


Los SoC habilitados para AI manejan múltiples transmisiones de video
Ambarella lanza dos dispositivos para visión por computadora y procesamiento de AI desde múltiples o Entradas únicas en cámaras de seguridad y sistemas de ciudad inteligente.
Ambarella, especialista en procesamiento de imágenes, ha lanzado dos nuevos SoC para cámaras de seguridad de sensor único y múltiple, cada uno con nuevas capacidades de inteligencia artificial habilitadas por el motor acelerador CVflow AI de la compañía. Ambos admiten codificación de video 4K y procesamiento avanzado de inteligencia artificial, como reconocimiento facial o reconocimiento de matrículas.
El CV5S SoC apunta a sistemas de cámaras multisensor, codificando cuatro canales de imagen de hasta 8MP / 4K de resolución, cada uno a 30 cuadros por segundo (fps) mientras realiza IA avanzada en cada flujo de imagen 4K. Puede manejar hasta 14 entradas. La familia SoC duplica la resolución de codificación y el ancho de banda de memoria de la generación anterior de productos de Ambarella mientras consume un 30 por ciento menos de energía. Consume <5W y proporciona 12 eTOPS (TOPS equivalente a GPU, la medida de Ambarella de la cantidad de caballos de fuerza de GPU necesarios para ejecutar las mismas tareas de procesamiento de IA).
El otro nuevo SoC, CV52S, apunta a cámaras de sensor único y admite resolución 4K a 60 fps. En comparación con las generaciones anteriores de Ambarella SoC, este nuevo dispositivo cuadriplica el rendimiento de la IA, duplica el rendimiento de la CPU y ofrece un 50 por ciento más de ancho de banda de memoria. Consume <3 W y proporciona 6 eTOPS.
El aumento del rendimiento se debe a la migración al nodo de proceso de 5 nm junto con las mejoras y la ampliación del bloque acelerador de AI CVflow interno de Ambarella.
"Ves que todas estas startups vienen de todas partes, dicen que tienen el mejor rendimiento de IA por vatio, y pueden tener razón", dijo Jerome Gigot, director senior de marketing de Ambarella. “Pero eso no hace una cámara, eso no hace un producto. Si solo tiene un acelerador de IA, solo tiene un acelerador de IA ".
Gigot señaló que una canalización de imágenes para video 4K u 8K es compleja, maneja una gran cantidad de datos, codifica grandes volúmenes de datos, transfiere esos datos a un bloque especial para el procesamiento de IA mientras probablemente ejecuta una pila de Linux en la parte superior. Eso es difícil de lograr con presupuestos bajos de energía y al mismo tiempo se mantiene la calidad del video.
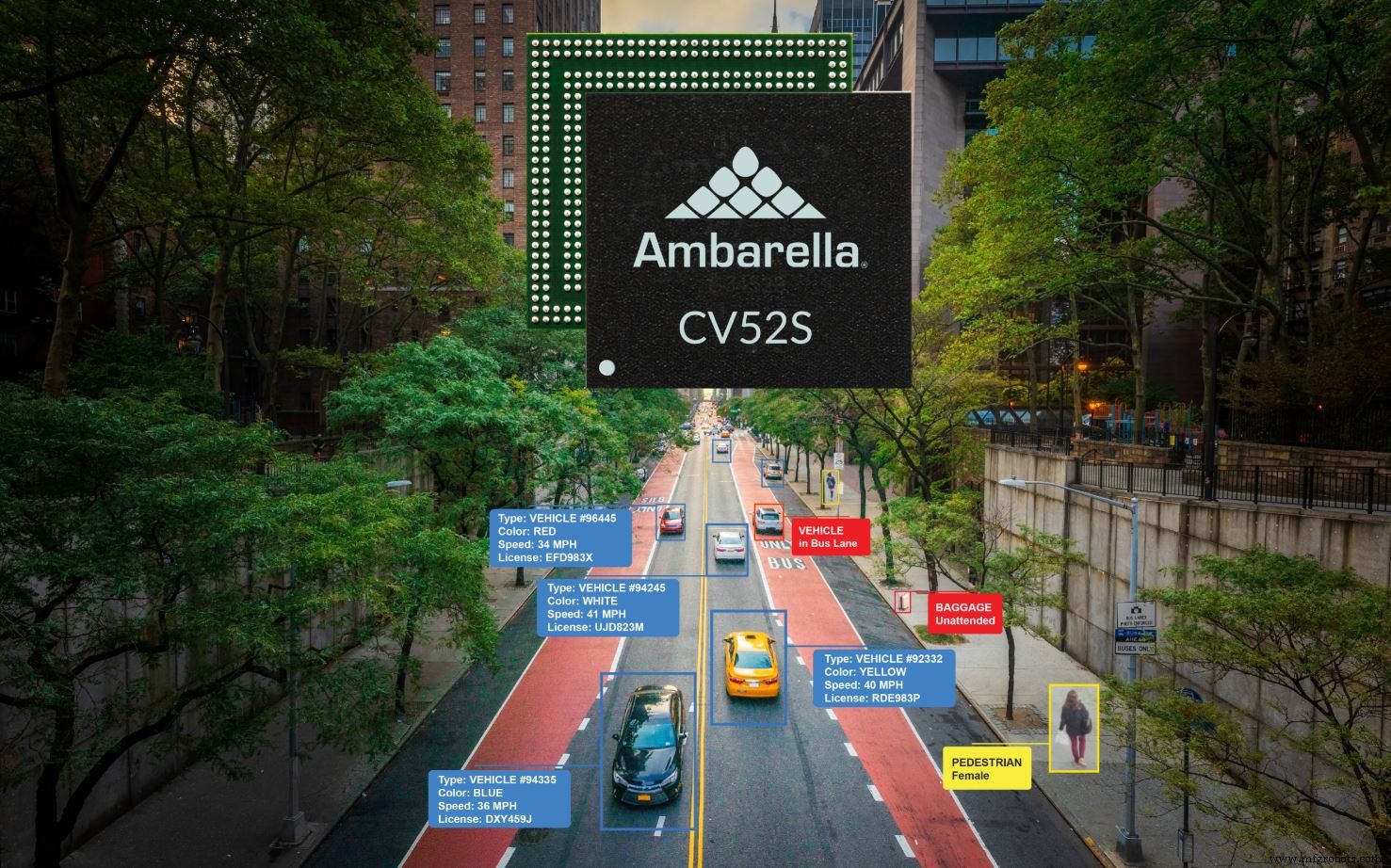
El CV52S apunta a diseños de sensor único como los que se encuentran en el monitoreo del tráfico y otras aplicaciones de ciudades inteligentes (Fuente:Ambarella)
Junto con el acelerador CVflow AI, los dos nuevos SoC incluyen el procesador de señal de imagen (ISP) de Ambarella que maneja funciones como procesamiento de color, exposición automática, balance de blancos automático y filtrado de ruido.
"Este bloque lo hemos estado desarrollando durante 16 años", dijo Gigot. “Por eso creemos que a las startups todavía les queda un largo camino por recorrer. Podrían licenciar [un bloque ISP de otro lugar] pero entonces no está realmente integrado con el resto del sistema en términos de acceso a la memoria y todo lo demás ".
El sistema de memoria es una de las piezas clave de la propiedad intelectual de la empresa.
“Tenemos un controlador de memoria y lo organizamos todo para que cuando obtengamos datos en el chip. Tratamos de no hacer ninguna copia ”, dijo Gigot. “Movemos los punteros, no los datos. Eso solo es posible si diseña toda la arquitectura desde cero, sabiendo exactamente lo que va a hacer el chip ".
Motor acelerador
El acelerador de AI es un procesador vectorial que puede acelerar la convolución y otras funciones comunes de AI, o puede usarse para cargas de trabajo clásicas de visión por computadora. Los usuarios también pueden optar por ejecutar partes de una red neuronal (como algoritmos de clasificación en una red de detectores de disparo único) o mediante una CPU Arm Cortex-A76 de doble núcleo en chip.
La pila de software permite que las aplicaciones aprovechen la escasez de coeficientes, una técnica mediante la cual los coeficientes de red con valores cercanos a cero se redondean a cero. El enfoque puede "podar" "ramas" enteras de cálculos del algoritmo para reducir enormemente los requisitos informáticos.
La esparsificación "es una técnica realmente efectiva para nosotros porque cuando hay un coeficiente cero, en nuestra arquitectura no hacemos la operación, tenemos una [función] de salto", dijo. “Así que no calculamos el resultado de ese coeficiente. Nos lleva prácticamente cero ciclos ".
El proceso identifica típicamente del 50 al 80 por ciento de los coeficientes como objetivos para la dispersión, dijo Gigot. Por lo general, se requiere un poco de reentrenamiento después de la dispersión para recuperar la precisión de predicción perdida durante el proceso. Según Gigot, la reentrenamiento generalmente puede traer precisión dentro del 1 por ciento del modelo original, una compensación aceptable para la mayoría de los clientes, especialmente con una reducción del tamaño del modelo de hasta 5 veces. Ambarella también está trabajando en herramientas de esparcimiento y cuantificación que son más conscientes de la arquitectura.
haga clic para ver la imagen a tamaño completo
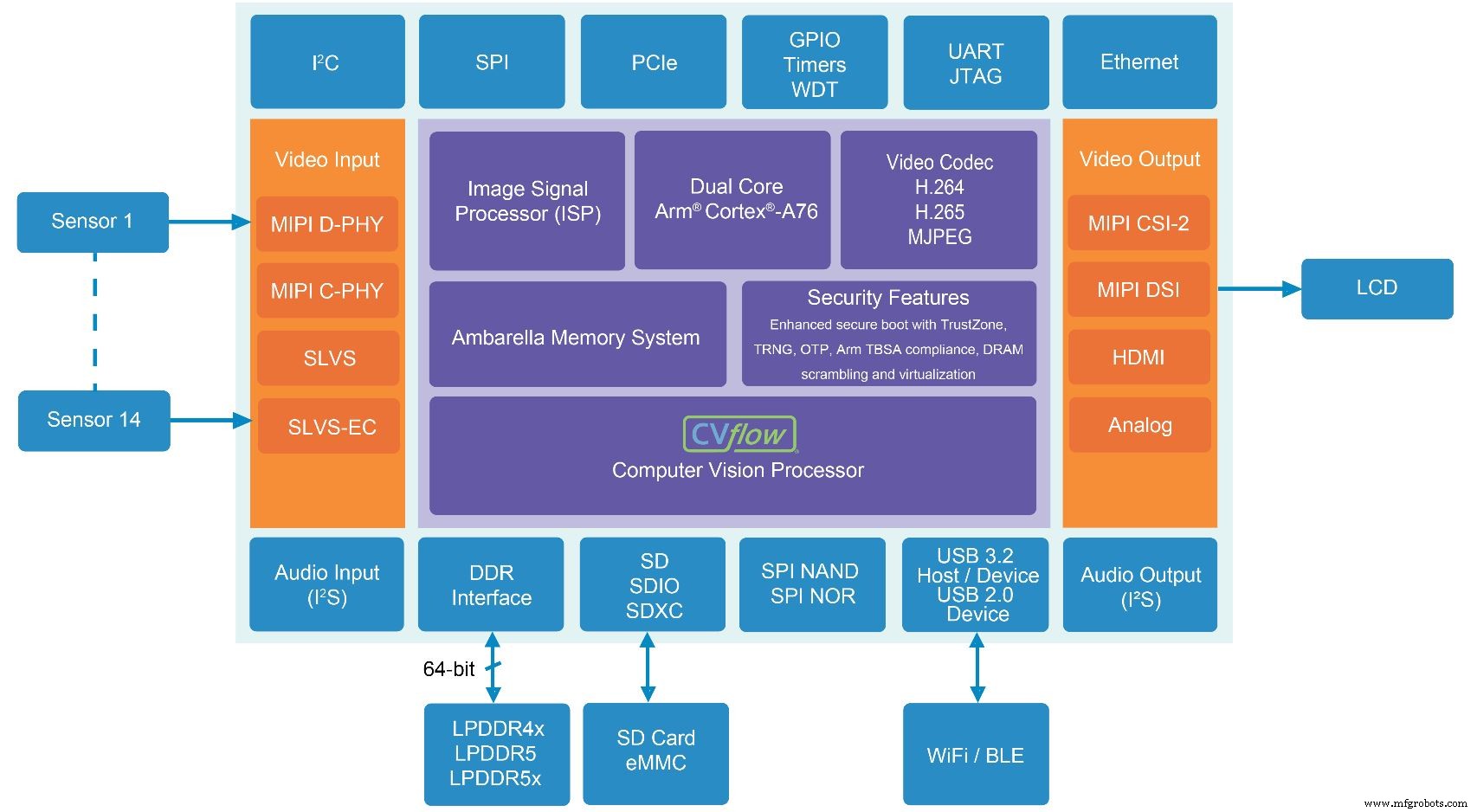
El CV5S SoC para sistemas de cámaras multisensor incluye la última generación de CVflow AI y acelerador de visión por computadora de Ambarella (Fuente:Ambarella)
Con la capacidad de aceptar hasta 14 transmisiones de video y luego realizar IA en esas transmisiones simultáneamente, ¿los clientes ejecutarán múltiples redes neuronales simultáneamente? ¿Se requerirá algún tipo de esquema de multiplexación?

Jerome Gigot (Fuente:Ambarella)
Sí a ambos, respondió Gigot. “El CVflow es un motor vectorial muy rápido, un motor de convolución muy rápido. Todo está multiplexado en el tiempo. Tenemos diferentes rutas en el hardware para que podamos paralelizar las operaciones, pero no lo vinculamos a una red específica [que es] totalmente diferente al procesamiento por lotes en una GPU ".
El procesamiento por lotes, una técnica empleada a menudo por las GPU de gran tamaño, agrupa las imágenes y las envía para su procesamiento en paralelo. Las GPU ya tienen otros parámetros cargados. Ese enfoque reduce el costo de computación al no tener que cambiar entre operaciones.
Para motores más pequeños como CVflow, las redes neuronales más grandes deben dividirse en trozos para ser procesadas, ya que la memoria del chip no puede almacenar todos los parámetros a la vez. Los fragmentos consecutivos pueden originarse en la misma red neuronal, en otra red u otra entrada de canal. La utilización típica de hardware en CVflow está entre el 70 y el 80 por ciento, dijo Gigot, y agregó que el cambio de redes / canales no afecta la eficiencia.
Se espera que CV5S y CV52S comiencen a muestrear en octubre de 2021.
>> Este artículo se publicó originalmente en nuestro sitio hermano, EE. Tiempos.
Contenidos relacionados:
- El procesador de visión AI permite video de 8K a 30 fps en menos de 2W
- Ambarella se enfoca en la detección de bordes inteligente con el nuevo SoC de cámara
- Los FPGA desplazan a los ASIC en el ADAS basado en la visión de Subaru Eyesight
- Arm agrega CPU, GPU e ISP para seguridad autónoma y visual
- La placa de visión de inteligencia artificial de baja potencia dura "años" con una sola batería
Para obtener más información sobre Embedded, suscríbase al boletín informativo semanal por correo electrónico de Embedded.
Incrustado
- Java captura múltiples excepciones
- Microchip:la solución basada en FPGA PolarFire permite imágenes y videos 4K con el factor de forma más pequeño
- Rutronik:módulos y SoC inalámbricos multiprotocolo de Redpine Signals
- Renesas:controlador de video LCD Full HD con entrada MIPI-CSI2
- El uso de varios chips de inferencia requiere una planificación cuidadosa
- Los SoC avanzados traen un cambio radical en los diseños médicos de IoT
- El procesador de video permite la codificación de video 4K para diseños que funcionan con baterías
- Abaco Systems:placa de video y gráficos XMC resistente
- Portwell:el sistema de 19 ”apunta a aplicaciones de videowall
- Un pequeño módulo integra varios biosensores
- Java 8 - Flujos