


Aprovechamiento de FPGA para el aprendizaje profundo
Recientemente asistí al Foro de Desarrollo Xilinx 2018 (XDF) en Silicon Valley. Mientras estaba en este foro, me presentaron a una empresa llamada Mipsology, una startup en el campo de la inteligencia artificial (IA) que afirma haber resuelto los problemas relacionados con la IA asociados con las matrices de puertas programables de campo (FPGA). Mipsology se fundó con la gran visión de acelerar el cálculo de cualquier red neuronal (NN) con el rendimiento más alto posible en FPGA sin las limitaciones inherentes a su implementación.
Mipsology demostró la capacidad de ejecutar más de 20.000 imágenes por segundo, ejecutándose en las placas Alveo recientemente anunciadas de Xilinx y procesando una colección de NN, incluidos ResNet50, InceptionV3, VGG19, entre otros.
Introducción a las redes neuronales y el aprendizaje profundo
Modelada libremente en la red de neuronas del cerebro humano, una red neuronal es la base del aprendizaje profundo (DL), un sistema matemático complejo que puede aprender tareas por sí solo. Al observar muchos ejemplos o asociaciones, una NN puede aprender conexiones y relaciones más rápido que un programa de reconocimiento tradicional. El proceso de configurar una NN para realizar una tarea específica basada en aprendizaje millones de muestras del mismo tipo se denomina formación .
Por ejemplo, un NN puede escuchar muchas muestras vocales y usar DL para aprender a "reconocer" los sonidos de palabras específicas. Luego, este NN podría examinar una lista de nuevas muestras vocales e identificar correctamente las muestras que contienen palabras que ha aprendido, utilizando una técnica llamada inferencia .
A pesar de su complejidad, DL se basa en realizar operaciones sencillas, en su mayoría sumas y multiplicaciones, de miles de millones o billones. La demanda computacional para realizar tales operaciones es abrumadora. Más específicamente, las necesidades informáticas para ejecutar inferencias de DL son mayores que las del entrenamiento de DL. Mientras que el entrenamiento de DL debe realizarse solo una vez, un NN, una vez entrenado, debe realizar inferencias una y otra vez para cada nueva muestra que reciba.
Cuatro opciones para acelerar la inferencia de aprendizaje profundo
Con el tiempo, la comunidad de ingenieros recurrió a cuatro dispositivos informáticos diferentes para procesar las NN. En orden creciente de potencia de procesamiento y consumo de energía, y en orden decreciente de flexibilidad / adaptabilidad, estos dispositivos abarcan:unidades centrales de procesamiento (CPU), unidades de procesamiento de gráficos (GPU), FPGA y circuitos integrados específicos de la aplicación (ASIC). La siguiente tabla resume las principales diferencias entre los cuatro dispositivos informáticos.
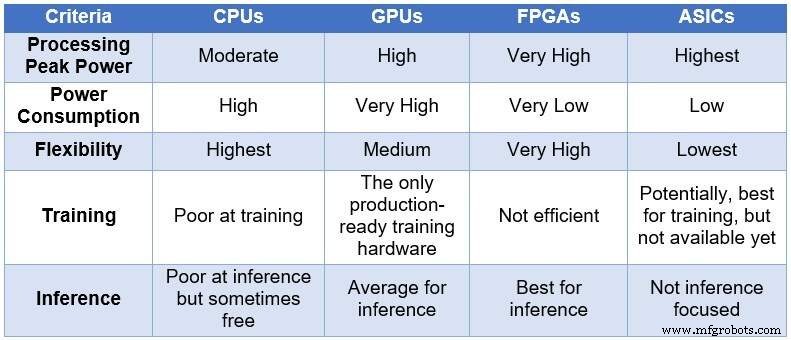
Comparación de CPU, GPU, FPGA y ASIC para computación DL (Fuente:Lauro Rizzatti)
Las CPU se basan en la arquitectura de Von Neuman. Si bien son flexibles (la razón de su existencia), las CPU se ven afectadas por una latencia prolongada debido a que los accesos a la memoria consumen varios ciclos de reloj para ejecutar una tarea simple. Cuando se aplican a tareas que se benefician de las latencias más bajas, como el cálculo de NN y, específicamente, el entrenamiento y la inferencia de DL, son la opción más pobre.
Las GPU brindan un alto rendimiento de cómputo a costa de una menor flexibilidad. Además, las GPU consumen una cantidad significativa de energía que exige refrigeración, lo que las hace menos ideales para su implementación en centros de datos.
Si bien los ASIC personalizados pueden parecer una solución ideal, tienen sus propios problemas. Desarrollar un ASIC lleva años. DL y NN están evolucionando rápidamente con avances continuos, lo que hace que la tecnología del año pasado sea irrelevante. Además, para competir con una CPU o una GPU, un ASIC necesitaría usar una gran área de silicio utilizando la tecnología de nodo de proceso más delgada. Esto encarece la inversión inicial, sin ninguna garantía de relevancia a largo plazo. Todos considerados, los ASIC son efectivos para tareas específicas.
Los dispositivos FPGA se han convertido en la mejor opción posible para la inferencia. Son rápidos, flexibles, energéticamente eficientes y ofrecen una buena solución para el procesamiento de datos en los centros de datos, especialmente en el mundo dinámico de DL, en el borde de la red y debajo del escritorio de los científicos de inteligencia artificial.
Los FPGA más grandes disponibles en la actualidad incluyen millones de operadores booleanos simples, miles de memorias y DSP, y varios núcleos ARM de CPU. Todos estos recursos funcionan en paralelo:cada tic del reloj activa hasta millones de operaciones simultáneas, lo que da como resultado billones de operaciones realizadas en cada segundo. El procesamiento requerido por DL se asigna bastante bien a los recursos FPGA.
Las FPGA tienen otras ventajas sobre las CPU y GPU utilizadas para DL, incluidas las siguientes:
-
No se limitan a ciertos tipos de datos. Pueden manejar una baja precisión no estándar más adecuada para ofrecer un mayor rendimiento para DL.
-
Usan menos energía que las CPU o GPU, generalmente de cinco a 10 veces menos energía promedio para el mismo cálculo NN. Su costo recurrente en los centros de datos es menor.
-
Pueden reprogramarse para adaptarse a cualquier tarea, pero deben ser lo suficientemente genéricos para adaptarse a diversas empresas. DL está evolucionando rápidamente y el mismo FPGA se ajustará a los nuevos requisitos sin necesidad de silicio de próxima generación (que es típico de los ASIC), lo que reduce el costo de propiedad.
-
Varían desde dispositivos grandes a pequeños. Se pueden utilizar en centros de datos o en un nodo de Internet de las cosas (IoT). La única diferencia es la cantidad de bloques que contienen.
Todo lo que brilla no es oro
La alta potencia computacional, el bajo consumo de energía y la flexibilidad de una FPGA tienen un precio:dificultad para programar.
Tecnología de Internet de las cosas
- El informe ETSI allana el camino para estandarizar la seguridad de la IA
- CEVA:procesador de inteligencia artificial de segunda generación para cargas de trabajo de redes neuronales profundas
- Defensa de los chips neuromórficos para la informática de IA
- ICP:tarjeta aceleradora basada en FPGA para inferencia de aprendizaje profundo
- IA subcontratada y aprendizaje profundo en la industria de la salud:¿está en riesgo la privacidad de los datos?
- Cómo la industria de alta tecnología está aprovechando la inteligencia artificial para el crecimiento empresarial exponencial
- Inteligencia artificial frente a aprendizaje automático frente a aprendizaje profundo | La diferencia
- Equipo de Apple e IBM Watson para aprendizaje automático móvil empresarial
- Deep Learning y sus múltiples aplicaciones
- Solución de estabilidad de herramientas para taladrado profundo
- Cómo el aprendizaje profundo automatiza la inspección para la industria de las ciencias biológicas