


Nota clave sobre el aprendizaje automático y sus cuatro tipos principales para principiantes
Sin duda, Big Data es una parte importante del futuro desarrollo tecnológico. Sin embargo, el aprendizaje automático (ML) y la inteligencia artificial (IA) juegan un papel importante en este desarrollo. La relación entre estos tres se explica brevemente:Big data es para los materiales, el aprendizaje automático es para el método y la inteligencia artificial es para los resultados.
¿Qué es el aprendizaje automático?
El aprendizaje automático (ML) es uno de los tipos de inteligencia artificial (IA) en el que los algoritmos se escriben de tal manera que el sistema tiene la capacidad de aprender, adaptarse y mejorar automáticamente a través de la experiencia sin ser programado explícitamente. .
Los algoritmos de aprendizaje automático construyen un modelo ejemplar que se basa en el tipo de datos que está destinado a aprender, este tipo de datos se denomina "datos de entrenamiento".
¿Tipos de aprendizaje automático?
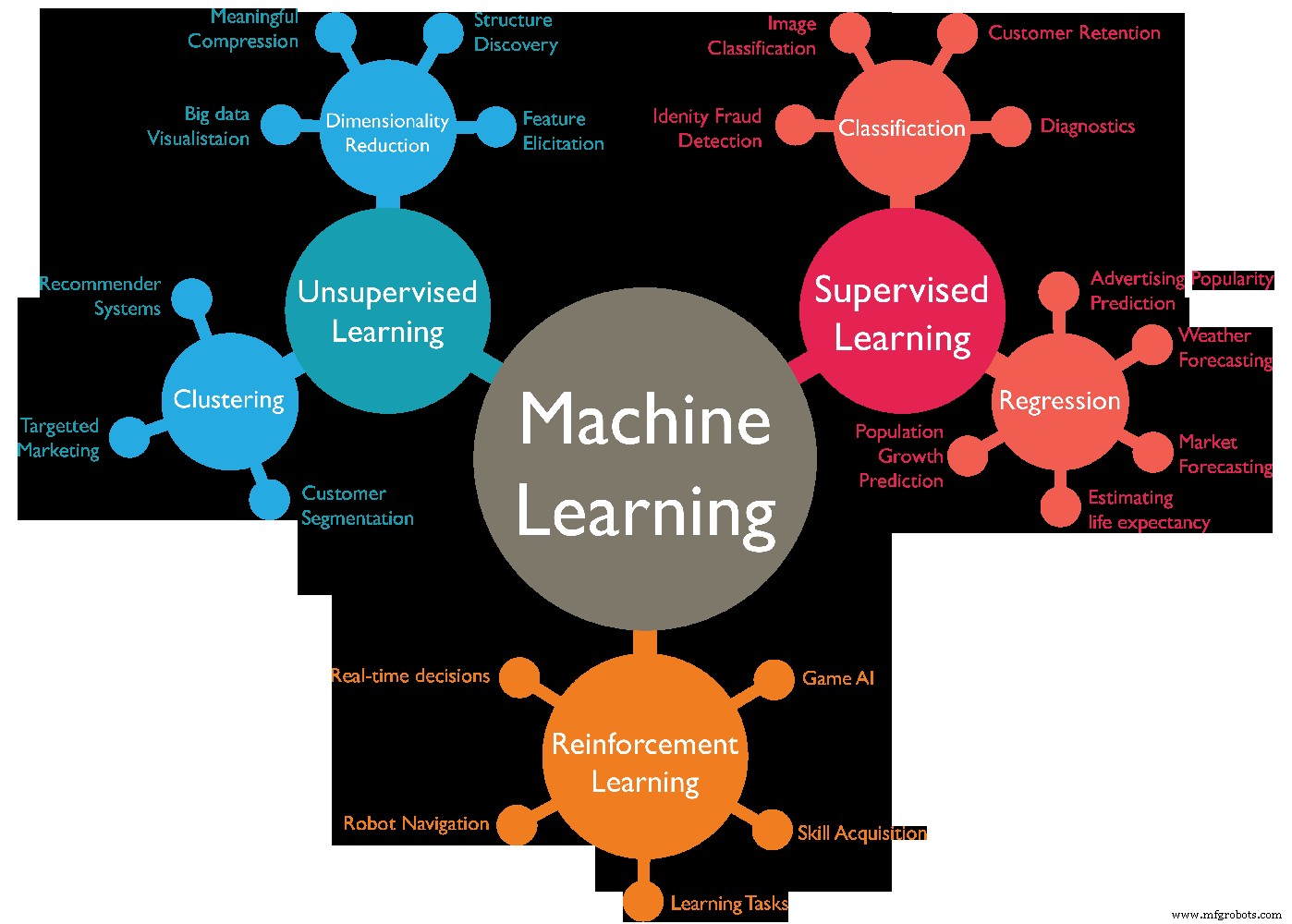
Hay varios tipos de algoritmos de aprendizaje automático, por lo general se pueden dividir en 4 categorías, los diferentes tipos de aprendizaje automático son los siguientes:-
- Aprendizaje supervisado.
- Aprendizaje no supervisado.
- Aprendizaje semisupervisado.
- Aprendizaje por refuerzo.
Aprendizaje supervisado
Cuando la máquina está siendo supervisada mientras está en su etapa de “aprendizaje”, este tipo de entrenamiento se denomina aprendizaje supervisado. ¿Qué queremos decir realmente cuando decimos que una máquina está siendo supervisada? ?. Lo que realmente significa aplicar algoritmos de tal manera que le permita a la máquina aprender a usar sus datos antiguos (datos proporcionados en el pasado) y usarlos para hacer predicciones de eventos futuros relacionados con el tipo de datos ingresados, es decir, datos antiguos.
Se inicia el análisis y todos los materiales en el conjunto de datos de entrenamiento y etiquetados se correlacionan con la máquina de tal manera que puede hacer una predicción de los valores de salida correctos. Significa que le proporcionamos a la máquina mucha información sobre un caso en particular y luego proporciona un resultado del caso. El resultado se denomina datos etiquetados, mientras que el resto de la información se utiliza como características de entrada. El sistema también puede proporcionar objetivos para nuevas entradas después de un entrenamiento suficiente. El algoritmo puede comparar su salida con la salida prevista y encontrar diferencias para cambiar el modelo en consecuencia.
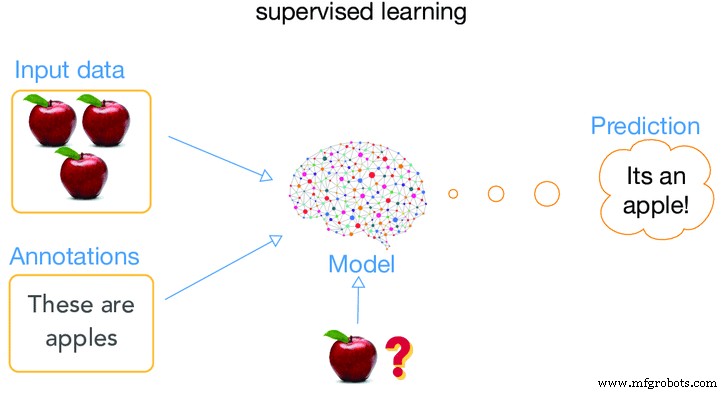
imagen cortesía de artificialintelligence.oodles.io/
La mayoría de las veces, este método es una clasificación manual, que es la más fácil de realizar para una computadora y la más difícil para los humanos. Un ejemplo de este método es decirle a la máquina respuestas estándar, y cuando se prueba la máquina, la máquina siempre responderá de acuerdo con la respuesta estándar y, por lo tanto, su confiabilidad también será mayor.
Aprendizaje no supervisado
En contraste con el aprendizaje supervisado, los algoritmos de aprendizaje no supervisado se usan cuando la información que se usa para entrenar la máquina no está clasificada ni etiquetada, como sugiere el nombre en el aprendizaje no supervisado, el usuario no ofrece ayuda a la computadora para ayudar. aprende.
El material proporcionado no tiene etiqueta, y la máquina luego compara las características de los datos y clasifica los materiales. Debido a la falta de conjuntos de entrenamiento etiquetados, la máquina identifica patrones en los datos que no son tan obvios para los humanos.
imagen cortesía de data-flair.training/En este método, no hay ninguna clasificación manual, que es la más fácil para los humanos, pero la más difícil para la computadora y puede causar muchos más errores. En su mayoría, el sistema no determina la salida prevista, pero investiga los datos proporcionados y puede dibujar relaciones de conjuntos de datos para describir estructuras ocultas de datos no etiquetados. Por lo tanto, reconocer patrones en los datos de aprendizaje no supervisado es extremadamente útil y también nos ayuda a tomar decisiones.
Aprendizaje semisupervisado
El aprendizaje semisupervisado es diferente al aprendizaje supervisado y al aprendizaje no supervisado en el que no hay etiquetas presentes para toda la observación de datos o las etiquetas están presentes.
En semisupervisado, tanto los datos etiquetados (supervisados) como los no etiquetados (no supervisados) se utilizan para el entrenamiento. SSL es una combinación de los dos tipos de aprendizaje en los que se etiqueta una pequeña cantidad de datos y se desetiquetan grandes cantidades de datos. Se requiere que la máquina encuentre características a través de datos etiquetados y luego, utilizando el modelo base, clasifica otros datos en consecuencia. Los sistemas SSL pueden mejorar considerablemente no solo su precisión de aprendizaje, sino que también pueden hacer predicciones más precisas.
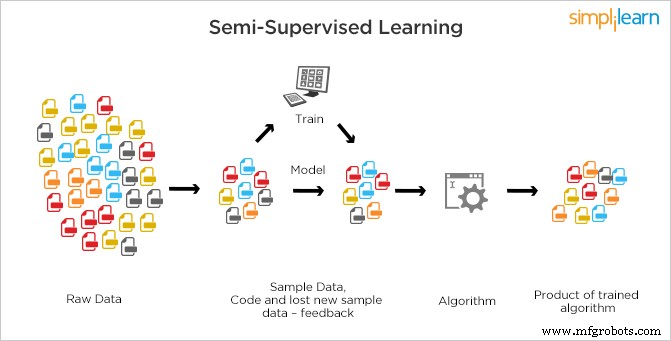
Es el método más utilizado porque el costo de etiquetar es alto ya que se requieren expertos humanos calificados. Requiere recursos relevantes para capacitarlo y aprender de él, mientras que la adquisición de datos no etiquetados generalmente no requiere recursos adicionales. Debido a la falta de etiquetas en la mayoría de las observaciones, pero a la presencia de unos pocos, se prefieren los algoritmos semisupervisados como los mejores candidatos para construir un modelo.
Estos métodos se benefician de la idea de que, aunque los miembros del grupo son desconocidos porque los datos no etiquetados son más generales, la información sobre los parámetros aún se encuentra en los etiquetados y se puede encontrar usándolos.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es lo más parecido a cómo aprendemos los humanos. Los algoritmos RML son un método de aprendizaje en el que la máquina interactúa repetidamente con su entorno mediante la construcción de nuevas acciones y descubre errores o recompensas. Utiliza un sistema basado en recompensas positivas o negativas.
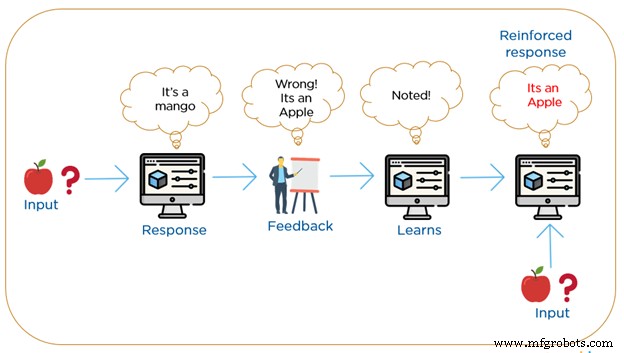
La búsqueda por ensayo y error con recompensa diferida es la característica más relevante del aprendizaje por refuerzo. La máquina construye un comportamiento utilizando observaciones recopiladas al interactuar con el entorno y toma acciones que maximizarían la recompensa o minimizarían el riesgo. Este método permite que las máquinas determinen automáticamente el comportamiento ideal dentro de un determinado contexto para aumentar su rendimiento. En el aprendizaje por refuerzo, no hay materiales etiquetados, sino que requiere una retroalimentación simple sobre qué paso es correcto y qué paso es incorrecto, esto se conoce como la señal de refuerzo.

De acuerdo con el estándar de retroalimentación, la máquina revisa gradualmente su clasificación hasta que finalmente obtiene el resultado correcto. La integración del aprendizaje por refuerzo es necesaria para lograr un cierto nivel de precisión en el aprendizaje no supervisado,
RML es probablemente el más difícil de producir y ejecutar en un entorno empresarial, pero se usa comúnmente para automóviles autónomos.
Tecnología Industrial
- La cadena de suministro y el aprendizaje automático
- Cuatro preguntas clave para desbloquear el poder de los datos de campo en vivo
- Elementary Robotics recauda $ 13 millones para sus ofertas de aprendizaje automático y visión por computadora para la industria
- Aprendizaje automático en el campo
- El papel del análisis de datos para propietarios de activos en la industria del petróleo y el gas
- Los muchos tipos de poliuretano y para qué se utilizan
- AWS fortalece sus ofertas de inteligencia artificial y aprendizaje automático
- ¿Qué es una fresadora y para qué sirve?
- Kepware vs. MachineMetrics:¿Cuál es la mejor solución para la recopilación de datos de máquinas?
- Las 9 aplicaciones de aprendizaje automático que debes conocer
- La Máquina Molino y sus Diferentes Subcategorías