


¿Qué es la informática sin servidor?
La gestión de la infraestructura agrega una capa adicional de complejidad al flujo de trabajo de desarrollo de software moderno. Mantener los servidores en funcionamiento, encargarse de las actualizaciones de seguridad y escalar los recursos requiere un tiempo valioso de los equipos de DevOps. Con la computación sin servidor, todas las operaciones de infraestructura están a cargo del proveedor de servicios. Como tal, serverless permite que los equipos de desarrollo se concentren en escribir código en lugar de dedicar demasiado tiempo a la administración de la infraestructura.
Este artículo explica qué es la computación sin servidor y cómo se compara con diferentes modelos de implementación en la nube. También exploraremos los pros y los contras de serverless y hablaremos sobre algunos casos de uso comunes.
¿Qué es la informática sin servidor?
La computación sin servidor es un método para implementar y ejecutar código en la nube sin ocuparse del aprovisionamiento de servidores y la administración de la infraestructura. A pesar de su nombre, serverless todavía se basa en servidores físicos o en la nube para la ejecución del código. Sin embargo, a los desarrolladores no les preocupa la infraestructura subyacente. Esto se deja en manos del proveedor sin servidor, que asigna dinámicamente los recursos informáticos necesarios y los administra en nombre del usuario.
Para los desarrolladores, esto significa cero tiempo dedicado a la administración, el mantenimiento, el escalado de recursos o la planificación de la capacidad del servidor. Simplemente cargan su código y dejan que el proveedor ejecute la lógica del lado del servidor en función de diferentes eventos o solicitudes. A diferencia de los modelos familiares de facturación en la nube, los servicios sin servidor se cobran según la cantidad de veces que se ejecuta el código o cuando se activa un determinado evento.
¿Cómo funciona la informática sin servidor?
En un entorno sin servidor, el código se activa mediante eventos y se ejecuta como una función. Esta es la razón por la cual el servidor sin servidor a menudo se asocia con "Funciones como servicio" o FaaS, que es un concepto similar. FaaS es un modelo de nube basado en eventos que maneja la lógica del lado del servidor para la ejecución del código sin ninguna intervención del usuario. Estos eventos pueden ser cualquier cosa, desde una simple solicitud HTTP, una llamada a la API, una consulta de la base de datos o la carga de un archivo.
Las funciones se ejecutan en contenedores sin estado. Esto significa que los recursos informáticos para ejecutar una función se aprovisionan solo cuando se invocan. No se conservan datos en la RAM ni se escriben en el disco. Una vez que se ha cumplido la solicitud, el estado de la aplicación se restablece y no hay memoria de la transacción. Hacer una nueva solicitud requiere que los recursos se aprovisionen desde cero y el código se ejecuta sin ninguna referencia a la invocación anterior.
Para adaptarse a este estado sin estado, las aplicaciones deben diseñarse como funciones que puedan ejecutarse en contenedores sin estado. Esto generalmente se logra a través de microservicios. Las aplicaciones monolíticas grandes se dividen en segmentos más pequeños y se interconectan a través de una API. Las aplicaciones monolíticas aún pueden ejecutarse como funciones individuales, pero esta no es una práctica común. Teniendo en cuenta que se aprovisiona un nuevo contenedor de cómputo en cada solicitud, las funciones grandes tendrán un impacto negativo en la velocidad y la duración de la ejecución.
Las funciones de FaaS no se ejecutan infinitamente. Se rescinden después de un cierto período de tiempo después de ser llamados. En la mayoría de los casos, las funciones se agotan después de unos cinco minutos. Esto significa que las aplicaciones que ejecutan tareas de larga duración deben rediseñarse para tener en cuenta los límites de terminación.
El aprovisionamiento e inicialización de contenedores para la ejecución de funciones también lleva tiempo. Esto generalmente se mide en milisegundos. Sin embargo, las funciones complejas pueden tardar varios segundos en inicializarse, lo que provoca una mayor latencia.
Hay dos métodos comunes para inicializar una función:arranque en caliente y arranque en frío. Un inicio de advertencia reutiliza los recursos de un evento anterior, mientras que un inicio en frío implementa un nuevo contenedor. El tiempo que lleva inicializar y ejecutar una función dependerá de la cantidad de código, el lenguaje de programación, la cantidad de bibliotecas que usa el script, así como muchos otros factores. En términos de latencia, un inicio en frío tarda más en iniciar una función.

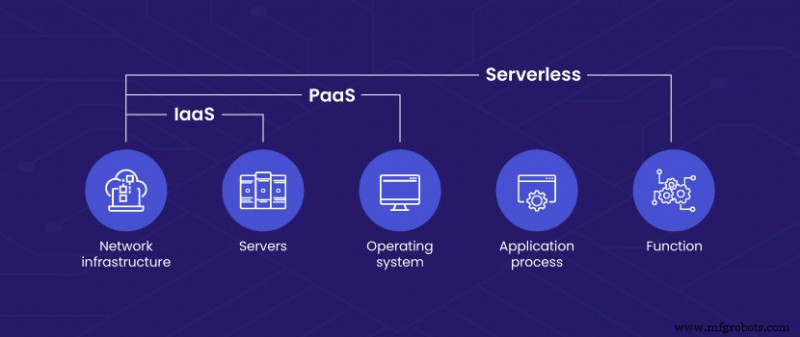
¿Cómo se compara la computación sin servidor con BaaS, PaaS e IaaS?
Como ocurre con cualquier tendencia de software, no existe una definición oficial que describa qué es serverless y qué no. Es por eso que la computación sin servidor a menudo se confunde con otros servicios en la nube y modelos de implementación. El concepto de computación sin servidor gira en torno a dos áreas similares:
Backend como servicio — BaaS permite que los desarrolladores se concentren en escribir interfaces frontend mientras descargan todas las operaciones backend a un proveedor de servicios. Estas tareas tras bambalinas generalmente involucran autenticación de usuarios, almacenamiento, administración de bases de datos y servicios de alojamiento listos para usar. Además, los desarrolladores no tienen que administrar los servidores que ejecutan su backend, lo que permite implementaciones de aplicaciones más rápidas.
Funciones como servicio — Este modelo de servicio en la nube sin servidor elimina la administración de la infraestructura. El proveedor de servicios tiene la tarea de implementar recursos informáticos bajo demanda para ejecutar el código de los usuarios. Esto sucede cada vez que se activa un evento o una solicitud. Las funciones sin servidor se ejecutan en contenedores sin estado, lo que significa que los recursos informáticos se implementan solo cuando se invoca la función.
El principal punto de confusión es entre Backend-as-a-Service y Platform-as-a-Service (PaaS). La primera es una técnica de computación sin servidor, mientras que la segunda es un modelo de implementación en la nube. Aunque comparten algunas características básicas, PaaS no está alineado con los requisitos de serverless.
Plataforma como servicio — Con PaaS, los usuarios alquilan las soluciones de hardware y software necesarias para las cargas de trabajo de desarrollo de un proveedor de servicios por una tarifa de suscripción. Permite a los desarrolladores pasar más tiempo codificando sin preocuparse por la gestión de la infraestructura. Por otro lado, BaaS ofrece funciones adicionales, como autenticación de usuario lista para usar, bases de datos administradas, notificaciones por correo electrónico y similares. BaaS también permite que los desarrolladores se concentren únicamente en construir la interfaz mientras integran varios servicios de backend a pedido.
Infraestructura como servicio — IaaS se refiere a una solución de nube de autoservicio en la que el proveedor aloja la infraestructura en nombre del usuario. Todas las operaciones de aprovisionamiento y administración del servidor, incluida la instalación del software, están a cargo del usuario. Algunos proveedores de IaaS también ofrecen soluciones sin servidor, pero como productos claramente diferentes.
Casos comunes de uso de informática sin servidor
Como se mencionó anteriormente, la tecnología sin servidor no es para todos. Pero si sus necesidades están alineadas con algunos de estos casos de uso, podría beneficiarse de la tecnología sin servidor.
Creación de API
Sin servidores que administrar, la creación de API altamente escalables y con capacidad de respuesta es uno de los casos de uso más populares para la tecnología sin servidor. La función de escalado automático de serverless garantiza que las API siempre estarán disponibles incluso con mucho tráfico. Además de esto, al usuario no se le cobra por los recursos inactivos cuando no hay llamadas a la API.
Sitios web y aplicaciones
La implementación de sitios web y aplicaciones basadas en la web en una plataforma sin servidor no requiere ninguna configuración de infraestructura previa. Esto reduce significativamente el tiempo que lleva lanzar una aplicación web completamente funcional. La función de escalado automático también juega un papel importante aquí porque el usuario no necesita preocuparse por aprovisionar más servidores para soportar los aumentos en la demanda. Como resultado, es mucho más fácil mantener un 100 % de tiempo de actividad.
Aplicaciones en varios idiomas
Con serverless, una sola aplicación se puede escribir en varios idiomas. Serverless permite a los desarrolladores dividir una aplicación monolítica en partes más pequeñas y ejecutarlas como microservicios. Esos microservicios luego se comunican entre sí a través de una API. Cada segmento de una aplicación se puede escribir usando un lenguaje de programación diferente.
Canalizaciones de CI/CD
La automatización es clave para ejecutar con éxito canalizaciones de desarrollo, prueba e integración. Serverless permite a los desarrolladores probar automáticamente el código y corregir errores más rápido. Dado que serverless se basa en eventos, los usuarios pueden configurar eventos para activar pruebas automatizadas sin ninguna intervención manual.
¿Cuáles son las ventajas de la informática sin servidor?
En comparación con la computación en la nube tradicional orientada al servidor, la computación sin servidor abstrae las operaciones de infraestructura. Todo funciona listo para usar, lo que a su vez garantiza lanzamientos de código más rápidos y escalabilidad automatizada a un precio más bajo.
Estos son los tres beneficios más comunes de serverless:
Escalado automático
El proveedor sin servidor escala los recursos de infraestructura en función de la demanda. Las operaciones de escalado se realizan de forma dinámica y automática sin ninguna intervención de los desarrolladores.
Tiempo de comercialización más rápido
Sin necesidad de aprovisionar clústeres de servidores complejos, los desarrolladores pueden concentrarse más en lograr una mayor velocidad de lanzamiento. Esto acelera el tiempo que lleva lanzar el código a producción o implementar cambios de código incrementales, lo que resulta en una entrega más rápida de aplicaciones a los clientes.
Costos optimizados
Dado que todo se aprovisiona bajo demanda, las organizaciones nunca tienen que pagar por el espacio de almacenamiento no utilizado, el tiempo de cómputo o las redes. El consumo de servicios sin servidor generalmente se mide en milisegundos y se factura en consecuencia.
¿Cuáles son los inconvenientes de la informática sin servidor?
Al igual que con cualquier solución de software, la tecnología sin servidor también tiene algunas desventajas. Pero dependiendo de la aplicación que esté creando, es posible que no le preocupen tanto algunos de estos inconvenientes de la tecnología sin servidor.
Latencia
Al ejecutar una función, los proveedores sin servidor implementan automáticamente los recursos necesarios en cada invocación. Según el tamaño de la carga de trabajo, los contenedores suelen aprovisionarse en milisegundos, pero incluso pueden tardar varios segundos. La latencia se puede reducir a través de "inicios de advertencia" que reutilizan instancias de una ejecución anterior.
Duración de ejecución
El tiempo de ejecución de una función sin servidor es limitado y se cancela después de un período determinado. Esto suele ser alrededor de cinco minutos después de la invocación, pero varía según los proveedores. Los límites de ejecución son un gran inconveniente para las aplicaciones que inician procesos de larga duración. Es posible mitigar este problema segmentando el código en fragmentos más pequeños y ejecutándolos como microservicios.
Fijación de proveedor
Los proveedores suelen utilizar tecnologías patentadas para habilitar sus servicios sin servidor. Esto puede causar problemas a los usuarios que deseen migrar sus cargas de trabajo a otra plataforma. Al cambiar de proveedor, los cambios en el código y la arquitectura de la aplicación son inevitables.
Seguridad
Los usuarios tienen poco control sobre la configuración de la instancia que ejecuta su código. Esto está oculto para el usuario y cae en el ámbito del proveedor de servicios. Como tal, las operaciones de seguridad también caen en manos del proveedor. El usuario está indefenso si ocurre un ataque, confiando únicamente en el proveedor para mitigar el daño y recuperar el sistema. Las aplicaciones que tienen varios puntos de entrada en un entorno sin servidor son más propensas a las vulnerabilidades debido a una mayor superficie de ataque.
¿Cuál es el futuro de la informática sin servidor?
La informática sin servidor sigue siendo una tecnología relativamente nueva. Su futuro depende de la capacidad de los proveedores de servicios para resolver algunos de los inconvenientes enumerados anteriormente, el más importante, los arranques en frío. Los proveedores deben reducir el tiempo que lleva ejecutar una función después de que haya estado inactiva durante un tiempo. Resolver este problema disminuirá la latencia y garantizará una experiencia de usuario perfecta.
Serverless actualmente se basa en contenedores sin estado para la ejecución de funciones. El futuro de la tecnología sin servidor se está moviendo hacia la habilitación de aplicaciones con estado para aprovechar los beneficios de la tecnología sin servidor. Esto permitirá a los desarrolladores crear aplicaciones con estado sin preocuparse por la administración de datos de back-end.
En términos de DevOps, serverless conducirá a la expansión de NoOps. Esta tendencia conducirá a que los proveedores sin servidor manejen todas las operaciones de infraestructura en nombre del cliente. En tal entorno, no es necesario que las empresas tengan equipos de operaciones internos.
En los próximos años, se espera que Kubernetes se convierta en la base de serverless. Con soporte para redes, escalado automático ágil e implementaciones de múltiples nubes, la portabilidad de Kubernetes mejora la informática sin servidor en más de un sentido. Ejecutar ciertas clases de aplicaciones sin servidor no es práctico ya que los proveedores de servicios a veces limitan su comportamiento. Con Kubernetes, los desarrolladores podrán superar esas limitaciones y crear plataformas sin servidor en función de sus necesidades específicas.
Conclusión
Aunque el nombre sugiere la ausencia de servidores, la computación sin servidor todavía se basa en servidores físicos o en la nube. Es un modelo informático que elimina las operaciones de infraestructura, lo que permite a los desarrolladores centrarse en escribir e implementar aplicaciones. El modelo sin servidor gira en torno a dos áreas clave:backend como servicio y funciones como servicio.
El primero proporciona a los usuarios una arquitectura de back-end lista para usar, mientras que el segundo permite ejecutar aplicaciones en contenedores sin estado. Estos contenedores se aprovisionan automáticamente en función de eventos o activadores. Como tal, serverless no es una solución milagrosa para todos los problemas de desarrollo actuales. Está orientado principalmente a aplicaciones no monolíticas que emplean una arquitectura basada en microservicios.
Computación en la nube
- Computación sin servidor:la última oferta "como servicio"
- ¿Cuáles son los mejores cursos de computación en la nube?
- ¿Qué es la computación en la nube y cómo funciona?
- ¿Cuál es la relación entre big data y computación en la nube?
- Los obstáculos más grandes para una adopción sin servidor más amplia
- Computación en la nube frente a las instalaciones
- Qué es la codificación:funcionamiento, idiomas y sus desafíos
- ¿Qué es A2 Steel?
- ¿Qué es la computación perimetral y por qué es importante?
- ¿Qué es la computación cuántica?
- ¿Cuál es el código HS para bomba hidráulica?