


Introducción a la ciencia de datos | Componentes clave | Tipos y oportunidades
¿Qué es la ciencia de datos?
La ciencia de datos es un campo interdisciplinario que implica el uso de métodos, procesos y sistemas científicos para recopilar, preparar y analizar datos en forma estructurada y no estructurada. La ciencia de datos hace uso de varios campos, incluidas las matemáticas, las estadísticas, las bases de datos, las ciencias de la información y las ciencias de la computación. Los datos pueden ser de muchos tipos y de varios tamaños.
Necesidad de Data Science como un campo separado:
La razón principal para actualizar la ciencia de datos al nivel de un campo separado es la tasa de crecimiento exponencial de datos que nos rodean. Las estimaciones muestran que se producirán alrededor de 1,7 megabytes de datos por segundo para 2020. La acumulación de datos digitales alcanzará los 44 billones de gigabytes. Con cantidades tan grandes de datos, darles sentido y almacenarlos se vuelve cada vez más difícil. Como resultado, necesitamos una forma de estudiar y dar sentido a estos datos. Por lo tanto, la ciencia de datos se reconoció como un campo separado. 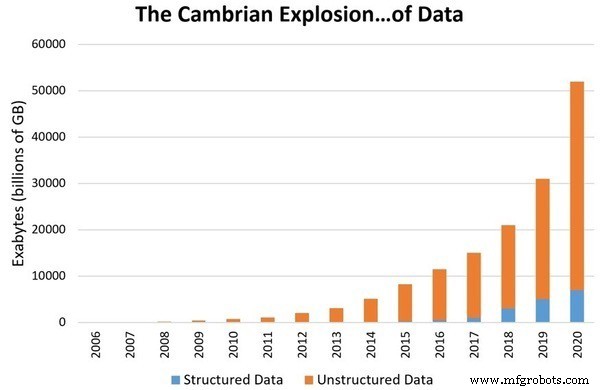
Ciencia de datos que nos rodea:
Las empresas utilizan la ciencia de datos para comprender y clasificar fácilmente sus procesos de datos dentro de la empresa. Por ejemplo, Google utiliza Data Science para personalizar los anuncios que se muestran a los usuarios en los sitios web que utilizan. Esto se hace a través de su programa AdSense, que permite a los editores publicar contenido para audiencias específicas.
Del mismo modo, Uber calcula cuánto se le cobrará a un cliente, cuándo otorgar descuentos ya quién. Airbnb ayuda a las personas a estimar el precio por el que deberían alquilar sus casas utilizando Data Science. En términos simples, podemos entender esto pensando en los clientes y usuarios como datos sin procesar y la ciencia de datos ayuda a interpretar esos datos. 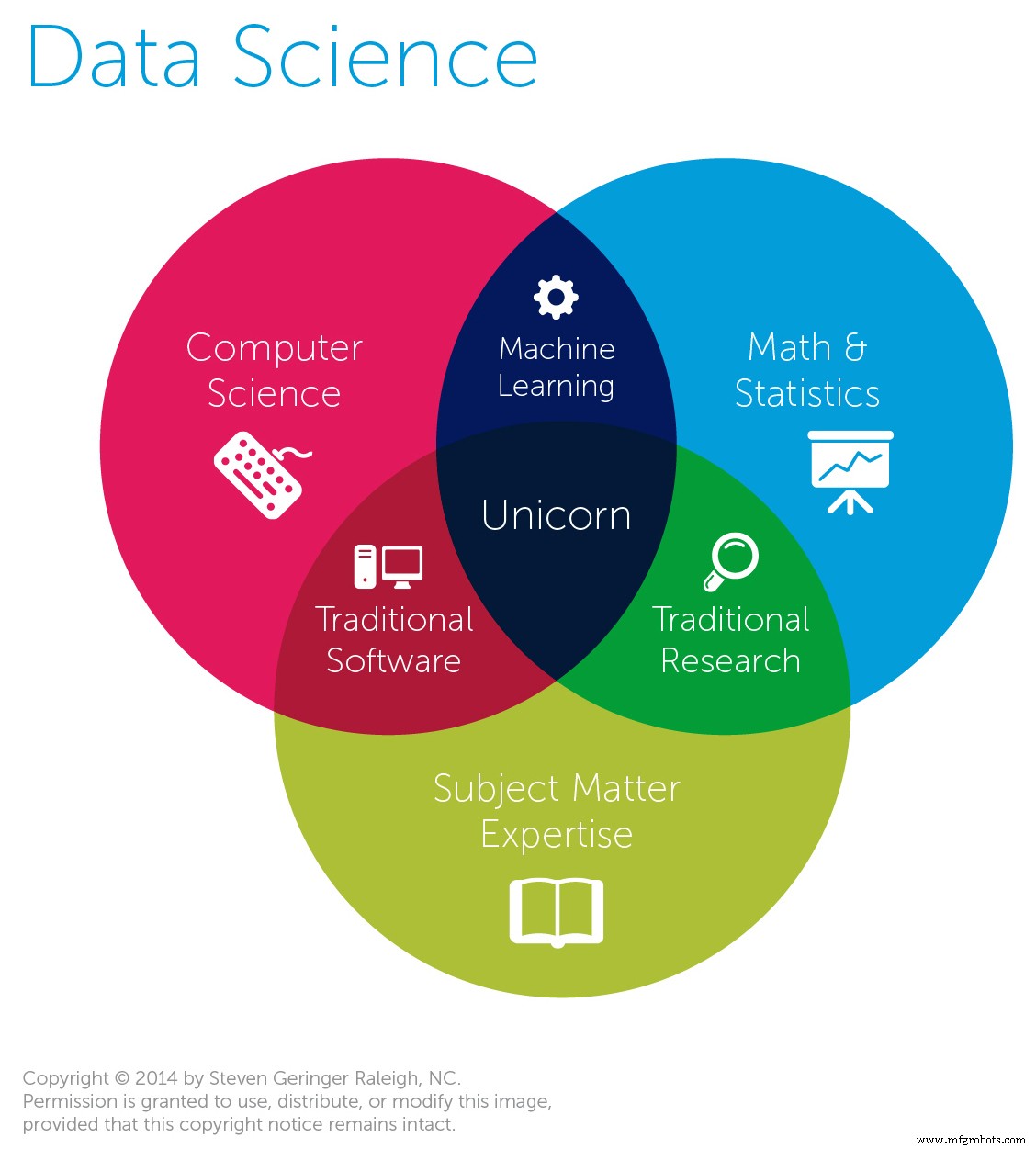
Ciencia de datos en organizaciones gubernamentales y no gubernamentales:
Los datos son un activo fundamental para las organizaciones gubernamentales. Hay una cantidad cada vez mayor de datos recopilados todos los días. Por lo tanto, requieren una forma de ordenar y almacenar todos estos datos, lo que se puede hacer a través de Data Science. Del mismo modo, las organizaciones no gubernamentales también utilizan la ciencia de datos. WWF utiliza las ciencias de datos para mostrar información en materia estadística sobre temas de vida silvestre y, por lo tanto, hacer que su causa sea efectiva.
Oportunidades en ciencia de datos:
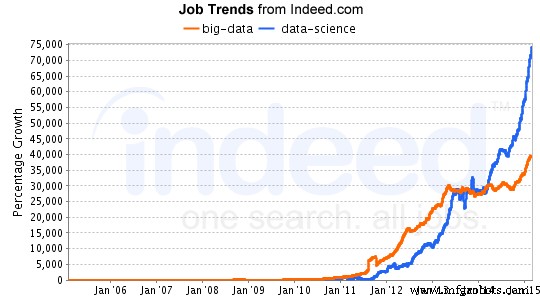
A medida que el campo de la ciencia de datos continúa creciendo, las oportunidades laborales en este campo también aumentan exponencialmente. El análisis realizado por LinkedIn sobre el crecimiento del empleo en ciencia de datos mostró un gran aumento en el campo de la ciencia de datos, especialmente en los últimos 30 años. Si está interesado en la ciencia de datos, puede obtener cursos gratuitos en línea. Consulte este tutorial sobre un salón común.
Componentes clave:
Ahora le daremos una idea de la ciencia de datos y sus diversos componentes.
1:Programación:
La ciencia de datos tiene que ver con los datos. Para organizar y analizar estos datos utilizamos la programación. Los lenguajes de programación son de muchos tipos. Los dos más extendidos son Python y R.
Pitón: Python es el lenguaje de programación más legible y flexible, de ahí su uso generalizado. Tiene muchos paquetes estadísticos y numéricos potentes, incluidos NumPy y pandas, Matplotlib, Tensorflow, iPython, etc. Python es mucho más rápido y fácil de aprender.
D: R es otro lenguaje de programación, pero la mayor parte se centra en técnicas estadísticas y gráficas. R es ampliamente utilizado entre estadísticos y mineros de datos para desarrollar software estadístico y análisis de datos. Es un lenguaje de código abierto.
2:Datos y sus tipos:
El siguiente componente clave son los datos en sí. Para comprender los datos, primero debemos comprender sus tipos.
Datos estructurados: Los datos estructurados se refieren a información con un alto grado de organización. Se puede representar fácilmente en forma tabular, se puede almacenar y procesar en bases de datos.
Datos no estructurados: Los datos no estructurados son información que no tiene un modelo de datos o no está organizada. Puede consistir en texto o datos como fechas, números, correos electrónicos, archivos PDF, imágenes, videos, etc.
Lenguaje natural: Datos en forma de lenguajes escritos utilizados para comunicarse, como inglés, español y urdu, etc. Se pueden considerar como un subtipo de datos no estructurados.
Imagen, Vídeo, Audio: Las imágenes, los videos y los audios también tienen una forma no estructurada. Se generan utilizando cámaras y micrófonos. El uso creciente se ve en los teléfonos inteligentes donde las imágenes y los videos se guardan y procesan todos los días.
Datos basados en gráficos: El gráfico es un conjunto de vértices y aristas. Es una estructura matemática utilizada para mostrar la relación entre dos entidades.
Generado por máquina: Los datos generados por máquinas son creados por sistemas informáticos, aplicaciones o máquinas sin la participación de humanos.
3:Estadística, Probabilidad y su relación con Data Science:
Estadísticas: La estadística es una rama de las matemáticas que se ocupa de la recopilación, interpretación, análisis, presentación y organización de datos. Utiliza programación para analizar datos.
Probabilidad: La probabilidad es la medida de la probabilidad de que ocurra un evento. Se cuantifica como un número entre 0 y 1, donde 0 indica imposibilidad y 1 indica certeza.
Relación con la ciencia de datos: Tanto la estadística como la probabilidad están relacionadas con la ciencia de datos. Son la base del procesamiento y análisis de datos. Utilizamos ambas ciencias en relación con la ciencia de datos para interpretar los datos correctamente.
4:Aprendizaje automático:
El aprendizaje automático es el campo de la informática derivado de la IA. Utiliza técnicas estadísticas para dar a las computadoras la capacidad de aprender sin ser programadas. La máquina mejora progresivamente su desempeño en una tarea específica al cambiar la estructura o el programa. Hay tres objetivos principales del aprendizaje automático. Uno, para aprender los cambios y la representación de estos cambios. En segundo lugar, para generalizar el rendimiento, de modo que sea efectivo no en una sola tarea sino en tareas similares por igual. Tercero. Para mejorar el rendimiento de una máquina y encontrar formas de evitar la degradación del rendimiento. En ciencia de datos, el aprendizaje automático se utiliza en algoritmos, regresión y métodos de clasificación. Se utiliza para predecir el resultado de los datos que se procesan de diferentes maneras.
5:Grandes Datos:
Big Data es el nombre que se le da a los datos en una cantidad tan grande que almacenar o procesar estos datos requiere una gran cantidad de computadoras. Se caracteriza por tres V:
Volumen: Datos en grandes volúmenes que van desde terabytes hasta zettabytes.
Variedad: Los datos pueden mostrar mucha variedad y diversidad. Puede ser una mezcla de dos o más tipos de datos, por ejemplo, tanto estructurados como no estructurados.
Velocidad: Los datos se generan a un ritmo en constante crecimiento. Esencialmente es la velocidad de los datos. 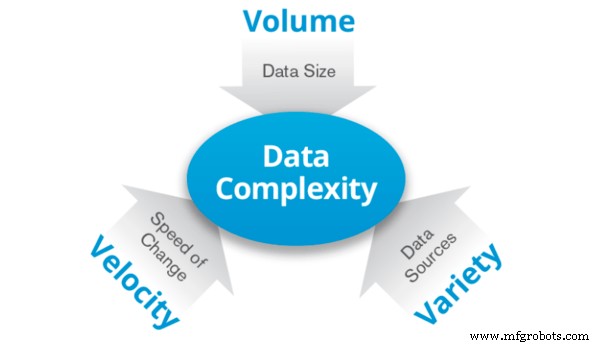
En ciencia de datos, los datos se agrupan en muchas formas y tipos. Los grandes datos pueden referirse a enormes volúmenes de datos que no pueden procesarse mediante el uso de aplicaciones tradicionales. Los científicos de datos utilizan diferentes herramientas para estudiar y procesar grandes datos, por ejemplo, Hadoop, Spark, R y Java, etc.
Tecnología Industrial
- Términos y conceptos de la memoria digital
- Variables de C# y tipos de datos (primitivos)
- Tipos de datos de Python
- Una introducción a la computación perimetral y ejemplos de casos de uso
- 5 tipos diferentes de centros de datos [con ejemplos]
- C - Tipos de datos
- MATLAB - Tipos de datos
- C# - Tipos de datos
- Tipos y clasificación de procesos de mecanizado | Ciencias de la fabricación
- Fresadoras - Introducción y tipos discutidos
- Proceso de fabricación Significado y tipos