


Hiperconvergencia y almacenamiento secundario:Parte 2

El almacenamiento secundario hiperconvergente parece destinado a desempeñar un papel fundamental en los entornos de IoT empresariales. Permite a las empresas administrar mejor la creciente cantidad de datos creados por los dispositivos.
Además, dice Bob Emmerson, facilita el intercambio fluido de datos entre los dominios de tecnología de la información (TI) y los dominios de tecnología operativa (OT), que es un requisito obligatorio para los sistemas de IoT.
El almacenamiento secundario regular emplea soluciones de silos, p. Ej. uno para copias de seguridad, otro para análisis, otro para archivos, etc., lo cual es ineficiente. Cohesión La plataforma definida por software consolida todos los datos secundarios en una única plataforma de datos que se ejecuta en nodos hiperconvergentes (servidores x86 estándar de la industria). Esto significa que todos los silos de almacenamiento secundarios están consolidados dentro del centro de datos.
Como se ilustra en la figura 1, plataformas similares definidas por software en el borde de la red se ejecutan en máquinas virtuales en servidores físicos compartidos. Tener la plataforma en ambas ubicaciones permite que los sitios remotos repliquen todos los datos locales en el centro de datos central para una copia de seguridad y una recuperación seguras.
Esto permite la creación de un tejido de datos que va desde las máquinas virtuales consolidadas en el borde hasta el centro de datos de almacenamiento secundario y la nube. Esto significa que la plataforma de datos permite la creación de un tejido de datos que va desde los datos que se generan y consolidan en el borde, hasta el centro de datos de almacenamiento secundario y la nube.
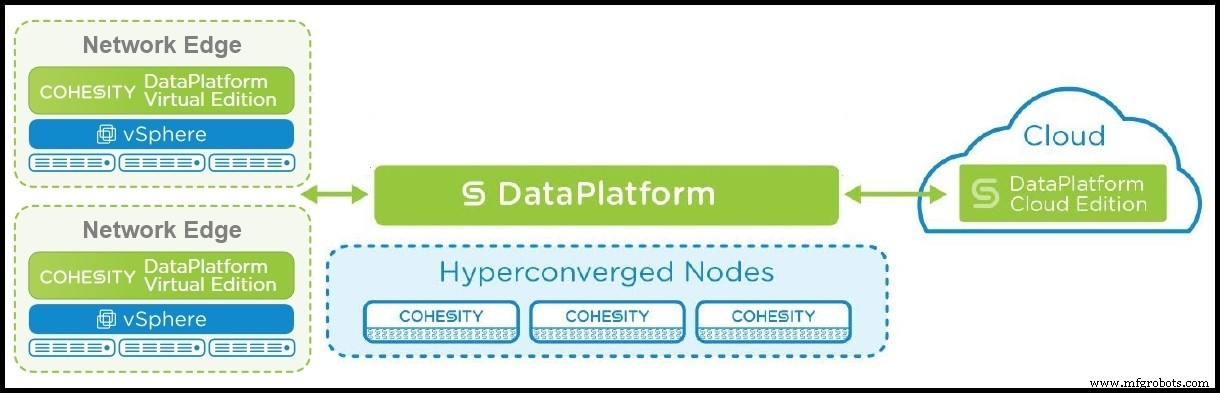
La acción de IoT tiene lugar en el borde de la red. El borde puede incluir sucursales remotas como puntos de venta minoristas y puntos de datos distribuidos para parques eólicos o flotas de camiones. Cuando las plataformas de datos se implementan en estas ubicaciones, los resultados del procesamiento y análisis de datos en redes distribuidas se pueden agregar y replicar en la plataforma de datos central.
Esta arquitectura también mejora la funcionalidad de la nube. Puede seguir utilizándose como una forma económica de archivar datos a largo plazo, pero la interoperabilidad permite que los datos se repliquen en todas las ubicaciones y se administren utilizando la misma interfaz de usuario que el centro de datos en el sitio.
La tercera parte de este blog sigue mañana.
El autor de este blog es Bob Emmerson, escritor y comentarista independiente de IoT
Tecnología de Internet de las cosas
- 10 beneficios de usar Cloud Storage
- Hiperconvergencia y cálculo en el borde:Parte 3
- Hiperconvergencia e Internet de las cosas:Parte 1
- Por qué los macrodatos y la analítica de edificios no van a ninguna parte:Parte 1
- Construyendo una IA responsable y confiable
- IoT y su comprensión de los datos
- IoT y AI avanzan en tecnología
- El futuro de la integración de datos en 2022 y más allá
- Tendencias de IIoT y desafíos a seguir
- Cómo hacer que IOT sea real con Tech Data e IBM Part 2
- Cómo hacer que IoT sea real con Tech Data e IBM Parte 1