


Cómo entrenar un algoritmo para detectar y prevenir la ceguera temprana
Un dispositivo médico portátil que pudiera detectar con precisión las diferentes etapas de la retinopatía diabética, sin la necesidad de una conexión a Internet, reduciría en gran medida el número de casos de ceguera por retinopatía en todo el mundo. Con el aprendizaje automático integrado, ahora es posible desarrollar algoritmos que puedan ejecutarse directamente en dispositivos médicos que funcionan con baterías y realizar la detección o el diagnóstico. En este artículo, proporcionamos un tutorial de los pasos necesarios para entrenar rápidamente un algoritmo para entregar esta capacidad utilizando una plataforma de software de Edge Impulse.
La retinopatía diabética es una afección en la que se producen daños en los vasos sanguíneos de los tejidos ubicados en la parte posterior del ojo. Puede ocurrir en personas que son diabéticas y cuyo nivel de azúcar en sangre no se controla correctamente. En casos crónicos extremos, la retinopatía diabética puede provocar ceguera.
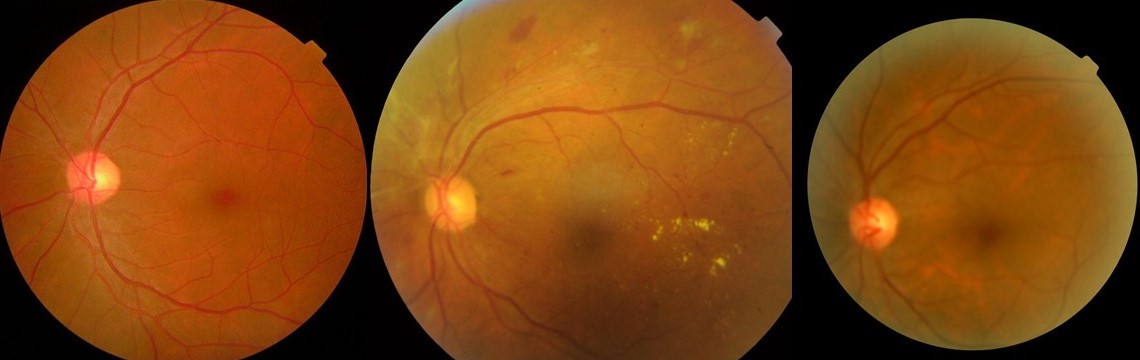
Más de dos de cada cinco estadounidenses con diabetes padecen alguna forma de retinopatía diabética. Eso hace que detectarlo temprano sea crítico, momento en el que se puede realizar una intervención médica o de estilo de vida. Para las áreas rurales de todo el mundo donde el acceso a la atención de la vista es limitado, las etapas de la retinopatía son aún más difíciles de detectar antes de que un caso se agrave. Con la detección de retinopatía diabética como objetivo, buscamos tomar datos médicos disponibles públicamente y entrenar un modelo de aprendizaje automático en Edge Impulse que pudiera ejecutar inferencias directamente en un dispositivo de borde. Idealmente, el algoritmo podría evaluar la gravedad de la retinopatía diabética entre imágenes de ojos tomadas por una cámara retiniana. El conjunto de datos que usamos para este proyecto se puede encontrar aquí.
Para este algoritmo, dividimos las clases en cinco conjuntos de datos diferentes:
- Sin retinopatía diabética (sin RD)
- RD leve
- RD moderada
- RD severa
- RD proliferativa
Al igual que con muchos conjuntos de datos disponibles públicamente, se tuvo que realizar una limpieza y etiquetado de datos.
Para proteger las identidades de los pacientes, a cada imagen del conjunto de datos se le asignó simplemente un id_code y un diagnóstico de 0 a 5, siendo 0 la gravedad más baja de No DR y 5 la peor, o DR proliferativa.
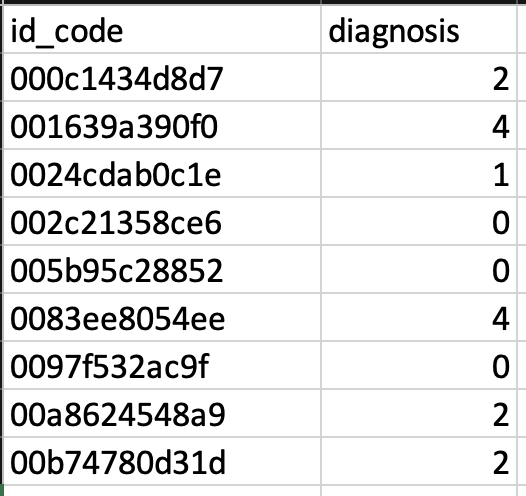
Para ingerir los datos en Edge Impulse, era necesario que se realizaran algunas particiones de las imágenes. Dada la naturaleza simple de cómo se dividieron los datos, decidí escribir un script VBA para leer la imagen id_code de Excel, tomar la imagen asociada y colocarla en su carpeta respectiva. El script para mover estos archivos está vinculado aquí. Para aquellos con mejores habilidades en Python u otros lenguajes de scripting, hay muchas formas de hacer esto que podrían ser incluso más simples.
Edge Impulse tiene otras funciones de ingestión de datos, como la integración del depósito de datos en la nube o la recopilación de datos de los dispositivos, pero la carga de datos fue el método que utilicé aquí. Usando la opción de carga de datos, pude traer a mis 5 clases diferentes una serie de cinco cargas. Cada carga consistió en que yo etiquetara los datos como una de las 5 clases y cargara las imágenes asociadas contenidas en cada carpeta.
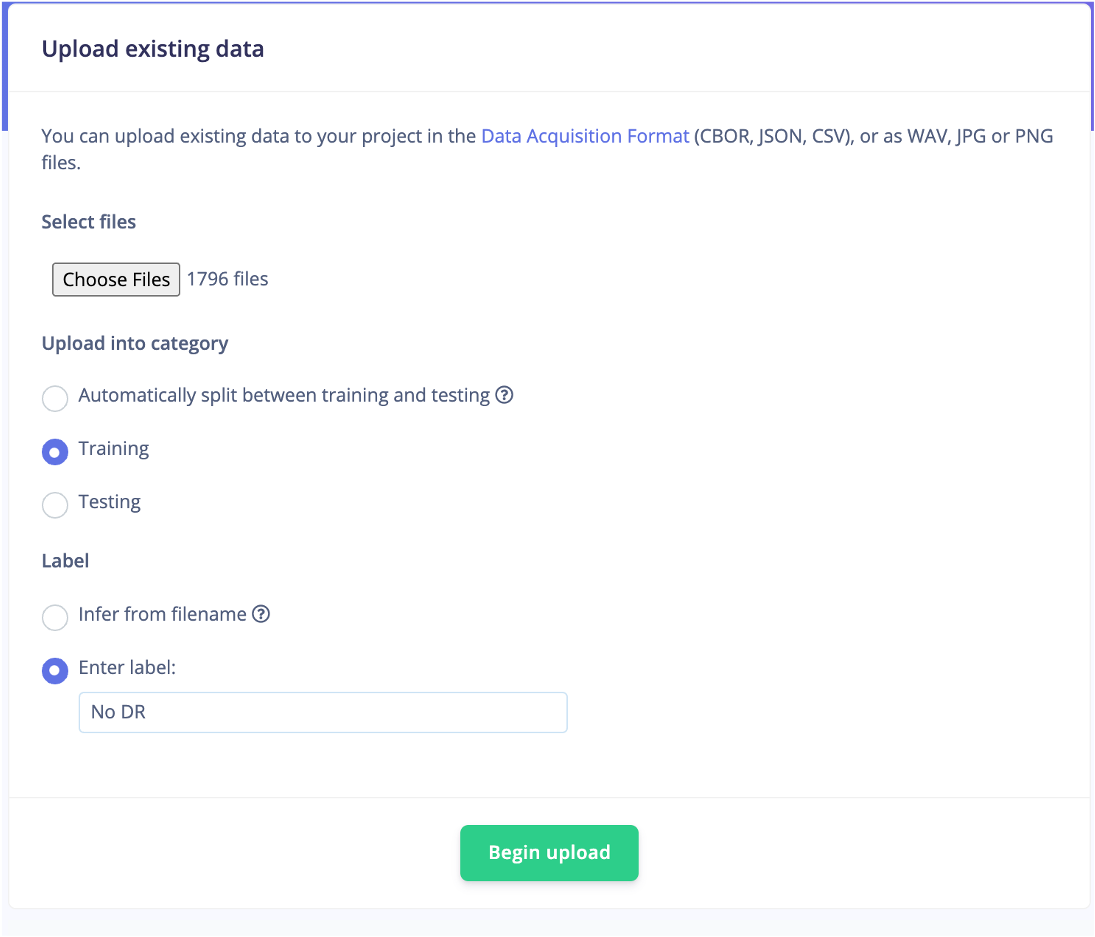
Edge Impulse tiene la opción de dividir automáticamente los datos en datos de entrenamiento o de prueba con una división 80/20. Sin embargo, agregué manualmente alrededor de 500 imágenes en las diferentes clases al conjunto de datos de prueba.
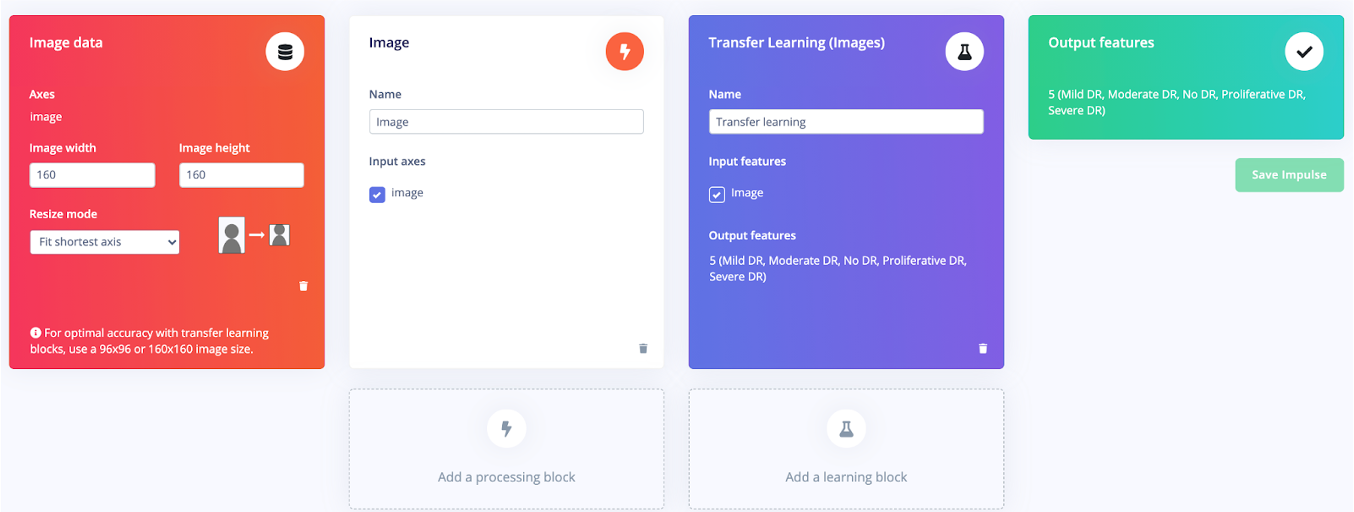
A continuación, llegó el momento de configurar mi modelo y elegir el bloque de procesamiento de señal y el bloque de red neuronal para este modelo. Para este modelo, introduje el bloque de imagen en un bloque de aprendizaje de transferencia con el objetivo de diferenciar entre cinco clases diferentes.
A partir de aquí, fui a entrenar la red neuronal. Jugando con la configuración de la red neuronal, la mejor precisión que obtuve fue de alrededor del 74%. No está mal, pero el modelo se estaba atascando en algunos de los casos extremos. Por ejemplo, la RD grave a veces se clasificaba como RD leve. El modelo no fue muy preciso a medida que avanzaba la recuperación de desastres, como puede ver en la captura de pantalla a continuación.
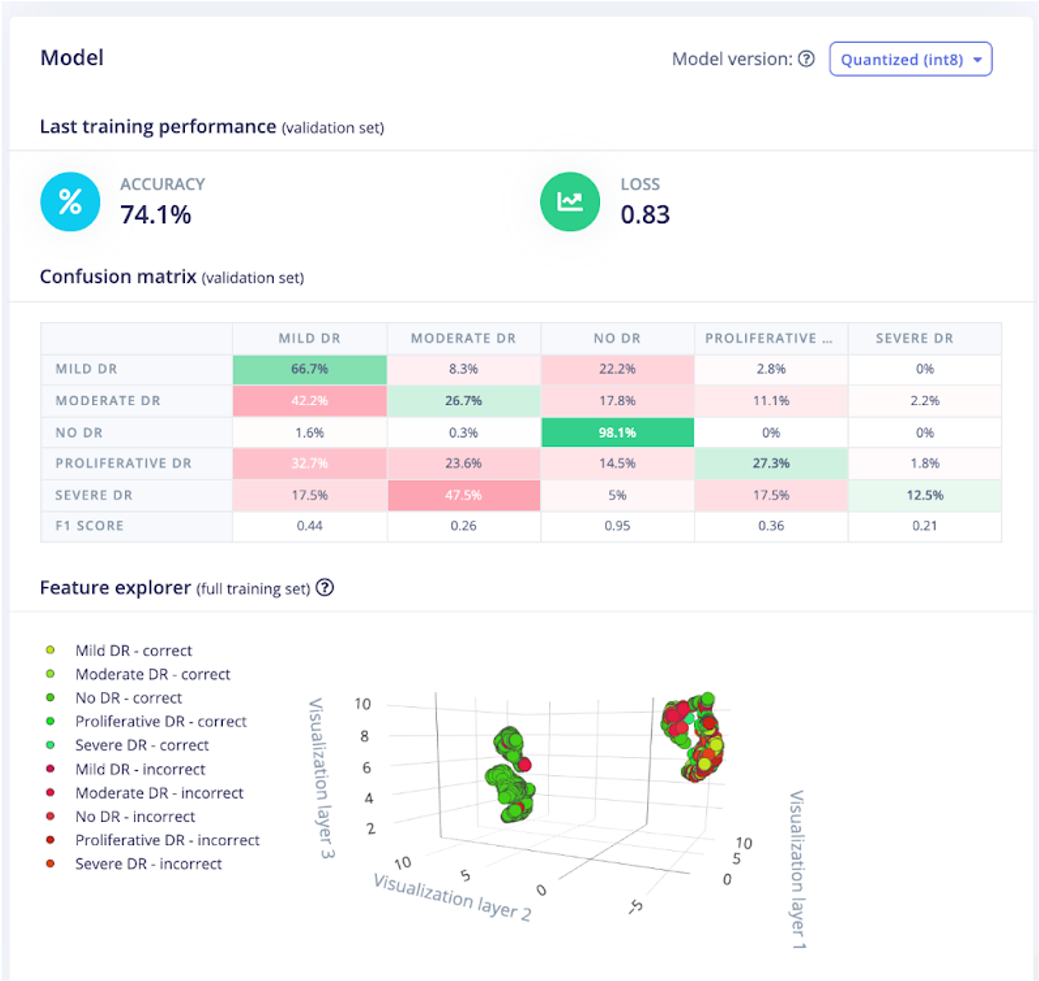
Esto me hizo pensar en las aplicaciones de la vida real de un proyecto como este y si este nivel de precisión sería aceptable. Idealmente, algún tipo de cámara de imágenes de retina portátil (en un entorno de baja conectividad inalámbrica) podría ejecutar un algoritmo como este en el propio dispositivo. Cuando se toma la imagen, se procesa y se emite un resultado, en ese momento la persona que administra la prueba ocular podría decirle al paciente que debe buscar más ayuda o intervención médica, según el resultado.
Para esta aplicación, es más importante detectar la RD en todas las etapas para que el paciente pueda comenzar algún tratamiento preventivo o, para los casos más graves, buscar ayuda médica inmediata. Dado este caso de uso, el modelo en realidad sirve para su aplicación potencial relativamente bien.
En la parte superior de mi cabeza, hay algunos cambios o mejoras que podría hacer en el modelo, que podrían hacer que el resultado resultante sea más preciso en términos de diagnóstico de la gravedad de la RD:
- Más datos siempre es mejor. Sin embargo, dado este conjunto de datos limitado, se necesitaría una mayor recopilación de datos.
- Una idea podría ser combinar clases, creando una clase leve-moderada y una clase proliferativa-severa. Me pregunto si eso podría ayudar al algoritmo a clasificar mejor, dadas las similitudes entre ciertos casos de RD leve y moderada, que ahora caerían en el mismo grupo.
Juegue con la cantidad de capas dentro de la red neuronal (NN), así como con el abandono.

Desde una perspectiva de implementación, este modelo entrenado tenía una huella más grande en términos de memoria, ocupando aproximadamente 306kB de Flash y 236kB de RAM. Dependiendo del dispositivo seleccionado para ejecutar la inferencia, la cantidad de tiempo necesario para que se proporcione un resultado de inferencia fue de 0,8 segundos a 6 segundos, cuando se realiza una evaluación comparativa en un Cortex-M4 a 80MHz o Cortex-M7 a 216MHz. Sin embargo, dado que este producto final necesitaría tomar imágenes, anticipo que se necesitaría algo como las capacidades de procesamiento de Cortex-M7 o superiores.
En resumen, utilizando un conjunto de datos de código abierto, pudimos entrenar un modelo de aprendizaje automático que funciona relativamente bien para detectar diversas formas de retinopatía diabética (RD). El objetivo final sería implementar modelos como este directamente en el microcontrolador integrado o dispositivo Linux y hacer que más dispositivos médicos como el siguiente ejecuten inferencias en el borde. Esto abre nuevas posibilidades para los servicios de atención médica, al proporcionar tecnología médica que se puede utilizar en áreas rurales, sin conectividad inalámbrica para proporcionar pruebas a las poblaciones que tienen poco acceso a la atención médica.
De hecho, existe una buena oportunidad para la implementación del aprendizaje automático integrado (ML) en dispositivos médicos. Más detalles sobre este proyecto, incluido el potencial de mejora adicional, están disponibles aquí.
Incrustado
- ¿Cómo fue descubierto y utilizado el titanio por los humanos?
- La nube y cómo está cambiando el mundo de las TI
- Filosofía y documentación
- Cuatro tipos de ciberataques y cómo prevenirlos
- Cómo prevenir problemas comunes con maquinaria y equipos pesados
- ¿Qué es la porosidad de soldadura y cómo prevenirla?
- ¿Qué es la oxidación y cómo prevenirla? Una guía completa
- Principales causas de fallas en las máquinas y cómo prevenirlas
- ¿Qué es la interoperabilidad y cómo puede lograrla mi empresa?
- Errores en la protección de máquinas y cómo prevenirlos
- Cómo detectar fugas y repararlas