


Multiproceso en Python con ejemplo:Aprenda GIL en Python
El lenguaje de programación python le permite usar multiprocesamiento o subprocesos múltiples. En este tutorial, aprenderá a escribir aplicaciones de subprocesos múltiples en Python.
¿Qué es un hilo?
Un hilo es una unidad de ejecución en programación concurrente. Multithreading es una técnica que permite que una CPU ejecute muchas tareas de un proceso al mismo tiempo. Estos subprocesos pueden ejecutarse individualmente mientras comparten sus recursos de proceso.
¿Qué es un proceso?
Un proceso es básicamente el programa en ejecución. Cuando inicia una aplicación en su computadora (como un navegador o un editor de texto), el sistema operativo crea un proceso.
¿Qué es multihilo en Python?
Multiproceso en Python La programación es una técnica bien conocida en la que múltiples subprocesos en un proceso comparten su espacio de datos con el subproceso principal, lo que hace que el intercambio de información y la comunicación dentro de los subprocesos sea fácil y eficiente. Los hilos son más ligeros que los procesos. Los subprocesos múltiples pueden ejecutarse individualmente mientras comparten sus recursos de proceso. El propósito de los subprocesos múltiples es ejecutar múltiples tareas y celdas de funciones al mismo tiempo.
En este tutorial, aprenderá,
- ¿Qué es un hilo?
- ¿Qué es un proceso?
- ¿Qué es multihilo?
- ¿Qué es el multiprocesamiento?
- Múltiples subprocesos de Python frente a multiprocesamiento
- ¿Por qué usar subprocesos múltiples?
- Múltiples subprocesos de Python
- Los módulos Thread y Threading
- El módulo de subprocesos
- El módulo de subprocesamiento
- Puntos muertos y condiciones de carrera
- Sincronización de hilos
- ¿Qué es GIL?
- ¿Por qué se necesitaba GIL?
¿Qué es el multiprocesamiento?
El multiprocesamiento le permite ejecutar múltiples procesos no relacionados simultáneamente. Estos procesos no comparten sus recursos y se comunican a través de IPC.
Multiproceso de Python frente a multiprocesamiento
Para comprender los procesos y los subprocesos, considere este escenario:un archivo .exe en su computadora es un programa. Cuando lo abre, el sistema operativo lo carga en la memoria y la CPU lo ejecuta. La instancia del programa que ahora se está ejecutando se denomina proceso.
Todo proceso tendrá 2 componentes fundamentales:
- El Código
- Los datos
Ahora, un proceso puede contener una o más subpartes denominadas subprocesos. Esto depende de la arquitectura del sistema operativo. Puede pensar en un subproceso como una sección del proceso que el sistema operativo puede ejecutar por separado.
En otras palabras, es un flujo de instrucciones que el sistema operativo puede ejecutar de forma independiente. Los subprocesos dentro de un solo proceso comparten los datos de ese proceso y están diseñados para trabajar juntos para facilitar el paralelismo.
¿Por qué utilizar subprocesos múltiples?
Multithreading le permite dividir una aplicación en múltiples subtareas y ejecutar estas tareas simultáneamente. Si usa subprocesos múltiples correctamente, la velocidad, el rendimiento y la representación de su aplicación pueden mejorarse.
Multiproceso de Python
Python admite construcciones tanto para multiprocesamiento como para subprocesos múltiples. En este tutorial, se centrará principalmente en implementar multiproceso aplicaciones con python. Hay dos módulos principales que se pueden usar para manejar subprocesos en Python:
- El hilo módulo, y
- El enhebrado módulo
Sin embargo, en python, también hay algo llamado bloqueo de intérprete global (GIL). No permite aumentar mucho el rendimiento e incluso puede reducir el rendimiento de algunas aplicaciones multiproceso. Aprenderá todo al respecto en las próximas secciones de este tutorial.
Los módulos Thread y Threading
Los dos módulos sobre los que aprenderá en este tutorial son el módulo de subprocesos y el módulo de hilos .
Sin embargo, el módulo de subprocesos ha quedado obsoleto durante mucho tiempo. A partir de Python 3, se ha designado como obsoleto y solo se puede acceder a él como __thread. para compatibilidad con versiones anteriores.
Debe utilizar el subprocesamiento de nivel superior módulo para las aplicaciones que pretende implementar. El módulo de subprocesos solo se ha tratado aquí con fines educativos.
El módulo de hilos
La sintaxis para crear un hilo nuevo usando este módulo es la siguiente:
thread.start_new_thread(function_name, arguments)
Muy bien, ahora has cubierto la teoría básica para comenzar a codificar. Entonces, abra su IDLE o un bloc de notas y escriba lo siguiente:
import time
import _thread
def thread_test(name, wait):
i = 0
while i <= 3:
time.sleep(wait)
print("Running %s\n" %name)
i = i + 1
print("%s has finished execution" %name)
if __name__ == "__main__":
_thread.start_new_thread(thread_test, ("First Thread", 1))
_thread.start_new_thread(thread_test, ("Second Thread", 2))
_thread.start_new_thread(thread_test, ("Third Thread", 3))
Guarde el archivo y presione F5 para ejecutar el programa. Si todo se hizo correctamente, este es el resultado que debería ver:
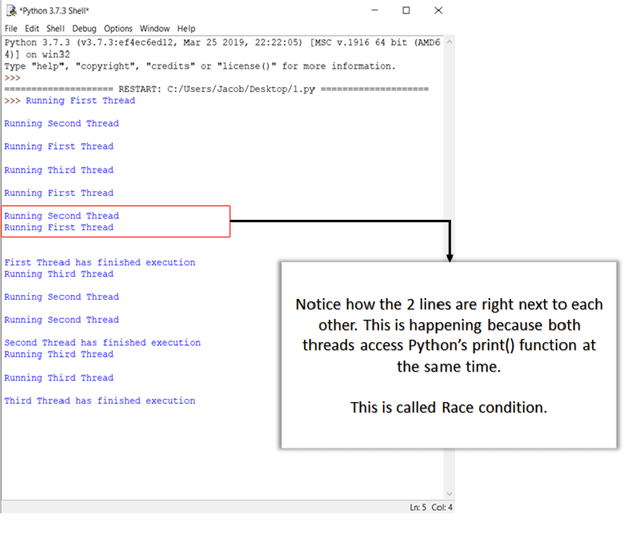
Aprenderás más sobre las condiciones de carrera y cómo manejarlas en las próximas secciones
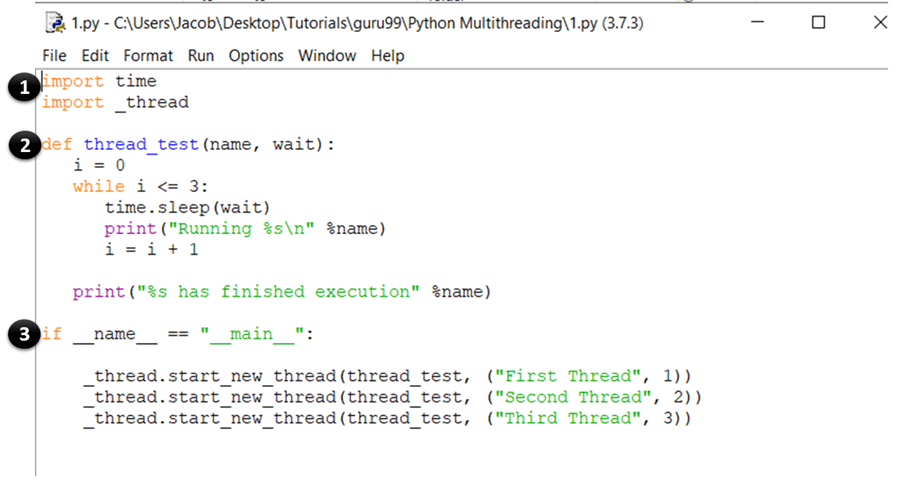
EXPLICACIÓN DEL CÓDIGO
- Estas declaraciones importan el tiempo y el módulo de subprocesos que se utilizan para manejar la ejecución y el retraso de los subprocesos de Python.
- Aquí, ha definido una función llamada thread_test, que será llamado por start_new_thread método. La función ejecuta un ciclo while durante cuatro iteraciones e imprime el nombre del subproceso que lo llamó. Una vez que se completa la iteración, imprime un mensaje que dice que el hilo ha terminado de ejecutarse.
- Esta es la sección principal de su programa. Aquí, simplemente llame al start_new_thread método con thread_test función como un argumento. Esto creará un nuevo hilo para la función que pasa como argumento y comenzará a ejecutarlo. Tenga en cuenta que puede reemplazar esto (thread_ test) con cualquier otra función que desee ejecutar como hilo.
El módulo de subprocesos
Este módulo es la implementación de alto nivel de subprocesos en python y el estándar de facto para administrar aplicaciones multiproceso. Proporciona una amplia gama de características en comparación con el módulo de subprocesos.
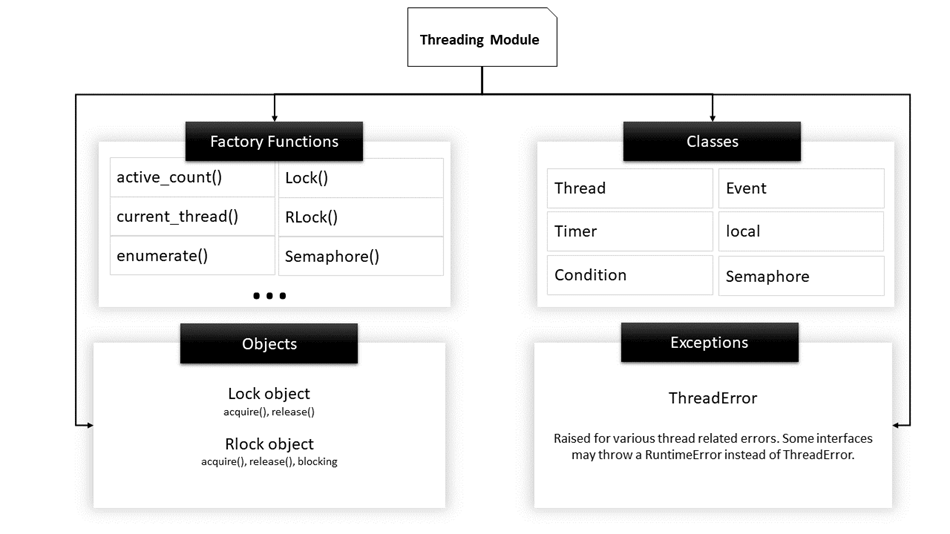
Aquí hay una lista de algunas funciones útiles definidas en este módulo:
| Nombre de la función | Descripción |
|---|---|
| recuento activo() | Devuelve el recuento de Subproceso objetos que todavía están vivos |
| subproceso actual() | Devuelve el objeto actual de la clase Thread. |
| enumerar() | Enumera todos los objetos Thread activos. |
| esDaemon() | Devuelve verdadero si el subproceso es un demonio. |
| está vivo() | Devuelve verdadero si el hilo aún está activo. |
| Métodos de clase de subprocesos | |
| inicio() | Inicia la actividad de un hilo. Debe llamarse solo una vez para cada subproceso porque arrojará un error de tiempo de ejecución si se llama varias veces. |
| ejecutar() | Este método indica la actividad de un subproceso y puede ser anulado por una clase que amplíe la clase Subproceso. |
| unirse() | Bloquea la ejecución de otro código hasta que finaliza el subproceso en el que se llamó al método join(). |
Trasfondo:La clase Thread
Antes de comenzar a codificar programas de subprocesos múltiples utilizando el módulo de subprocesos, es crucial comprender la clase Subproceso. La clase subproceso es la clase principal que define la plantilla y las operaciones de un subproceso en python.
La forma más común de crear una aplicación Python multiproceso es declarar una clase que amplíe la clase Thread y anule su método run().
La clase Thread, en resumen, significa una secuencia de código que se ejecuta en un thread separado. de control.
Por lo tanto, al escribir una aplicación multiproceso, deberá hacer lo siguiente:
- defina una clase que amplíe la clase Thread
- Anular __init__ constructor
- Anular ejecutar() método
Una vez que se ha creado un objeto de hilo, start() se puede usar para comenzar la ejecución de esta actividad y join() El método se puede usar para bloquear el resto del código hasta que finalice la actividad actual.
Ahora, intentemos usar el módulo de subprocesos para implementar su ejemplo anterior. Nuevamente, encienda su IDLE y escriba lo siguiente:
import time
import threading
class threadtester (threading.Thread):
def __init__(self, id, name, i):
threading.Thread.__init__(self)
self.id = id
self.name = name
self.i = i
def run(self):
thread_test(self.name, self.i, 5)
print ("%s has finished execution " %self.name)
def thread_test(name, wait, i):
while i:
time.sleep(wait)
print ("Running %s \n" %name)
i = i - 1
if __name__=="__main__":
thread1 = threadtester(1, "First Thread", 1)
thread2 = threadtester(2, "Second Thread", 2)
thread3 = threadtester(3, "Third Thread", 3)
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
Este será el resultado cuando ejecute el código anterior:
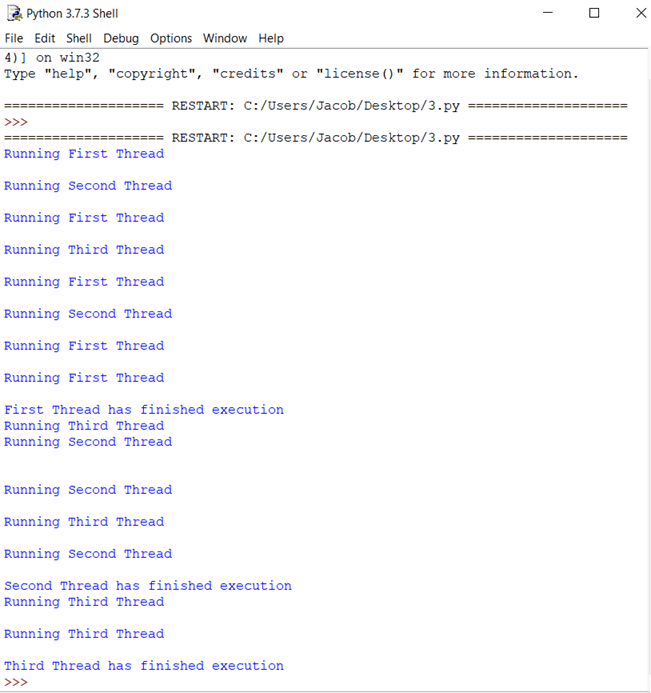
EXPLICACIÓN DEL CÓDIGO
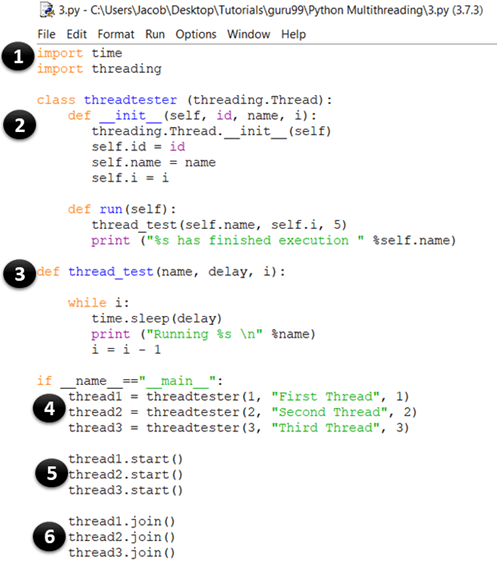
- Esta parte es igual a nuestro ejemplo anterior. Aquí, importa el módulo de tiempo y subprocesos que se utilizan para manejar la ejecución y los retrasos de los subprocesos de Python.
- En este momento, está creando una clase llamada probador de subprocesos, que hereda o amplía el Subproceso clase del módulo de subprocesamiento. Esta es una de las formas más comunes de crear hilos en python. Sin embargo, solo debe anular el constructor y el ejecutar() método en su aplicación. Como puede ver en el ejemplo de código anterior, el __init__ El método (constructor) ha sido anulado. Del mismo modo, también anuló run() método. Contiene el código que desea ejecutar dentro de un hilo. En este ejemplo, ha llamado a la función thread_test().
- Este es el método thread_test() que toma el valor de i como argumento, lo disminuye en 1 en cada iteración y recorre el resto del código hasta que i se convierte en 0. En cada iteración, imprime el nombre del subproceso que se está ejecutando actualmente y duerme durante los segundos de espera (que también se toma como argumento ).
- thread1 =threadtester(1, “First Thread”, 1) Aquí, estamos creando un hilo y pasando los tres parámetros que declaramos en __init__. El primer parámetro es la identificación del subproceso, el segundo parámetro es el nombre del subproceso y el tercer parámetro es el contador, que determina cuántas veces debe ejecutarse el ciclo while.
- thread2.start() El método start se usa para iniciar la ejecución de un hilo. Internamente, la función start() llama al método run() de su clase.
- thread3.join() El método join() bloquea la ejecución de otro código y espera hasta que finaliza el hilo en el que se llamó.
Como ya sabes, los hilos que están en un mismo proceso tienen acceso a la memoria y datos de ese proceso. Como resultado, si más de un subproceso intenta cambiar o acceder a los datos simultáneamente, pueden aparecer errores.
En la siguiente sección, verá los diferentes tipos de complicaciones que pueden aparecer cuando los subprocesos acceden a los datos y a la sección crítica sin verificar las transacciones de acceso existentes.
Deadlocks y condiciones de carrera
Antes de aprender sobre interbloqueos y condiciones de carrera, será útil comprender algunas definiciones básicas relacionadas con la programación concurrente:
- Sección críticaEs un fragmento de código que accede o modifica variables compartidas y debe realizarse como una transacción atómica.
- Cambio de contextoEs el proceso que sigue una CPU para almacenar el estado de un subproceso antes de cambiar de una tarea a otra para que pueda reanudarse desde el mismo punto más adelante.
Interbloqueos
Los interbloqueos son el problema más temido al que se enfrentan los desarrolladores cuando escriben aplicaciones concurrentes o de subprocesos múltiples en python. La mejor manera de comprender los interbloqueos es mediante el uso del clásico problema de ejemplo de informática conocido como el Problema de los filósofos comedores.
El enunciado del problema para los filósofos comedores es el siguiente:
Cinco filósofos están sentados en una mesa redonda con cinco platos de espagueti (un tipo de pasta) y cinco tenedores, como se muestra en el diagrama.

En un momento dado, un filósofo debe estar comiendo o pensando.
Además, un filósofo debe tomar los dos tenedores adyacentes a él (es decir, los tenedores izquierdo y derecho) antes de poder comer los espaguetis. El problema del interbloqueo ocurre cuando los cinco filósofos toman sus bifurcaciones derechas simultáneamente.
Como cada uno de los filósofos tiene un tenedor, todos esperarán a que los demás bajen el tenedor. Como resultado, ninguno de ellos podrá comer espaguetis.
De manera similar, en un sistema concurrente, se produce un interbloqueo cuando diferentes subprocesos o procesos (filósofos) intentan adquirir los recursos del sistema compartido (bifurcaciones) al mismo tiempo. Como resultado, ninguno de los procesos tiene la oportunidad de ejecutarse mientras esperan otro recurso en poder de otro proceso.
Condiciones de carrera
Una condición de carrera es un estado no deseado de un programa que ocurre cuando un sistema realiza dos o más operaciones simultáneamente. Por ejemplo, considere este bucle for simple:
i=0; # a global variable
for x in range(100):
print(i)
i+=1;
Si crea n número de subprocesos que ejecutan este código a la vez, no puede determinar el valor de i (que es compartido por los subprocesos) cuando el programa finaliza la ejecución. Esto se debe a que en un entorno real de subprocesos múltiples, los subprocesos pueden superponerse, y el valor de i que fue recuperado y modificado por un subproceso puede cambiar cuando otro subproceso accede a él.
Estas son las dos clases principales de problemas que pueden ocurrir en una aplicación de python multiproceso o distribuida. En la siguiente sección, aprenderá cómo superar este problema sincronizando subprocesos.
Sincronización de hilos
Para hacer frente a condiciones de carrera, interbloqueos y otros problemas relacionados con subprocesos, el módulo de subprocesos proporciona el Bloqueo objeto. La idea es que cuando un subproceso quiere acceder a un recurso específico, adquiere un bloqueo para ese recurso. Una vez que un subproceso bloquea un recurso en particular, ningún otro subproceso puede acceder a él hasta que se libere el bloqueo. Como resultado, los cambios en el recurso serán atómicos y se evitarán las condiciones de carrera.
Un bloqueo es una primitiva de sincronización de bajo nivel implementada por __thread módulo. En un momento dado, un candado puede estar en uno de dos estados:bloqueado o desbloqueado. Admite dos métodos:
- adquirir() Cuando el estado de bloqueo está desbloqueado, llamar al método de adquisición () cambiará el estado a bloqueado y regresará. Sin embargo, si el estado está bloqueado, la llamada a adquirir() se bloquea hasta que algún otro subproceso llame al método release().
- liberar() El método release() se usa para establecer el estado en desbloqueado, es decir, para liberar un bloqueo. Puede ser llamado por cualquier subproceso, no necesariamente por el que adquirió el bloqueo.
Este es un ejemplo del uso de bloqueos en sus aplicaciones. Encienda su IDLE y escriba lo siguiente:
import threading
lock = threading.Lock()
def first_function():
for i in range(5):
lock.acquire()
print ('lock acquired')
print ('Executing the first funcion')
lock.release()
def second_function():
for i in range(5):
lock.acquire()
print ('lock acquired')
print ('Executing the second funcion')
lock.release()
if __name__=="__main__":
thread_one = threading.Thread(target=first_function)
thread_two = threading.Thread(target=second_function)
thread_one.start()
thread_two.start()
thread_one.join()
thread_two.join()
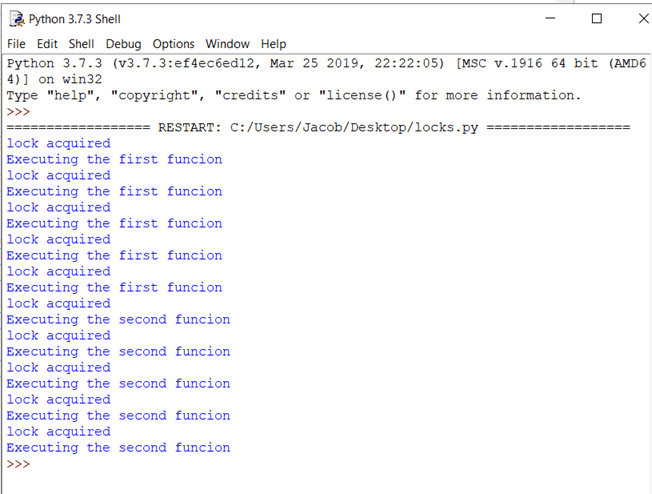
Ahora, pulsa F5. Debería ver una salida como esta:
EXPLICACIÓN DEL CÓDIGO
- Aquí, simplemente está creando un nuevo bloqueo llamando a threading.Lock() función de fábrica. Internamente, Lock() devuelve una instancia de la clase Lock concreta más eficaz que mantiene la plataforma.
- En la primera declaración, adquiere el bloqueo llamando al método de adquisición(). Cuando se ha otorgado el bloqueo, imprime "bloqueo adquirido" a la consola Una vez que todo el código que desea que ejecute el subproceso haya terminado de ejecutarse, libere el bloqueo llamando al método release().
La teoría está bien, pero ¿cómo sabes que la cerradura realmente funcionó? Si observa la salida, verá que cada una de las declaraciones de impresión está imprimiendo exactamente una línea a la vez. Recuerde que, en un ejemplo anterior, los resultados de la impresión eran aleatorios porque varios subprocesos accedían al método print() al mismo tiempo. Aquí, la función de impresión se llama solo después de que se adquiere el bloqueo. Por lo tanto, las salidas se muestran una a la vez y línea por línea.
Además de los bloqueos, python también admite otros mecanismos para manejar la sincronización de subprocesos, como se indica a continuación:
- Bloques
- Semáforos
- Condiciones
- Eventos, y
- Barreras
Bloqueo de intérprete global (y cómo solucionarlo)
Antes de entrar en los detalles de GIL de Python, definamos algunos términos que serán útiles para comprender la siguiente sección:
- Código vinculado a la CPU:se refiere a cualquier pieza de código que será ejecutada directamente por la CPU.
- Código vinculado a E/S:puede ser cualquier código que acceda al sistema de archivos a través del sistema operativo
- CPython:es la implementación de referencia de Python y se puede describir como el intérprete escrito en C y Python (lenguaje de programación).
¿Qué es GIL en Python?
Bloqueo de intérprete global (GIL) en python es un bloqueo de proceso o un mutex que se usa al tratar con los procesos. Se asegura de que un subproceso pueda acceder a un recurso en particular a la vez y también evita el uso de objetos y códigos de bytes a la vez. Esto beneficia a los programas de subproceso único en un aumento del rendimiento. GIL en python es muy simple y fácil de implementar.
Se puede usar un bloqueo para asegurarse de que solo un subproceso tenga acceso a un recurso en particular en un momento dado.
Una de las características de Python es que utiliza un bloqueo global en cada proceso de interpretación, lo que significa que cada proceso trata al intérprete de Python como un recurso.
Por ejemplo, suponga que ha escrito un programa de Python que utiliza dos subprocesos para realizar operaciones de CPU y de "E/S". Cuando ejecuta este programa, esto es lo que sucede:
- El intérprete de python crea un nuevo proceso y genera los subprocesos
- Cuando el subproceso 1 comience a ejecutarse, primero adquirirá el GIL y lo bloqueará.
- Si el subproceso 2 quiere ejecutarse ahora, tendrá que esperar a que se libere el GIL incluso si hay otro procesador libre.
- Ahora, supongamos que el subproceso 1 está esperando una operación de E/S. En ese momento, liberará el GIL y thread-2 lo adquirirá.
- Después de completar las operaciones de E/S, si el subproceso 1 quiere ejecutarse ahora, nuevamente tendrá que esperar a que el subproceso 2 libere el GIL.
Debido a esto, solo un subproceso puede acceder al intérprete en cualquier momento, lo que significa que solo habrá un subproceso ejecutando código python en un momento determinado.
Esto está bien en un procesador de un solo núcleo porque estaría usando la división de tiempo (vea la primera sección de este tutorial) para manejar los subprocesos. Sin embargo, en el caso de los procesadores multinúcleo, una función vinculada a la CPU que se ejecute en varios subprocesos tendrá un impacto considerable en la eficiencia del programa, ya que en realidad no utilizará todos los núcleos disponibles al mismo tiempo.
¿Por qué se necesitaba GIL?
El recolector de elementos no utilizados de CPython utiliza una técnica de gestión de memoria eficiente conocida como recuento de referencias. Así es como funciona:cada objeto en python tiene un recuento de referencias, que aumenta cuando se asigna a un nuevo nombre de variable o se agrega a un contenedor (como tuplas, listas, etc.). Del mismo modo, el recuento de referencias se reduce cuando la referencia queda fuera del alcance o cuando se llama a la instrucción del. Cuando el recuento de referencias de un objeto llega a 0, se recolecta basura y se libera la memoria asignada.
Pero el problema es que la variable de conteo de referencia es propensa a condiciones de carrera como cualquier otra variable global. Para resolver este problema, los desarrolladores de python decidieron utilizar el bloqueo de intérprete global. La otra opción era agregar un bloqueo a cada objeto, lo que habría resultado en interbloqueos y un aumento de la sobrecarga de las llamadas de adquisición () y liberación ().
Por lo tanto, GIL es una restricción significativa para los programas de Python multihilo que ejecutan operaciones pesadas vinculadas a la CPU (haciéndolos efectivamente de un solo hilo). Si desea utilizar varios núcleos de CPU en su aplicación, utilice el multiprocesamiento módulo en su lugar.
Resumen
- Python admite 2 módulos para subprocesos múltiples:
- __hilo módulo:proporciona una implementación de bajo nivel para subprocesos y está obsoleto.
- módulo de hilos :proporciona una implementación de alto nivel para subprocesos múltiples y es el estándar actual.
- Para crear un hilo usando el módulo de hilos, debe hacer lo siguiente:
- Cree una clase que amplíe el hilo clase.
- Anular su constructor (__init__).
- Anular su run() método.
- Cree un objeto de esta clase.
- Se puede ejecutar un subproceso llamando a start() método.
- El join() El método se puede usar para bloquear otros subprocesos hasta que este subproceso (aquel en el que se llamó a join) finalice la ejecución.
- Se produce una condición de carrera cuando varios subprocesos acceden o modifican un recurso compartido al mismo tiempo.
- Se puede evitar sincronizando hilos.
- Python admite 6 formas de sincronizar subprocesos:
- Cerraduras
- Bloques
- Semáforos
- Condiciones
- Eventos, y
- Barreras
- Los bloqueos permiten que solo un subproceso en particular que haya adquirido el bloqueo ingrese a la sección crítica.
- Un candado tiene 2 métodos principales:
- adquirir() :Establece el estado de bloqueo en bloqueado. Si se invoca en un objeto bloqueado, se bloquea hasta que el recurso esté libre.
- liberar() :Establece el estado de bloqueo en desbloqueado y regresa Si se invoca en un objeto desbloqueado, devuelve falso.
- El bloqueo de intérprete global es un mecanismo a través del cual solo se puede ejecutar 1 proceso de intérprete de CPython a la vez.
- Se usó para facilitar la funcionalidad de conteo de referencias del recolector de basura de CPythons.
- Para crear aplicaciones de Python con operaciones intensivas vinculadas a la CPU, debe usar el módulo de multiprocesamiento.
python
- Función free () en la biblioteca C:¿Cómo usar? Aprende con el Ejemplo
- Python String strip() Función con EJEMPLO
- Python String count () con EJEMPLOS
- Función Python round() con EJEMPLOS
- Función Python map() con EJEMPLOS
- Python Timeit() con ejemplos
- Contador de Python en colecciones con ejemplo
- Python List count () con EJEMPLOS
- Índice de lista de Python () con ejemplo
- C# - Multiproceso
- Python - Programación multiproceso