecutan muy rápidamente y otras toman una cantidad significativa de tiempo, las tareas rápidas pueden pasar una cantidad significativa de tiempo esperando que se completen las tareas largas. Esto da como resultado valiosos recursos informáticos inactivos y un escalado de rendimiento deficiente.
Es probable que un RTOS lo ayude, pero es posible que no lo resuelva todo. En un sistema SMP, esto es prácticamente imprescindible para programar tareas en varios núcleos similares. El trabajo a realizar se puede dividir por datos o por función. Si divide las cosas por fragmentos de datos, cada subproceso podría realizar todos los pasos en una canalización de procesamiento. Alternativamente, puede hacer que un subproceso realice un paso en la función, mientras que otro realice el siguiente paso, etc. Las ventajas de una técnica sobre la otra dependerán de las características del trabajo a realizar.
Depuración en entornos multinúcleo
Lo primero que resulta útil al depurar un sistema multinúcleo es la visibilidad de todos los núcleos. Idealmente, deberíamos poder iniciar y detener núcleos de forma simultánea o individual, es decir, un solo paso en un núcleo mientras otros están en ejecución o detenidos. Los puntos de interrupción multinúcleo pueden resultar muy útiles para controlar el funcionamiento de un núcleo basado en el estado de otro.
El rastreo multinúcleo puede ser muy difícil de implementar. Administrar el gran ancho de banda de la información de seguimiento de varios núcleos, así como tratar con tipos potencialmente diferentes de datos de seguimiento de diferentes tipos de núcleos es un verdadero desafío.
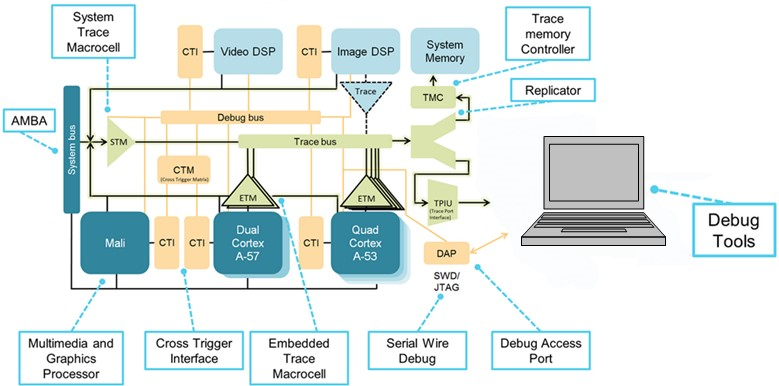
(Fuente:IAR Systems, diagrama cortesía de Arm Ltd.)
A continuación se muestra un ejemplo de un procesador con implementaciones multinúcleo heterogéneas y homogéneas. Hay dos grupos de núcleos homogéneos, uno basado en un brazo dual Cortex-A57 y el otro en un cuádruple Cortex-A53. Estos grupos son homogéneos dentro de sí mismos pero heterogéneos entre los dos grupos.
La arquitectura de depuración de CoreSight proporciona protocolos y mecanismos para comunicarse con los recursos de depuración en todos los núcleos y le corresponde al depurador administrar toda esta información y analizar los mensajes de diferentes núcleos. Las interfaces y la matriz de disparo cruzado (CTI, CTM) permiten la detención simultánea de ambos núcleos, el disparo de seguimiento y más. La infraestructura de rastreo incluye los puertos de rastreo seriales (SWD) y paralelos (TPIU) que se utilizan para suavizar el flujo de rastreo, y los embudos de rastreo que combinan el rastreo de cada fuente en un solo flujo. En comparación con la parte de doble núcleo, el diagrama que se muestra representa un chip mucho más complejo de controlar.
El depurador C-SPY en IAR Embedded Workbench proporciona soporte para depuración multinúcleo simétrica y asimétrica. Esto se habilita a través de las opciones del depurador en la pestaña multinúcleo. Para habilitar la depuración simétrica de múltiples núcleos, todo lo que se requiere es que se ingrese el número de núcleos para que el depurador sepa con cuántos procesadores diferentes comunicarse. Otros IDE pueden tener opciones similares disponibles.
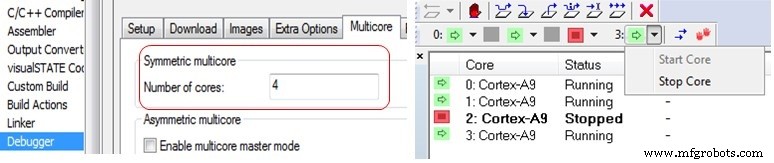
A la derecha (arriba), puede ver una vista en el depurador donde un clúster SMP Cortex-A9 de 4 núcleos muestra el estado de sus núcleos con el núcleo número 2 detenido mientras los otros tres núcleos se están ejecutando.
Un sistema asimétrico multinúcleo podría utilizar una parte multinúcleo heterogénea, como el ST STM32H745 / 755 que tiene un núcleo Cortex-M7 y un Cortex-M4 separado. En este caso, cuando se ejecuta el depurador, utiliza dos instancias del IDE (maestro y nodo). Uno para cada núcleo, ya que los dos núcleos ejecutan un código de proyecto diferente.
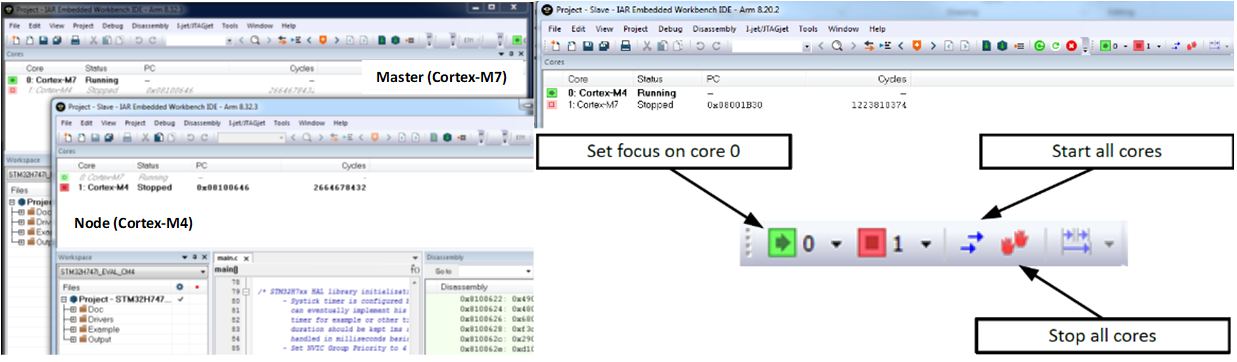
En cada instancia del IDE, hay información de estado sobre el núcleo que se está controlando, así como el otro núcleo controlado en la otra ventana. Hay opciones que se pueden seleccionar para controlar el comportamiento del depurador de modo que iniciar y detener los núcleos juntos o por separado esté bajo el control del desarrollador.
Este control total es posible gracias a las interfaces de disparador cruzado (CTI) y la matriz de disparador cruzado (CTM) que forman la función de disparador cruzado integrado en el brazo. Hay tres componentes CTI, uno a nivel de sistema, uno dedicado al Cortex-M7 y otro dedicado al Cortex-M4. Los tres CTI están conectados entre sí a través del CTM, como se ilustra en la figura siguiente. El depurador puede acceder al nivel de sistema y los CTI Cortex-M4 a través del puerto de acceso del sistema y el APB-D asociado. El Cortex-M7 CTI está físicamente integrado en el núcleo Cortex-M7 y se puede acceder a él a través del puerto de acceso Cortex-M7.
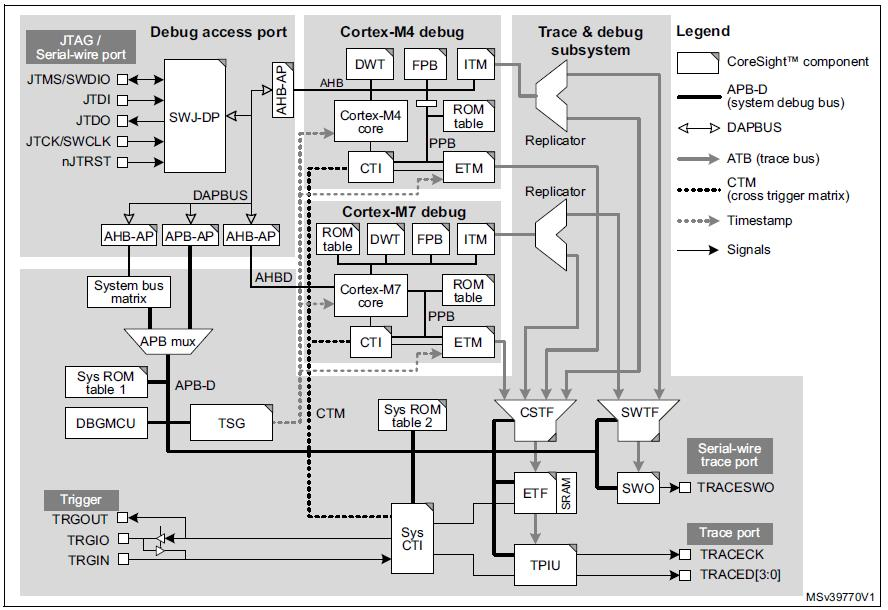
(Fuente:IAR Systems, diagrama cortesía de STMicroelectronics de M0399 Reference manual)
Los CTI permiten que los eventos de diversas fuentes activen la actividad de depuración y seguimiento. Por ejemplo, un punto de interrupción alcanzado en uno de los núcleos del procesador puede detener el otro procesador, o una transición detectada en una entrada de activación externa podría configurarse para iniciar el seguimiento del código.
En este ejemplo, con un procesador multinúcleo heterogéneo que tiene un núcleo Cortex-M7 y un núcleo Cortex-M4 en un solo chip, se utilizan dos programas separados:uno para ejecutar en el Cortex-M4 y el otro para ejecutar en el Cortex-M7. Cada proyecto usa FreeRTOS para administrar el software que se ejecuta en los procesadores. Los dos núcleos se comunican a través de una interfaz de memoria compartida. Sin embargo, ambas aplicaciones utilizan los mecanismos de paso de mensajes FreeRTOS para comunicarse con el otro procesador y ocultar la complejidad de los mecanismos subyacentes. Entonces, desde la perspectiva de una CPU, solo está enviando o recibiendo mensajes con otra tarea. Es transparente que la otra tarea se esté ejecutando en otro núcleo de CPU.
La imagen a continuación es la viuda del explorador del espacio de trabajo en el IDE. La descripción general de dos proyectos se muestra aquí para que pueda ver el contenido de los proyectos Cortex-M7 y Cortex-M4.
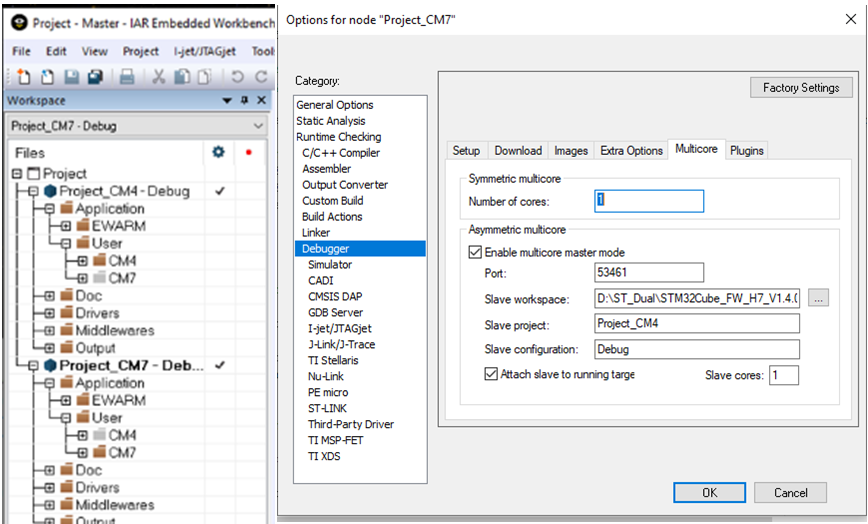
Al seleccionar una de las otras pestañas en la parte inferior de la ventana, puede cambiar el enfoque al proyecto M4 o al proyecto M7.
El proyecto Cortex-M7 tiene una tarea que envía mensajes a las tareas que se ejecutan en el Cortex-M4. El Cortex-M4 tiene dos instancias de una tarea de recepción en ejecución. El Cortex-M7 tiene una tarea de "verificación" que se ejecuta periódicamente para ver si todo sigue funcionando correctamente.
Finalmente, el depurador carga ambos proyectos. Esto significa que se inicia una instancia adicional de Embedded Workbench para el segundo depurador.
Para configurar el depurador para el soporte de multiprocesamiento asimétrico, necesitamos designar un proyecto como el "Maestro" y el otro como el proyecto "Nodo". De hecho, la selección es arbitraria y solo determina qué proyecto tiene la capacidad de lanzar el otro al inicio.
El proyecto "Nodo" no tiene una configuración especial y no sabe que se está ejecutando como un "Nodo" para otro proyecto.
De esta manera, cuando el proyecto "Maestro" tiene su depurador iniciado, automáticamente lanza otra instancia del IDE para acomodar una segunda sesión de depuración en la que se ejecutará el segundo proyecto.
Resumen
Multinúcleo permite ganancias de rendimiento cuando se agota la ley de Moore. Sin embargo, el multinúcleo presenta desafíos de depuración y requiere enfoques de desarrollo específicos para que la aplicación pueda aprovechar al máximo la arquitectura multinúcleo.
Una vez configurada la configuración de depuración, la depuración multinúcleo nunca ha sido tan fácil. Si ha utilizado herramientas para depurar mono-núcleos antes, reconocerá todo lo que se incluye en esto y probablemente nunca entenderá que otras personas hablan de lo difícil que es la depuración multinúcleo para ellos.
Las herramientas modernas de hardware y software lo ayudarán a superar los desafíos de depuración multinúcleo.
Nota:las imágenes de las figuras son de IAR Systems, a menos que se indique lo contrario.
 Aaron Bauch es un ingeniero senior de aplicaciones de campo en IAR Systems que trabaja con clientes en el este de Estados Unidos y Canadá. Aaron ha trabajado con sistemas integrados y software para empresas como Intel, Analog Devices y Digital Equipment Corporation. Sus diseños cubren una amplia gama de aplicaciones que incluyen instrumentación médica, navegación y sistemas bancarios. Aaron también ha enseñado una serie de cursos de nivel universitario, incluido el diseño de sistemas integrados como profesor en la Southern NH University. El Sr. Bauch tiene una licenciatura en Ingeniería Eléctrica de The Cooper Union y una Maestría en Ingeniería Eléctrica de la Universidad de Columbia, ambas en Nueva York, NY.
Aaron Bauch es un ingeniero senior de aplicaciones de campo en IAR Systems que trabaja con clientes en el este de Estados Unidos y Canadá. Aaron ha trabajado con sistemas integrados y software para empresas como Intel, Analog Devices y Digital Equipment Corporation. Sus diseños cubren una amplia gama de aplicaciones que incluyen instrumentación médica, navegación y sistemas bancarios. Aaron también ha enseñado una serie de cursos de nivel universitario, incluido el diseño de sistemas integrados como profesor en la Southern NH University. El Sr. Bauch tiene una licenciatura en Ingeniería Eléctrica de The Cooper Union y una Maestría en Ingeniería Eléctrica de la Universidad de Columbia, ambas en Nueva York, NY. Contenidos relacionados:
- Garantizar el comportamiento de sincronización del software en sistemas integrados críticos basados en varios núcleos
- Sistemas multinúcleo, hipervisores y marcos multinúcleo
- Computación integrada de alto rendimiento:paralelismo y optimización del compilador
- ¿Cree que su software funciona? ¡Demuéstralo!
- Rastreo de software en dispositivos implementados en el campo
- Compiladores en el extraño mundo de la seguridad funcional
Para obtener más información sobre Embedded, suscríbase al boletín informativo semanal por correo electrónico de Embedded.
Incrustado
- Redes WiFi, proveedores de SaaS y los desafíos que plantean
- Placas - Desglose el Pi - I2C, UART, GPIO y más
- Los cinco problemas y desafíos principales para 5G
- Los complejos factores de riesgo que enfrentan la industria aeroespacial y la defensa
- 5G, IoT y los nuevos desafíos de la cadena de suministro
- Enfrente los desafíos ETL de los datos de IoT y maximice el retorno de la inversión
- Dominar los desafíos del giro brusco
- Los 4 principales desafíos que enfrenta la industria OEM aeroespacial y de defensa
- La importancia y los desafíos de la documentación actualizada
- Comprensión de los beneficios y desafíos de la fabricación híbrida
- El proceso de diseño e implementación de la automatización de la planta