


Detección de tos con TinyML en Arduino
Componentes y suministros
 |
| × | 1 |
Aplicaciones y servicios en línea
 |
|
Acerca de este proyecto
Existe una gran necesidad de soluciones económicas y fáciles de implementar para la detección temprana de COVID-19 y otras infecciones relacionadas con la influenza. Junto con la ONU, Hackster, Edge Impulse y muchos otros, lanzamos recientemente el Desafío UN Covid Detect &Protect con el objetivo de crear soluciones fáciles de implementar para la prevención y detección de la gripe en países en desarrollo. En este tutorial mostramos cómo usar el aprendizaje automático de Edge Impulse en un Arduino Nano BLE Sense para detectar la presencia de tos en audio en tiempo real. Creamos un conjunto de datos de muestras de tos y ruido de fondo, y aplicamos un modelo de TInyML altamente optimizado para construir un sistema de detección de tos que se ejecuta en tiempo real en menos de 20 kB de RAM en el Nano BLE Sense. Este mismo enfoque se aplica a muchas otras aplicaciones de coincidencia de patrones de audio integradas, por ejemplo, cuidado de personas mayores, seguridad y monitoreo de máquinas. Este proyecto y conjunto de datos fue iniciado originalmente por Kartik Thakore para ayudar en el esfuerzo de COVID-19.
Empezando
Este tutorial tiene los siguientes requisitos:
- Comprensión básica del desarrollo de software y Arduino
- Arduino IDE o CLI instalado
- Teléfono móvil Android o iOS
- Arduino Nano BLE Sense o placa Cortex-M4 + equivalente con micrófono (opcional)
Usaremos Edge Impulse, una plataforma de desarrollo en línea para aprendizaje automático en dispositivos periféricos. Cree una cuenta gratuita registrándose aquí. Inicie sesión en su cuenta y asigne un nombre a su nuevo proyecto haciendo clic en el título. Al nuestro lo llamamos el "Tutorial de tos Arduino".
Recopilar el conjunto de datos
El primer paso en cualquier proyecto de aprendizaje automático es recopilar un conjunto de datos que represente muestras conocidas de datos que nos gustaría poder comparar en nuestro dispositivo Arduino. Para empezar, hemos creado un pequeño conjunto de datos con 10 minutos de audio en dos clases, "tos" y "ruido". Le mostraremos cómo importar este conjunto de datos a su proyecto Edge Impulse, agregar sus propias muestras o incluso comenzar su propio conjunto de datos desde cero. Este conjunto de datos es pequeño y tiene un número limitado de muestras de tos y ruido de fondo suave. Por lo tanto, el conjunto de datos es apropiado solo para la experimentación, y el modelo producido en este tutorial solo puede diferenciar entre un ruido de fondo silencioso y una pequeña variedad de toses. Le recomendamos que amplíe el conjunto de datos con una gama más amplia de tos, ruido de fondo y otras clases como el habla humana para mejorar el rendimiento.
Nota: Obligarse a toser es muy duro para sus cuerdas vocales, ¡tenga cuidado al recopilar datos y realizar pruebas!
Primero descargue nuestro conjunto de datos de tos y extraiga el archivo en su PC en la ubicación que elija:https://cdn.edgeimpulse.com/datasets/cough.zip
Puede importar este conjunto de datos a su proyecto de Edge Impulse mediante el cargador de CLI de Edge Impulse. Instale la CLI de Edge Impulse siguiendo estas instrucciones de instalación.
Abra una terminal o símbolo del sistema y navegue hasta la carpeta donde extrajo el archivo.
Ejecutar:
$ edge-impulse-uploader --clean
$ edge-impulse-uploader - capacitación de capacitación de categoría / *
$ edge-impulse-uploader - prueba de categoría prueba / * Se le pedirá su nombre de usuario, contraseña de Edge Impulse y el proyecto donde desea agregar el conjunto de datos. Las muestras del conjunto de datos ahora estarán visibles en la adquisición de datos página. Al hacer clic en una muestra, podemos ver cómo se ve la muestra y escuchar el audio haciendo clic en el botón de reproducción debajo de cada gráfico.
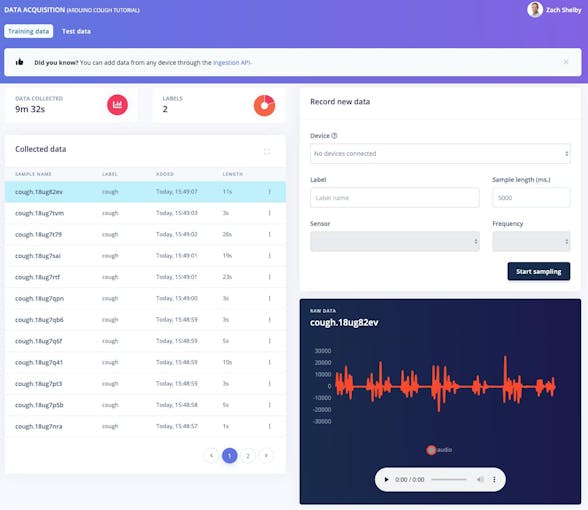
10 minutos de muestras de datos de tos y ruido son suficientes para comenzar. Opcionalmente, puede ampliar el conjunto de datos con sus propias muestras de tos y ruido de fondo. Podemos recopilar nuevas muestras de datos directamente de los dispositivos desde la adquisición de datos página. Las muestras de audio en formato WAV también se pueden cargar usando Edge Impulse CLI Uploader.
La forma más sencilla de comenzar es recopilar datos de audio con su teléfono móvil (tutorial completo aquí). Ve a Dispositivos . página y haga clic en el botón "+ Conectar un nuevo dispositivo" en la esquina superior derecha. Seleccione "Usar su teléfono móvil". Esto producirá un código QR único para abrir una aplicación web en el navegador de su teléfono. Tome una foto del código QR y seleccione para abrir el enlace.
La aplicación web se conectará con su proyecto de Edge Impulse y debería verse así:
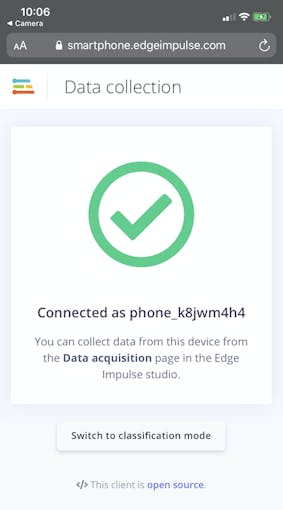
Ahora podemos recopilar muestras de datos de audio directamente desde el teléfono desde la adquisición de datos página de Edge Impulse. En la sección "Registrar datos nuevos", escriba una etiqueta de "tos" o "ruido", asegúrese de que "Micrófono" esté seleccionado como sensor y haga clic en "Iniciar muestreo". Su teléfono ahora recopilará una muestra de audio y la agregará a su conjunto de datos.
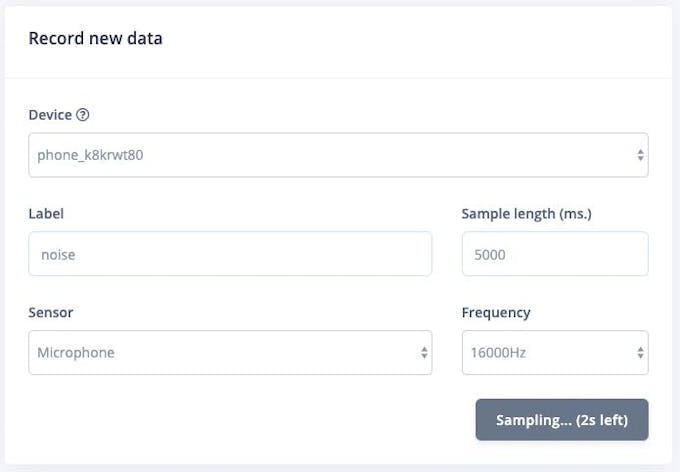
También se admite la recopilación de datos de audio directamente desde la placa Nano BLE Sense. Siga estas instrucciones para instalar el firmware y el demonio de Edge Impulse. Una vez que el dispositivo está conectado a Edge Impulse, puede recopilar muestras de datos como con su teléfono móvil anterior.

Creando tu impulso
A continuación, seleccionaremos bloques de procesamiento de señales y aprendizaje automático, en la sección Crear impulso página. El impulso comenzará en blanco, con datos brutos y bloques de funciones de salida. Deje la configuración predeterminada de un tamaño de ventana de 1000 ms y un aumento de ventana de 500 ms. Esto significa que nuestros datos de audio se procesarán 1 s a la vez, comenzando cada 0,5 s. El uso de una ventana pequeña ahorra memoria en el dispositivo integrado, pero significa que necesitamos datos de muestra de tos sin grandes interrupciones entre toses.
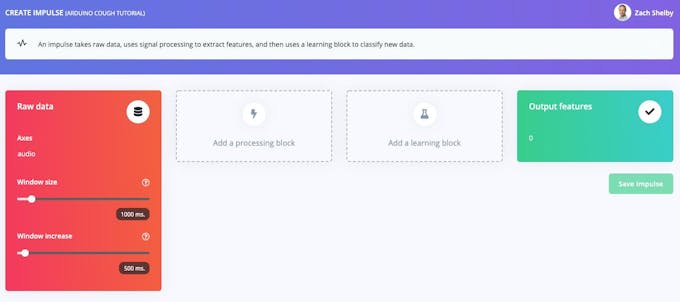
Haga clic en "Agregar un bloque de procesamiento" y seleccione Audio (MFCC) cuadra. A continuación, haga clic en "Agregar un bloque de aprendizaje" y seleccione Red neuronal (Keras) cuadra. Haga clic en "Guardar impulso". El bloque de audio extraerá un espectrograma para cada ventana de audio, y el bloque de la red neuronal se entrenará para clasificar el espectrograma como "tos" o "ruido" según nuestro conjunto de datos de entrenamiento. Su impulso resultante se verá así:
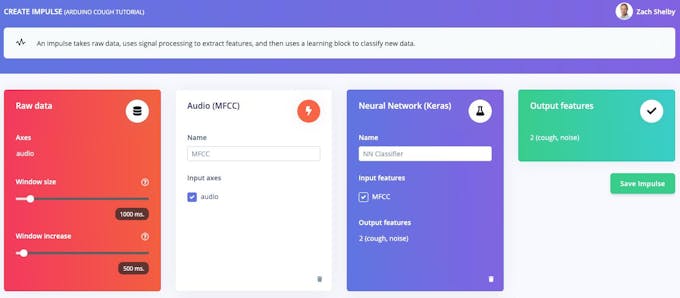
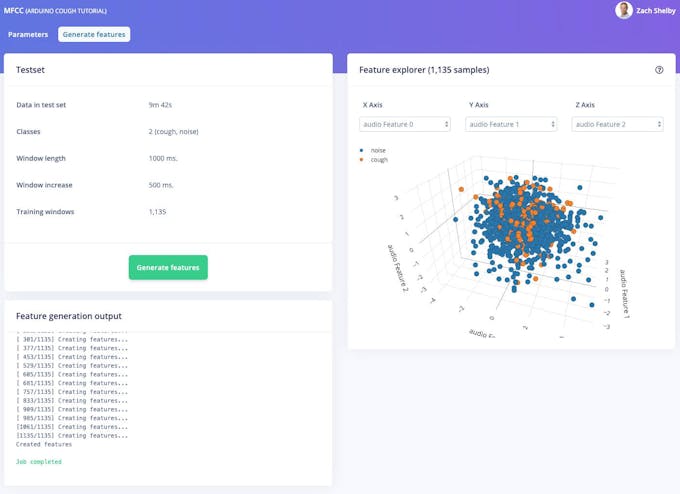
A continuación, generaremos funciones a partir del conjunto de datos de entrenamiento en MFCC página. Esta página muestra cómo se ve el espectrograma extraído para cada ventana de 1 segundo de cualquiera de las muestras del conjunto de datos. Podemos dejar los parámetros en sus valores predeterminados.
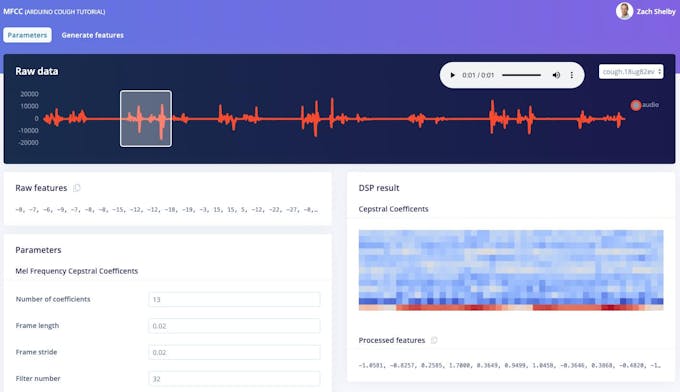
A continuación, haga clic en el botón "Generar funciones", que luego procesa todo el conjunto de datos de entrenamiento con este bloque de procesamiento. Esto crea el conjunto completo de características que se utilizarán para entrenar nuestra red neuronal en el siguiente paso. Presione el botón "Generar funciones" para iniciar el procesamiento; esto tardará un par de minutos en completarse.
Ahora podemos proceder a configurar y entrenar nuestra red neuronal en el Clasificador NN página. La red neuronal predeterminada funciona bien para sonidos continuos como el agua corriendo. La detección de tos es más complicada, por lo que configuraremos una red más rica utilizando convolución 2D en el espectrograma de cada ventana. La convolución 2D procesa el espectrograma de audio de manera similar a la clasificación de imágenes. Presiona la esquina superior derecha de la sección "Configuración de la red neuronal" y selecciona "Cambiar al modo Keras (experto)".
Reemplace la definición de "Arquitectura de red neuronal" con el siguiente código y establezca la configuración de "Calificación de confianza mínima" en "0.70". Luego proceda a hacer clic en el botón "Comenzar a entrenar". El entrenamiento tomará unos segundos.
importar tensorflow como tf
de tensorflow.keras.models import Sequential
de tensorflow.keras.layers import Dense, InputLayer, Dropout, Flatten, Reshape, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D
de tensorflow.keras.optimizers importar Adam
de tensorflow.keras.constraints importar MaxNorm
# arquitectura modelo
modelo =Sequential ()
model.add (InputLayer ( input_shape =(X_train.shape [1],), name ='x_input'))
model.add (Reshape ((int (X_train.shape [1] / 13), 13, 1), input_shape =( X_train.shape [1],)))
model.add (Conv2D (10, kernel_size =5, activación ='relu', padding ='same', kernel_constraint =MaxNorm (3)))
model.add (AveragePooling2D (pool_size =2, padding ='same'))
model.add (Conv2D (5, kernel_size =5, activation ='relu', padding ='same', kernel_constraint =MaxNorm (3 )))
model.add (AveragePooling2D (pool_size =2, padding ='same'))
model.add (Flatten ())
model.add (Dense (clases, activación ='softmax', nombre ='y_pred', kernel_co nstraint =MaxNorm (3)))
# esto controla la tasa de aprendizaje
opt =Adam (lr =0.005, beta_1 =0.9, beta_2 =0.999)
# entrena la red neuronal
model.compile (loss ='categorical_crossentropy', optimizer =opt, metrics =['precisión'])
model.fit (X_train, Y_train, batch_size =32, epochs =9, validation_data =(X_test, Y_test) , detallado =2) La página mostrará el rendimiento del entrenamiento y el rendimiento en el dispositivo, que debería ser así según su conjunto de datos:
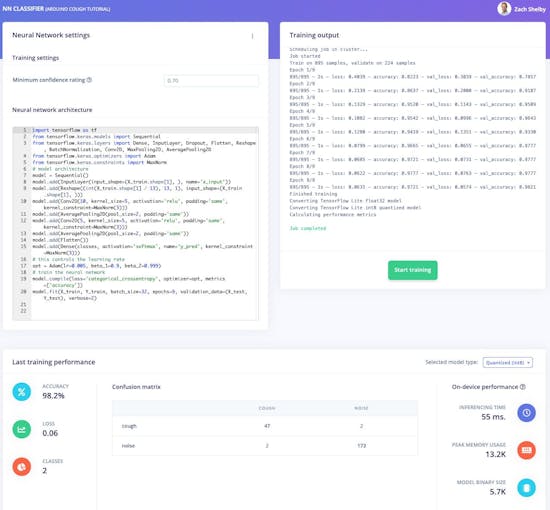
¡Nuestro algoritmo de detección de tos Arduino ya está listo para probar!
Entrenamiento y pruebas
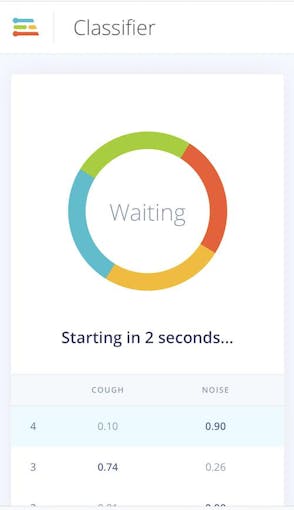
La clasificación en vivo La página nos permite probar el algoritmo con los datos de prueba existentes que vinieron con el conjunto de datos o mediante la transmisión de datos de audio desde su teléfono móvil o dispositivo Arduino. Podemos comenzar con una prueba simple eligiendo cualquiera de las muestras de prueba y presionando "Cargar muestra". Esto clasificará la muestra de prueba y mostrará los resultados:
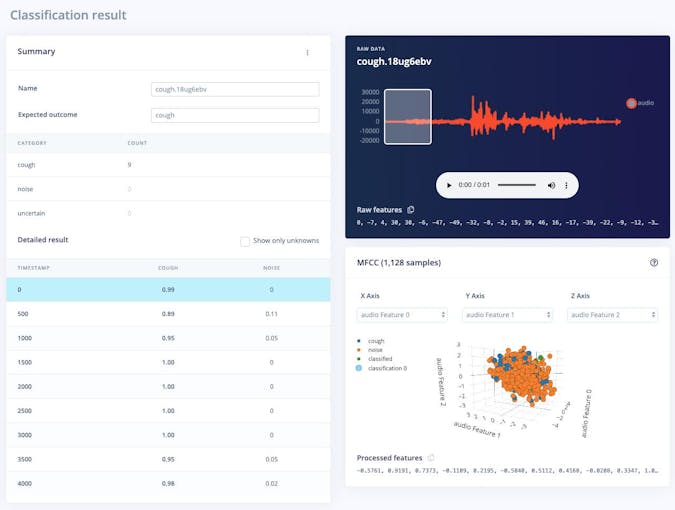
También podemos probar el algoritmo con datos en vivo. Comience con su teléfono móvil actualizando la página del navegador en su teléfono que abrimos anteriormente. Luego, seleccione su dispositivo en la sección "Clasificar datos nuevos" y presione "Iniciar muestreo". De manera similar, puede transmitir muestras de audio desde su Nano BLE Sense cuando está conectado al proyecto a través del demonio de impulso de borde como en el paso de recopilación de datos.
Implementación
Podemos implementar fácilmente nuestro algoritmo de detección de tos en el teléfono móvil. Vaya a la ventana del navegador en su teléfono y actualice, luego presione el botón "Cambiar al modo de clasificación". Esto construirá automáticamente el proyecto en un paquete WebAssembly y lo ejecutará en su teléfono de forma continua (no se requiere la nube después de eso, ¡incluso irá al modo avión!)
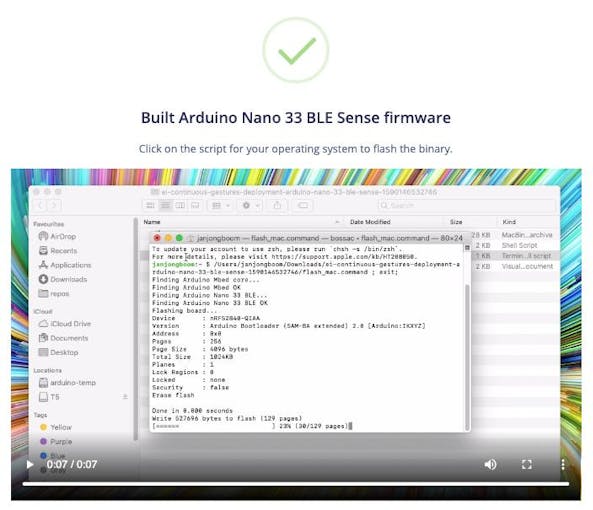
A continuación, podemos implementar el algoritmo en Nano BLE Sense yendo a Implementación página. Seleccione "Arduino Nano 33 BLE Sense" en "Build firmware" y luego haga clic en "Build".

Esto creará un firmware completo para el Nano BLE Sense, incluido su último algoritmo. Siga las instrucciones en la pantalla para actualizar su placa Arduino con el binario.
Una vez que el Arduino está flasheado, podemos abrir un puerto serie al dispositivo mientras está conectado al USB a 115, 200 baudios. Una vez que el puerto serie esté abierto, presione enter para obtener un mensaje y luego:
> AT + RUNIMPULSE
Configuraciones de inferencia:
Intervalo:0.06 ms.
Tamaño de cuadro:16000
Longitud de muestra:1000 ms.
No. de clases:2
Comenzando la inferencia, presione 'b' para romper
Grabación ...
Grabación realizada
Predicciones (DSP:495 ms., Clasificación:84 ms., Anomalía :0 ms.):
tos:0.01562
ruido:0.98438
Comenzando la inferencia en 2 segundos ...
Grabando ...
Grabación terminada
Predicciones (DSP:495 ms., Clasificación:84 ms., Anomalía:0 ms.):
tos:0.01562
ruido:0.98438
Iniciando inferencia en 2 segundos ...
Grabación ...
Grabación realizada
Predicciones (DSP:495 ms., Clasificación:84 ms., Anomalía:0 ms.):
tos:0,86719
ruido:0,13281
Comenzando la inferencia en 2 segundos ...
Grabación ...
Grabación realizada
Predicciones (DSP:495 ms., Clasificación:84 ms., Anomalía:0 ms.) :
tos:0.01562
ruido:0.98438
Trabajo futuro
El cielo es el límite con TinyML, sensores y Edge Impulse en Arduino, aquí hay algunas ideas para seguir trabajando:
- Amplíe el conjunto de datos predeterminado con su propia tos y sonidos de fondo, recuerde volver a capacitarse periódicamente y realizar pruebas. Puede configurar pruebas unitarias en la página Pruebas para asegurarse de que el modelo siga funcionando a medida que se amplía.
- Agregue una nueva clase y datos para los sonidos humanos que no son tos, como habla de fondo, bostezos, etc.
- Comience con un nuevo conjunto de datos y recopile muestras de audio para detectar algo nuevo. Sugerencia:puede cargar solo los datos de la clase de ruido de este conjunto de datos para comenzar.
- A partir de estas instrucciones, impleméntelo en la biblioteca Arduino como parte de un boceto de Arduino para mostrar la detección de tos mediante el LED o una pantalla
- Utilice otros sensores como el acelerómetro de 3 ejes del Nano BLE Sense siguiendo este tutorial.
Proceso de manufactura
- Monitoreo de CO2 con sensor K30
- Comunicación para personas sordociegas con 1Sheeld / Arduino
- Controlar el aceptador de monedas con Arduino
- ¡Arduino con Bluetooth para controlar un LED!
- Sensor capacitivo de huellas dactilares con Arduino o ESP8266
- Jugando con Nextion Display
- Brazo robótico controlado por Nunchuk (con Arduino)
- Determinación de la salud de una planta con TinyML
- Sistema de monitoreo y detección de incendios forestales (con alertas por SMS)
- Medición de la radiación solar con Arduino
- Mini radar con Arduino