


Compiladores en el extraño mundo de la seguridad funcional
En todos los sectores, el mundo de la seguridad funcional impone nuevos requisitos a los desarrolladores. El código funcionalmente seguro debe incluir un código defensivo para defenderse de eventos inesperados que pueden resultar de una variedad de causas. Por ejemplo, la corrupción de la memoria debido a errores de codificación o eventos de rayos cósmicos puede llevar a la ejecución de rutas de código que son "imposibles" de acuerdo con la lógica del código. Los lenguajes de alto nivel, particularmente C y C ++, incluyen una sorprendente cantidad de características cuyo comportamiento no está prescrito por la especificación del lenguaje al que se adhiere el código. Este comportamiento indefinido puede conducir a resultados inesperados y potencialmente desastrosos que serían inaceptables en una aplicación funcionalmente segura. Por estas razones, los estándares requieren que se aplique codificación defensiva, que el código sea comprobable, que sea posible recopilar una cobertura de código adecuada y que el código de la aplicación sea rastreable hasta los requisitos para garantizar que el sistema los implemente de forma completa y única.
El código también debe alcanzar altos niveles de cobertura de código y, en algunos sectores, en particular el automotriz, es común que el diseño requiera herramientas de desarrollo, calibración y diagnóstico externo sofisticadas. El problema que surge es que prácticas como la codificación defensiva y el acceso a datos externos no forman parte de un mundo que los compiladores reconocen. Por ejemplo, ni C ni C ++ tienen en cuenta la corrupción de la memoria, por lo que, a menos que se pueda acceder al código diseñado para proteger contra ella cuando no existe dicha corrupción, simplemente se puede ignorar cuando el código está optimizado. En consecuencia, el código defensivo debe ser accesible sintácticamente y semánticamente si no se va a "optimizar".
Los casos de comportamiento indefinido también pueden causar sorpresas. Es fácil sugerir que simplemente deben evitarse, pero a menudo es difícil identificarlos. Donde existen, no puede haber garantía de que el comportamiento del código ejecutable compilado coincida con las intenciones de los desarrolladores. El acceso "por la puerta trasera" a los datos utilizados por las herramientas de depuración representa otra situación que el lenguaje no tiene en cuenta y, por lo tanto, puede tener consecuencias inesperadas.
La optimización del compilador puede tener un impacto importante en todas estas áreas, porque ninguna de ellas es parte del mandato de los proveedores de compiladores. La optimización puede resultar en la eliminación de un código defensivo aparentemente sólido cuando está asociado con la "inviabilidad", es decir, cuando existe en rutas que no pueden ser probadas y verificadas por ningún conjunto de posibles valores de entrada. Aún más alarmante, el código defensivo que se muestra presente durante las pruebas unitarias puede eliminarse cuando se construye el ejecutable del sistema. El hecho de que se haya logrado la cobertura del código defensivo durante la prueba unitaria no garantiza que esté presente en el sistema completo.
En esta extraña tierra de seguridad funcional, el compilador puede estar fuera de su elemento. Es por eso que la verificación de código objeto (OCV) representa la mejor práctica para cualquier sistema para el que existen graves consecuencias asociadas con la falla, y de hecho, para cualquier sistema donde solo las mejores prácticas son suficientemente buenas.
Antes y después de la compilación
Las prácticas de verificación y validación defendidas por la seguridad funcional, la protección y los estándares de codificación como IEC 61508, ISO 26262, IEC 62304, MISRA C y C ++ ponen un énfasis considerable en mostrar la cantidad de código fuente de la aplicación que se ejerce durante las pruebas basadas en requisitos.
La experiencia nos ha demostrado que si se ha demostrado que el código funciona correctamente, la probabilidad de falla en el campo es considerablemente menor. Y, sin embargo, debido a que el enfoque de este loable esfuerzo está en el código fuente de alto nivel (sin importar el idioma), tal enfoque deposita mucha fe en la capacidad del compilador para crear código objeto que reproduzca precisamente lo que los desarrolladores destinado a. En las aplicaciones más críticas, esa suposición implícita no puede justificarse.
Es inevitable que el control y el flujo de datos del código objeto no sea un espejo exacto del código fuente del que se derivó, por lo que demostrar que todas las rutas del código fuente se pueden ejercer de manera confiable no prueba lo mismo del código objeto. . Dado que existe una relación 1:1 entre el código objeto y el ensamblador, una comparación entre el código fuente y el ensamblador es reveladora. Considere el ejemplo que se muestra en la Figura 1, donde el código ensamblador de la derecha se ha generado a partir del código fuente de la izquierda (utilizando un compilador de TI con la optimización desactivada).

Figura 1:El código ensamblador de la derecha se ha generado a partir del código fuente de la izquierda, mostrando la comparación reveladora entre el código fuente y el ensamblador. (Fuente:LDRA)
Como se ilustra más adelante, cuando se compila este código fuente, el diagrama de flujo para el código ensamblador resultante es bastante diferente al de la fuente porque las reglas seguidas por los compiladores C o C ++ les permiten modificar el código de la forma que deseen, siempre que el binario se comporta "como si fuera lo mismo".
En la mayoría de las circunstancias, ese principio es totalmente aceptable, pero hay anomalías. Las optimizaciones del compilador son básicamente transformaciones matemáticas que se aplican a una representación interna del código. Estas transformaciones "salen mal" si las suposiciones no se cumplen, como suele ser el caso cuando el código base incluye instancias de comportamiento indefinido, por ejemplo.
Solo el DO-178C, utilizado en la industria aeroespacial, se centra en el potencial de peligrosas inconsistencias entre la intención del desarrollador y el comportamiento ejecutable, e incluso entonces, no es difícil encontrar defensores de soluciones provisionales con un claro potencial para dejar esas inconsistencias sin ser detectadas. Independientemente de cómo se justifiquen estos enfoques, el hecho es que las diferencias entre el código fuente y el código objeto pueden tener consecuencias devastadoras en cualquier aplicación crítica.
Intención del desarrollador frente a comportamiento ejecutable
A pesar de las claras diferencias entre el flujo de código fuente y objeto, no son la principal preocupación. Los compiladores son generalmente aplicaciones altamente confiables y, si bien puede haber errores como en cualquier otro software, la implementación de un compilador generalmente cumplirá con sus requisitos de diseño. El problema es que esos requisitos de diseño no siempre reflejan las necesidades de un sistema funcionalmente seguro.
En resumen, se puede suponer que un compilador es funcionalmente fiel a los objetivos de sus creadores. Pero eso puede no ser del todo lo que se desea o se espera, como se ilustra en la Figura 2 a continuación con un ejemplo resultante de la compilación con el compilador CLANG.

La Figura 2 muestra una compilación con el compilador CLANG (Fuente:LDRA)
Está claro que la llamada defensiva a la función "error" no se ha expresado en el código ensamblador.
El objeto 'estado' solo se modifica cuando se inicializa y dentro de los casos 'S0' y 'S1', por lo que el compilador puede razonar que los únicos valores dados a 'estado' son 'S0' y 'S1'. concluye que el 'predeterminado' no es necesario porque 'estado' nunca tendrá ningún otro valor, asumiendo que no hay corrupción, y de hecho, el compilador hace exactamente esa suposición.
El compilador también ha decidido que debido a que los valores de los objetos reales (13 y 23) no se usan en un contexto numérico, simplemente usará los valores de 0 y 1 para alternar entre estados y luego usará un "o" exclusivo para actualizar el valor del estado. El binario se adhiere a la obligación "como si" y el código es rápido y compacto. Dentro de sus términos de referencia, el compilador ha hecho un buen trabajo.
Este comportamiento tiene implicaciones para las herramientas de "calibración" que utilizan el archivo de mapa de memoria del vinculador para acceder a los objetos indirectamente y para el acceso directo a la memoria a través de un depurador. Nuevamente, estas consideraciones no son parte del mandato del compilador y, por lo tanto, no se tienen en cuenta durante la optimización y / o la generación de código.
Ahora suponga que el código permanece sin cambios, pero su contexto en el código presentado al compilador cambia levemente, como en la Figura 3.
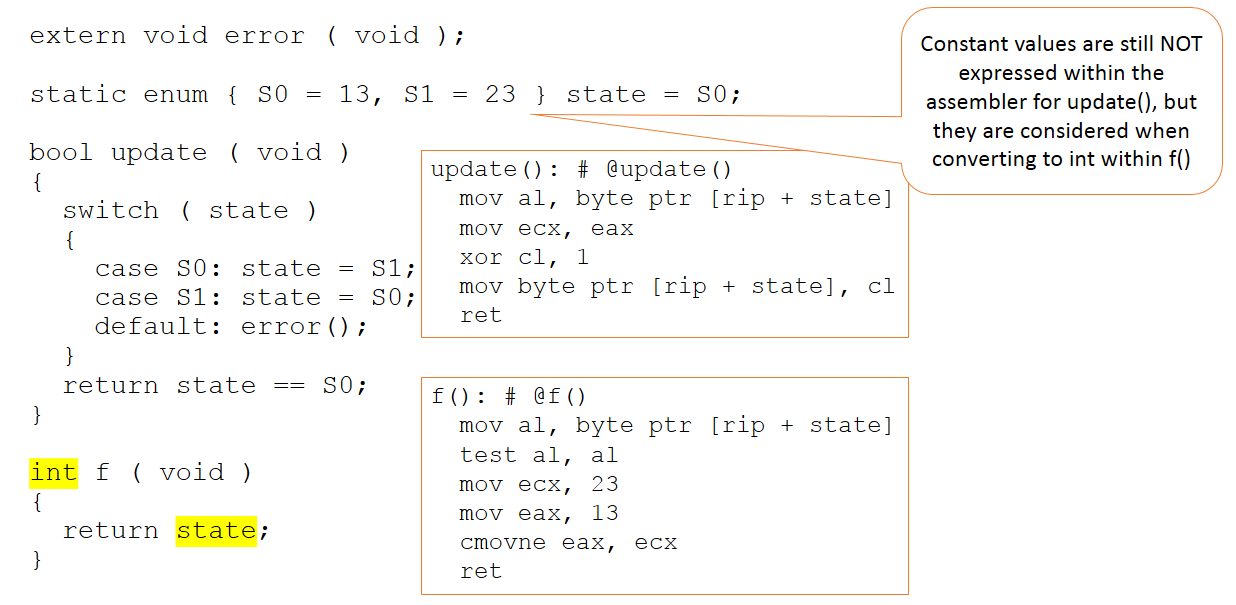
Figura 3:El código permanece sin cambios, pero su contexto en el código presentado al compilador cambia ligeramente. (Fuente:LDRA)
Ahora hay una función adicional, que devuelve el valor de la variable de estado como un número entero. Esta vez, los valores absolutos 13 y 23 importan en el código enviado al compilador. Aun así, esos valores no se manipulan dentro de la función de actualización (que permanece sin cambios) y solo son aparentes dentro de nuestra nueva función "f".
En resumen, el compilador continúa (correctamente) haciendo juicios de valor sobre dónde deben usarse los valores de 13 y 23, y de ninguna manera se aplican en todas las situaciones en las que podrían estar.
Si se cambia la nueva función para devolver un puntero a nuestra variable de estado, el código ensamblador cambia sustancialmente. Debido a que ahora existe la posibilidad de accesos de alias a través de un puntero, el compilador ya no puede deducir lo que está sucediendo con el objeto de estado. Como se muestra en la Figura 4 a continuación, no se puede concluir que los valores de 13 y 23 no sean importantes y, por lo tanto, ahora se expresan explícitamente dentro del ensamblador.
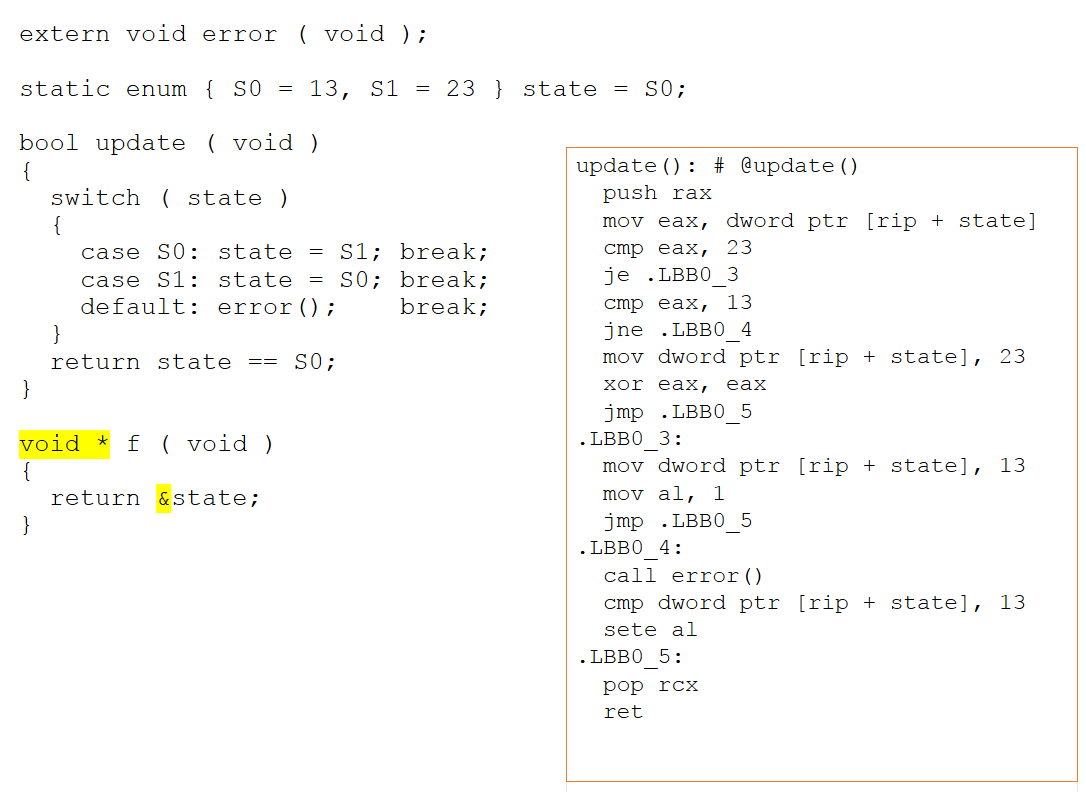
Figura 4:Si se cambia la nueva función para devolver un puntero a nuestra variable de estado, el código ensamblador cambia sustancialmente. No puede concluir que los valores de 13 y 23 no sean importantes y, por lo tanto, ahora se expresan explícitamente dentro del ensamblador (Fuente:LDRA).
Implicaciones para la prueba unitaria del código fuente
Ahora considere el ejemplo en el contexto de un arnés de prueba unitario imaginario. Como consecuencia de la necesidad de un arnés para acceder al código bajo prueba, el valor de la variable de estado se manipula y, como consecuencia, el valor predeterminado no se “optimiza”. Tal enfoque es totalmente justificable en una herramienta de prueba que no tiene un contexto relacionado con el resto del código fuente y que se requiere para hacer que todo sea accesible, pero como efecto secundario puede disfrazar la omisión legítima del código defensivo por parte del compilador.
El compilador reconoce que se escribe un valor arbitrario en la variable de estado mediante un puntero y, nuevamente, no puede concluir que los valores de 13 y 23 no son importantes. En consecuencia, ahora se expresan explícitamente dentro del ensamblador. En esta ocasión, no se puede concluir que S0 y S1 representen los únicos valores posibles para la variable de estado, lo que significa que la ruta predeterminada puede ser factible. Como se muestra en la Figura 5, la manipulación de la variable de estado logra su objetivo y la llamada a la función de error ahora es evidente en el ensamblador.

Figura 5:La manipulación de la variable de estado logra su objetivo y la llamada a la función de error ahora es evidente en el ensamblador. (Fuente:LDRA)
Sin embargo, esta manipulación no estará presente en el código que se enviará dentro de un producto, por lo que la llamada a error () no está realmente en el sistema completo.
La importancia de la verificación del código objeto
Para ilustrar cómo la verificación del código objeto puede ayudar a resolver este enigma, considere nuevamente el primer fragmento de código de ejemplo, que se muestra en la Figura 6:

Figura 6:Esto ilustra cómo la verificación del código objeto puede ayudar a resolver cómo la llamada al error no está en el sistema completo. (Fuente:LDRA)
Se puede demostrar que este código C logra una cobertura del código fuente del 100% mediante una sola llamada, así:
f_ while4 (0,3);
El código puede reformatearse a una sola operación por línea y representarse en un diagrama de flujo como una colección de nodos de "bloque básico", cada uno de los cuales es una secuencia de código de línea recta. La relación entre los bloques básicos se representa en la Figura 7 utilizando bordes dirigidos entre los nodos.
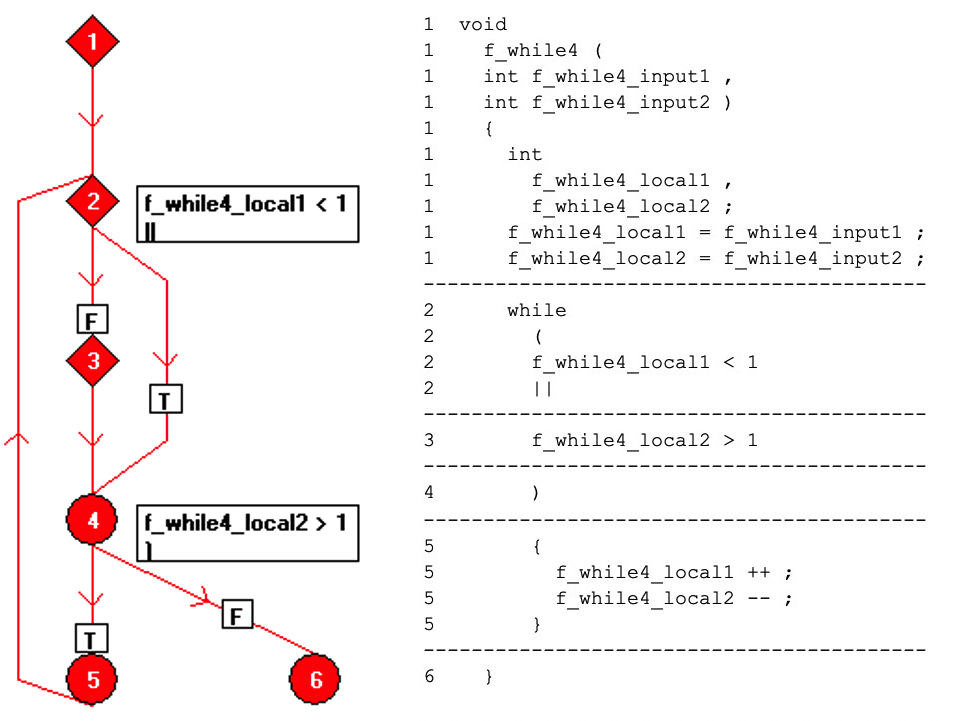
Figuras 7:Muestra la relación entre los bloques básicos utilizando aristas dirigidas entre los nodos. (Fuente:LDRA)
Cuando se compila el código, el resultado es el que se muestra a continuación (Figura 8). Los elementos azules del diagrama de flujo representan código que no ha sido ejercitado por la llamada f_ while4 (0,3).
Al aprovechar la relación uno a uno entre el código objeto y el código ensamblador, este mecanismo expone qué partes del código objeto no se ejercitan, lo que incita al probador a diseñar pruebas adicionales y lograr una cobertura completa del código ensamblador y, por lo tanto, lograr la verificación del código objeto.
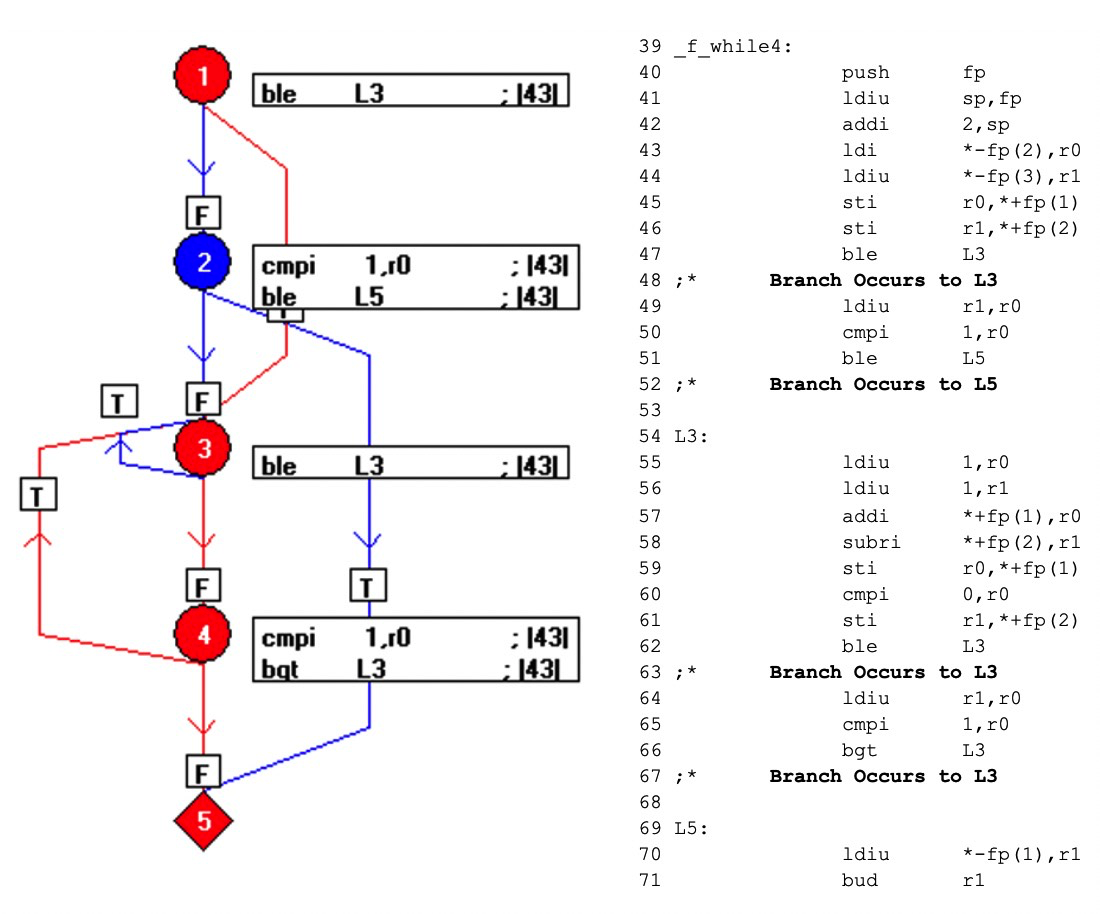
Figuras 8:Muestra el resultado cuando se compila el código. Los elementos azules del diagrama de flujo representan código que no ha sido ejercitado por la llamada f_ while4 (0,3). (Fuente:LDRA)
Claramente, la verificación del código objeto no tiene poder para evitar que el compilador siga sus reglas de diseño y eluda inadvertidamente las mejores intenciones de los desarrolladores. Pero puede, y lo hace, llamar la atención de los incautos sobre estos desajustes.
Ahora considere ese principio en el contexto del ejemplo anterior de "llamada al error". El código fuente en el sistema completo sería, por supuesto, idéntico al probado a nivel de prueba unitaria y, por lo tanto, una comparación de eso no revelaría nada. Pero la aplicación de la verificación del código objeto al sistema completo sería invaluable para garantizar que el comportamiento esencial se exprese como lo pretendían los desarrolladores.
Mejores prácticas en cualquier mundo
Si el compilador maneja el código de manera diferente en el arnés de prueba en comparación con la prueba unitaria, ¿vale la pena la cobertura de la prueba unitaria del código fuente? La respuesta es un "sí" calificado. Muchos sistemas han sido certificados en base a la evidencia de tales artefactos y se ha demostrado que son seguros y confiables en servicio. Pero para los sistemas más críticos en todos los sectores, si el proceso de desarrollo debe resistir el escrutinio más detallado y cumplir con las mejores prácticas, entonces la cobertura de prueba unitaria a nivel de fuente debe complementarse con OCV. Es razonable suponer que cumple con sus criterios de diseño, pero esos criterios no incluyen consideraciones de seguridad funcional. La verificación del código de objeto representa actualmente el enfoque más seguro para el mundo de la seguridad funcional, donde los comportamientos del compilador se ajustan a los estándares, pero, no obstante, pueden tener un impacto negativo significativo.
Incrustado
- La importancia de la seguridad eléctrica
- El mundo de los tintes textiles
- Aplicación de tintes ácidos en el mundo de las telas
- Un vistazo al mundo de los tintes
- Los múltiples usos de las cestas de seguridad
- El mundo de la simulación en rápida evolución
- Las capitales manufactureras del mundo
- 5 de los consejos de seguridad de grúas más importantes
- La importancia de los materiales de fricción en los sistemas de seguridad
- La seguridad en las fábricas:una fuente de mejora continua
- Las diferencias entre el código G y el código M