


Cómo las pruebas fuzz fortalecen la seguridad de los dispositivos de IoT
Las pruebas fuzz representan un lugar importante disponible para los ingenieros para encontrar debilidades en dispositivos y debe tenerse en cuenta para reforzar las interfaces de los dispositivos de IoT.
Con la proliferación de dispositivos IoT, se incrementan los ataques de seguridad integrados. Históricamente, los ingenieros de sistemas integrados han ignorado la seguridad de la capa del dispositivo a pesar de las muchas áreas de los dispositivos integrados que son vulnerables a errores. Los piratas informáticos pueden aprovechar los puertos seriales, las interfaces de radio e incluso las interfaces de programación / depuración. Las pruebas fuzz representan un lugar importante a disposición de los ingenieros para encontrar debilidades en los dispositivos integrados, y deben tenerse en cuenta para fortalecer las interfaces de los dispositivos de IoT.
¿Qué es la prueba de fuzz?
La prueba de fuzz es como el mítico millón de monos que escriben al azar para escribir Shakespeare. En la práctica, las obras de ficción requieren muchas combinaciones aleatorias para producir una frase simple, pero para los sistemas integrados, solo necesitamos cambiar algunas letras de una oración buena conocida.
Se encuentran disponibles numerosas herramientas comerciales y de código abierto para implementar ataques fuzz. Estas herramientas generan cadenas de bytes aleatorios, también llamados vectores fuzz o vectores de ataque, y los envían a la interfaz que se está probando, realizando un seguimiento del comportamiento resultante que podría significar un error.
La prueba de fuzz es un juego de números, pero no podemos probar un número infinito de entradas posibles. En cambio, nos enfocamos en optimizar el tiempo de prueba maximizando la tasa de envío de vectores de fuzz, la efectividad de los vectores de fuzz y los algoritmos de detección de errores.
Conceptos de prueba de fuzz
Debido a que muchas herramientas de prueba de fuzz fueron diseñadas para probar aplicaciones de PC, es más fácil adaptarlas si ejecuta su código incrustado como una aplicación de PC compilada de forma nativa. La ejecución de código incrustado en una PC ofrece una gran ventaja de rendimiento, pero tiene dos inconvenientes. Primero, los microprocesadores de PC no reaccionan igual que los microcontroladores integrados. En segundo lugar, debemos volver a escribir cualquier código que toque el hardware. Sin embargo, en la práctica, las ventajas de ejecutar en una PC superan a las desventajas. La verdadera barrera es la dificultad de migrar el código para compilarlo de forma nativa en la PC.
¿Cómo sabemos cuando un vector de fuzz desencadena un error? Un accidente es fácil de detectar, pero es más difícil identificar los vectores de fuzz que provocan un reinicio. Los errores de desbordamiento de memoria o las escrituras de puntero perdidas, el tipo de error más valioso para los piratas informáticos, son casi imposibles de discernir desde fuera del sistema, ya que normalmente no provocan un bloqueo o un reinicio.
Muchos compiladores modernos, como GCC y Clang, tienen una función llamada saneamiento de memoria. Esto marca los bloques de memoria como limpios o sucios, dependiendo de si están en uso, y marca cualquier intento de acceder a la memoria sucia. Sin embargo, la desinfección de la memoria consume flash, RAM y ciclos de CPU, lo que dificulta su ejecución en dispositivos integrados. Entonces, en cambio, podemos probar un subconjunto de código, construir una versión del dispositivo con más recursos o usar una PC.
La efectividad de una prueba se puede evaluar por la cantidad de código que se ejerce. Aquí también, los compiladores pueden rastrear el uso de la memoria mediante el empleo de llamadas a subrutinas de migajas de pan. La biblioteca de cobertura de código mantiene una tabla de valores de uso para cada ruta de código, incrementándolos cuando se ejecuta la miga de pan.
Sin embargo, los números de cobertura de código son difíciles de interpretar para las pruebas de fuzz incrustadas porque gran parte del código es inaccesible para los vectores de fuzz; por ejemplo, un controlador de dispositivo para un periférico que se ejecuta independientemente de la interfaz. Por lo tanto, es difícil definir la "cobertura de código completa" para los sistemas integrados; quizás solo el 20% del código integrado sea accesible. La cobertura de código también consume grandes cantidades de flash, RAM y ciclos de CPU y necesitaría hardware especializado o un objetivo de PC para ejecutarse.
Informe de errores
Cuando la prueba de fuzz encuentra un vector que causa un comportamiento no deseado, necesitamos información detallada. ¿Dónde ocurrió el error? ¿Cuál es el estado de la pila de llamadas? ¿Cuál es el tipo específico de error? Toda esta información ayuda a clasificar y eventualmente corregir el error.
La clasificación de errores es crucial en las pruebas de fuzz. Los nuevos proyectos fuzz a menudo encuentran muchos errores y necesitamos una forma automática de determinar su gravedad. Además, los errores de fuzz tienden a bloquear errores porque a menudo enmascaran errores adicionales más adelante en la ruta del código. Necesitamos una solución rápida para los problemas que surgen durante las pruebas de fuzz.
Los clientes integrados no están tan dispuestos a revelar su información como las PC. Por lo general, un bloqueo simplemente hará que el dispositivo se reinicie y reinicie. Si bien esto se desea en el campo, borra el estado del dispositivo, lo que dificulta saber si ocurrió un bloqueo, dónde o por qué sucedió, o la ruta del código que se tomó. El ingeniero debe encontrar un vector de reproducción consistente y luego usar un depurador para rastrear el mal comportamiento y encontrar el error.
En las pruebas de fuzz, una prueba puede producir miles de vectores de fallas para algunos errores, dando la falsa impresión de un sistema con errores. Es importante determinar rápidamente qué vectores están asociados con el mismo error subyacente. En el caso de los dispositivos integrados, la ubicación del bloqueo en sí suele ser única para el error y, por lo general, no es necesario para encontrar el seguimiento completo de la pila de llamadas.
Prueba de fuzz continua
Debido a la naturaleza estocástica de las pruebas de fuzz, ejecutarlas durante períodos más largos aumenta las posibilidades de encontrar problemas. Pero ningún plan de proyecto podría absorber las demoras de un largo ciclo de pruebas fuzz al final del desarrollo.
En la práctica, las pruebas de fuzz comenzarían en su propia rama después del proceso de lanzamiento. Cualquier error recién descubierto se arreglaría en la sucursal local, de modo que la prueba podría continuar sin que los nuevos errores bloqueen el descubrimiento de errores adicionales. Como parte del ciclo de lanzamiento, los errores descubiertos a partir de las pruebas de fuzz en lanzamientos anteriores se evaluarían para su inclusión en nuevos lanzamientos. Finalmente, los vectores de fuzz que han descubierto un error deben agregarse a los procesos normales de control de calidad para verificar la corrección y garantizar que estos errores no se reintroduzcan inadvertidamente en el código.
Deberíamos ejecutar pruebas de fuzz de dispositivos en diferentes escenarios; por ejemplo, un dispositivo responde a las solicitudes de conexión de manera diferente si está en red. No es práctico ejecutar pruebas de fuzz en todos los escenarios posibles, pero podemos incluir pruebas de fuzz para cada valor de estado posible. Por ejemplo, ejecute pruebas de fuzz con cada tipo de dispositivo diferente mientras mantiene las otras variables iguales. Luego, ejecute diferentes valores para otra variable, como el estado de conectividad de la red, para un tipo de dispositivo.
Arquitecturas de prueba fuzz
Dos arquitecturas de prueba de fuzz prominentes son fuzzing, donde un ingeniero especifica los vectores de fuzz antes de la prueba, y pruebas de fuzz guiadas por cobertura, donde la herramienta de fuzz comienza con un conjunto inicial de vectores de prueba y los muta automáticamente en función de qué tan bien penetran los paquetes. el código.
Además, no todo el código se ejecutará en una PC, y desarrollar un simulador de PC para una aplicación integrada puede no ser práctico, dependiendo de lo que se esté probando.
A continuación se muestra un resumen de cuatro arquitecturas de prueba de fuzz:
- Prueba de interfaz directa en hardware integrado:ejecución de la imagen de producción normal en el dispositivo integrado con paquetes fuzz inyectados a través de la interfaz
- Prueba de inyección de paquetes (pila):llamada a rutinas de paquetes entrantes directamente sin tener que ejercitar la interfaz por aire
- Fuzzing dirigido con un simulador, utilizando técnicas de simulación basadas en PC para desarrollar y probar código incrustado
- Fuzzing guiado por cobertura con un simulador (que se muestra como Libfuzz a continuación)
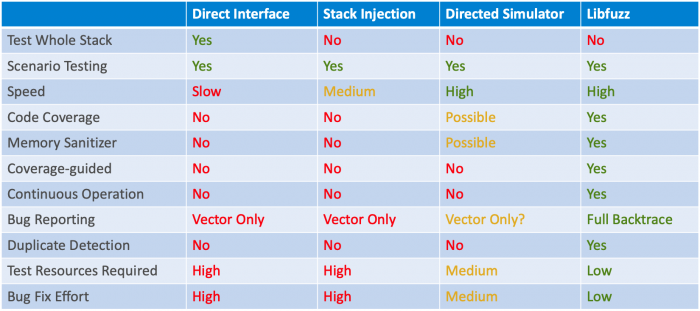
Varios probadores de fuzz
Después de bloquear un dispositivo integrado con bloqueo de interfaz de depuración y arranque seguro, debemos considerar las pruebas de fuzz de las interfaces del dispositivo. Muchas de las mismas herramientas y conceptos que se utilizan para proteger los servidores web se pueden adaptar para su uso con dispositivos integrados.
Utilice la herramienta adecuada para el trabajo. El fuzzing guiado por cobertura es necesario para las pruebas de fuzz continuas, pero si su código solo se ejecuta en hardware integrado, los fuzzers dirigidos pueden ser una buena opción para proporcionar cierto nivel de cobertura de la prueba de fuzz.
Finalmente, debe emplear múltiples probadores de fuzz en tantos escenarios como sea posible, ya que cada uno probará el dispositivo de manera ligeramente diferente, maximizando la cobertura y, por lo tanto, la seguridad de su dispositivo integrado.
>> Este artículo se publicó originalmente el nuestro sitio hermano, EDN.
Tecnología de Internet de las cosas
- Cómo 5G acelerará el IoT industrial
- Cómo IoT está abordando las amenazas a la seguridad en el petróleo y el gas
- El camino hacia la seguridad industrial de IoT
- Cómo IoT conecta los lugares de trabajo
- Facilitar el aprovisionamiento de IoT a escala
- Seguridad de IoT:¿de quién es la responsabilidad?
- Seguridad de IoT:¿una barrera para la implementación?
- Cómo los ajustes en la cadena de suministro de IoT pueden cerrar las brechas de seguridad
- Internet de advertencias:cómo la tecnología inteligente puede amenazar la seguridad de su empresa
- Seguridad de IoT:cómo impulsar la transformación digital mientras se minimiza el riesgo
- NIST publica borrador de recomendaciones de seguridad para fabricantes de IoT