


Desarrolle nuevos hábitos de codificación para reducir errores en el software integrado
El tamaño y la complejidad de la aplicación se han incrementado significativamente durante la última década. Tomemos como ejemplo el sector de la automoción. Según The New York Times Hace 20 años, el automóvil promedio tenía un millón de líneas de código, pero 10 años después, el Chevrolet Volt 2010 de General Motors tenía alrededor de 10 millones de líneas de código, más que un avión de combate F-35. Hoy en día, un automóvil promedio tiene más de 100 millones de líneas de código.
El cambio a procesadores de 32 bits y superiores con mucha memoria y potencia ha permitido a las empresas incorporar muchas más funciones y capacidades de valor agregado en los diseños; eso es lo bueno. La desventaja es que la cantidad de código y su complejidad a menudo dan como resultado fallas que afectan la seguridad de las aplicaciones.
Ya es hora de un mejor enfoque. Se pueden encontrar dos tipos clave de errores en el software y solucionarlos utilizando herramientas que evitan que se introduzcan errores:
- Errores de codificación:un ejemplo es el código que intenta acceder fuera de los límites de una matriz. Este tipo de problemas se pueden detectar realizando un análisis estático.
- Errores de la aplicación:estos solo se pueden detectar si se sabe exactamente lo que se supone que debe hacer la aplicación, lo que significa probar los requisitos.
Aborde estos errores, y los ingenieros de diseño estarán muy lejos en el camino hacia un código más seguro.
Una pizca de prevención a través de la verificación de códigos
Los errores en el código ocurren con la misma facilidad que los errores en el correo electrónico y la mensajería instantánea. Estos son los errores simples que ocurren porque los ingenieros tienen prisa y no revisan. Pero con la complejidad viene una gama de errores de diseño que crean enormes desafíos. La complejidad genera la necesidad de un nivel completamente nuevo de comprensión de cómo funciona el sistema, cómo se transmiten los datos y cómo se definen los valores. Ya sea que los errores sean causados por la complejidad o por algún tipo de problema humano, pueden resultar en que un fragmento de código intente acceder a un valor fuera de los límites de una matriz. Y, un estándar de codificación lo detecta.
Es posible que también le interesen estos artículos relacionados de Embedded:
Cree sistemas integrados seguros y confiables con MISRA C / C ++
Uso de análisis estático para detectar errores de codificación en aplicaciones de servidor críticas para la seguridad de código abierto
¿Cómo evitar tales errores? No los pongas ahí en primer lugar. Si bien esto suena obvio, y casi imposible, este es exactamente el valor que aporta un estándar de codificación.
En el mundo C y C ++, el 80% de los defectos del software son causados por el uso incorrecto o imprudente de aproximadamente el 20% del lenguaje. El estándar de codificación crea restricciones en las partes del lenguaje que se sabe que son problemáticas. El resultado:se evitan los defectos y la calidad del software aumenta considerablemente. Echemos un vistazo a un par de ejemplos.
La mayoría de los errores de programación de C y C ++ son causados por comportamientos indefinidos, definidos por la implementación y no especificados que son inherentes a cada lenguaje, lo que conduce a errores de software y problemas de seguridad. Este comportamiento definido por la implementación propaga un bit de orden superior cuando un entero con signo se desplaza a la derecha. Dependiendo del compilador que utilicen los ingenieros, el resultado podría ser 0x40000000 o 0xC0000000 ya que C no especifica el orden en el que se evalúan los argumentos de una función.
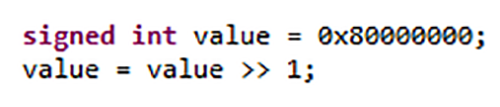
Figura 1. El comportamiento de algunas construcciones de C y C ++ depende del compilador utilizado. Fuente:LDRA
En la Figura 2, donde rollDice () La función simplemente lee el siguiente valor de un búfer circular que contiene los valores “1, 2, 3 y 4”; el valor devuelto esperado sería 1234. Pero no hay garantía de eso. Al menos un compilador genera código que devuelve el valor 3412.

Figura 2. Los lenguajes no especifican el comportamiento de algunas construcciones de C y C ++. Fuente:LDRA
Hay muchas otras trampas en el lenguaje C / C ++:uso de construcciones como goto o malloc ; mezclas de valores firmados y no firmados; o código "inteligente" que puede ser muy eficiente y compacto, pero es tan críptico y complejo que a otros les cuesta entenderlo. Cualquiera de estos problemas puede provocar defectos, desbordamientos de valor que de repente se vuelven negativos o simplemente hacer que el código sea imposible de mantener.
Los estándares de codificación brindan la onza de prevención para estos males. Pueden evitar el uso de estas construcciones problemáticas y evitar que los desarrolladores creen código indocumentado y demasiado complejo, así como verificar la coherencia del estilo. Incluso se pueden monitorear cosas como verificar que el carácter de tabulación no se use o que los paréntesis estén colocados en una posición específica. Si bien esto parece trivial, seguir el estilo ayuda enormemente a la revisión manual del código y evita confusiones causadas por un tamaño de pestaña diferente cuando el código se ve en otro editor, todas distracciones que impiden que un revisor se concentre en el código.
MISRA al rescate
Los estándares de programación más conocidos son las pautas MISRA, publicadas por primera vez en 1998 para la industria automotriz y ahora comúnmente aceptadas por muchos compiladores integrados que ofrecen algún nivel de verificación MISRA. MISRA se enfoca en las construcciones y prácticas problemáticas dentro de los lenguajes C y C ++, recomendando el uso de características estilísticas consistentes sin sugerir ninguna.
Las pautas de MISRA brindan explicaciones útiles sobre por qué existe cada regla, junto con detalles de las diversas excepciones a esa regla y ejemplos del comportamiento indefinido, no especificado y definido por la implementación. La Figura 3 ilustra el nivel de orientación.

Figura 3. Estas referencias de MISRA C pertenecen al comportamiento indefinido, no especificado y definido por la implementación. Fuente:LDRA
La mayoría de las pautas de MISRA son “Decidables”, lo que significa que la herramienta puede identificar si hay una violación; pero algunos son "indecidibles", lo que implica que no siempre es posible que la herramienta deduzca si existe una infracción.
Una variable no inicializada pasada a una función del sistema que debería inicializarla podría no registrarse como un error si la herramienta de análisis estático no tiene acceso al código fuente de la función del sistema. Existe la posibilidad de un falso negativo o un falso positivo.
En 2016, se agregaron 14 pautas a MISRA para proporcionar verificación del código crítico para la seguridad, no solo de la seguridad. La Figura 4 ilustra cómo una de las nuevas pautas, la Directiva 4.14, resuelve este problema y ayuda a prevenir las trampas debidas a un comportamiento indefinido.

Figura 4. La Directiva 4.14 de MISRA ayuda a prevenir las trampas causadas por el comportamiento indefinido. Fuente:LDRA
Los rigores de los estándares de codificación se asociaron tradicionalmente con software funcionalmente seguro para aplicaciones críticas como automóviles, aviones y dispositivos médicos. Sin embargo, la complejidad del código, la importancia crítica de la seguridad y la importancia comercial de crear un código sólido y de alta calidad que sea fácil de mantener y actualizar hacen que los estándares de codificación sean cruciales en todas las operaciones de desarrollo.
Al asegurarse de que no se introduzcan errores en el código en primer lugar, los equipos de desarrollo deben:
- reducir la necesidad de una depuración extensa,
- obtener un mejor control del horario, y
- controle el ROI al reducir los costos generales.
La verificación de código ofrece una caja de herramientas con enormes beneficios potenciales.
Una libra de cura con herramientas de prueba
Si bien la verificación de código resuelve muchos problemas, los errores de la aplicación solo se pueden encontrar probando que el producto haga lo que se supone que debe hacer, y eso significa tener requisitos. Evitar errores de aplicación requiere tanto diseñar el producto correcto como diseñar el producto correctamente.
Diseñar el producto correcto significa establecer requisitos por adelantado y garantizar la trazabilidad bidireccional entre los requisitos y el código fuente, de modo que se implementen todos los requisitos y cada función del software se remonta a un requisito. Cualquier funcionalidad que falte o sea innecesaria, que no cumpla con un requisito, es un error de la aplicación. Diseñar el producto correctamente es el proceso de confirmar que el código del sistema desarrollado cumple con los requisitos del proyecto. Lo logra al realizar pruebas basadas en requisitos.
La figura 5 muestra un ejemplo de trazabilidad bidireccional. La función única seleccionada rastrea en sentido ascendente desde la función a un requisito de bajo nivel, luego a un requisito de alto nivel y finalmente a un requisito a nivel del sistema.
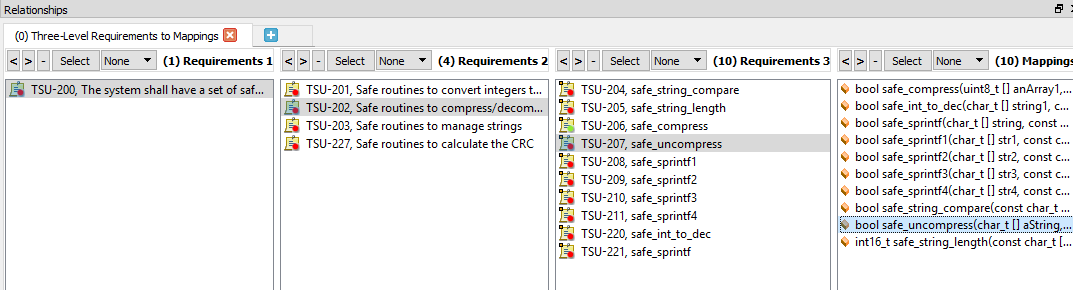
Figura 5. Este es un ejemplo de trazabilidad bidireccional con una única función seleccionada. Fuente:LDRA
La Figura 6 muestra cómo la selección de un requisito de alto nivel muestra tanto la trazabilidad ascendente a un requisito a nivel del sistema como la descendencia a los requisitos de bajo nivel y las funciones del código fuente.
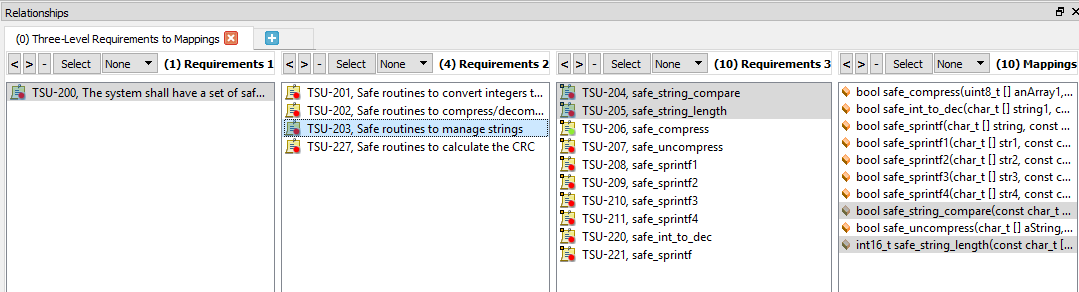
Figura 6. Este es un ejemplo de trazabilidad bidireccional con requisitos seleccionados. Fuente:LDRA
Esta capacidad de visualizar la trazabilidad puede conducir a la detección de errores de aplicaciones en las primeras etapas del ciclo de vida.
Probar la funcionalidad del código exige ser consciente de lo que se supone que debe hacer, y eso significa tener requisitos de bajo nivel que indiquen lo que hace cada función. La Figura 7 muestra un ejemplo de un requisito de bajo nivel que, en este caso, describe completamente una sola función.
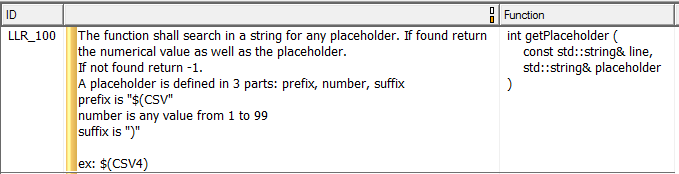
Figura 7. Este es un ejemplo de un requisito de bajo nivel que describe una sola función. Fuente:LDRA
Los casos de prueba se derivan de requisitos de bajo nivel como se ilustra en la Figura 8.
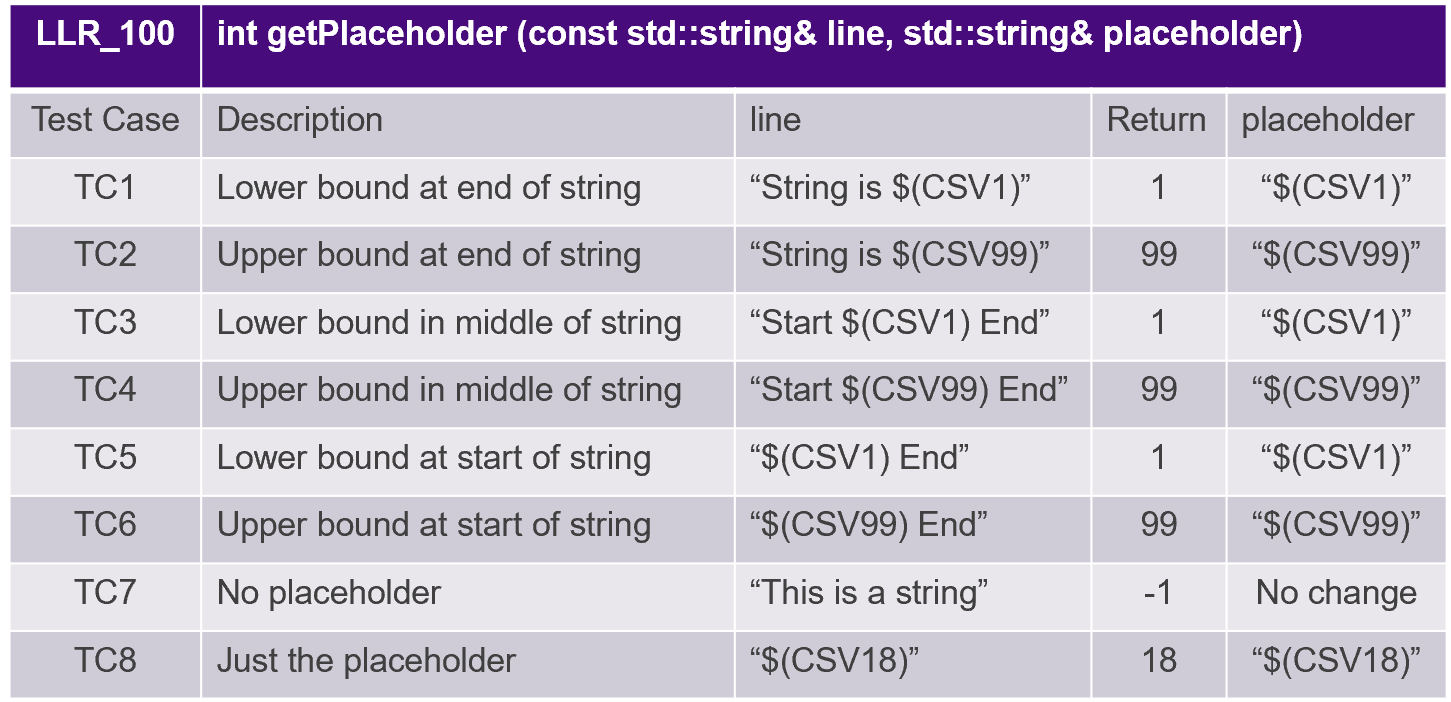
Figura 8. Los casos de prueba se derivan de requisitos de bajo nivel. Fuente:LDRA
Usando una herramienta de prueba unitaria, estos casos de prueba se pueden ejecutar en el host o en el destino para garantizar que el código se comporte de la forma en que el requisito dice que debería. La Figura 9 muestra que todos los casos de prueba se retrocedieron y aprobaron.
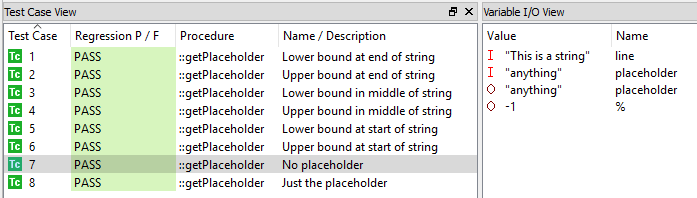
Figura 9. Así es como una herramienta realiza pruebas unitarias. Fuente:LDRA
Una vez que se han ejecutado los casos de prueba, se debe medir la cobertura estructural para garantizar que se haya aplicado todo el código. Si la cobertura no es del 100 por ciento, es posible que se requieran más casos de prueba o se deba eliminar el código superfluo.
Nuevos hábitos en la codificación
Sin lugar a dudas, la complejidad del software y sus errores se han multiplicado con la conectividad, la memoria más rápida, las plataformas de hardware enriquecidas y las demandas específicas de los clientes. La adopción de un estándar de codificación de vanguardia, la medición de métricas en el código, el seguimiento de requisitos y la implementación de pruebas basadas en requisitos brindan a los equipos de desarrollo la oportunidad de crear código de alta calidad y reducir la responsabilidad.
La medida en que un equipo adopte estos nuevos hábitos cuando ningún estándar requiere cumplimiento depende del reconocimiento corporativo del cambio de juego que traen consigo. La adopción de estas prácticas, ya sea que un producto sea crítico para la seguridad o la seguridad, puede marcar una diferencia día y noche en la capacidad de mantenimiento y la solidez del código. El código limpio simplifica la adición de nuevas funciones, facilita el mantenimiento del producto y mantiene los costos y la programación al mínimo, todas características que mejoran el ROI de su empresa.
Ya sea que un producto sea crítico para la seguridad o no, este es seguramente un resultado que solo puede ser beneficioso para el equipo de desarrollo.
>> Este artículo se publicó originalmente el nuestro sitio hermano, EDN.
Incrustado
- ¿Son las cadenas de texto una vulnerabilidad en el software integrado?
- La arquitectura SOAFEE para edge embebido permite automóviles definidos por software
- Pixus:nuevas placas frontales gruesas y resistentes para placas integradas
- Kontron:nuevo estándar informático integrado COM HPC
- congatec presenta 10 nuevos módulos de gama alta para computación de borde embebido
- GE Digital lanza un nuevo software de gestión de activos
- Cómo no apestar al enseñar software nuevo
- Riesgos de software:protección de código abierto en IoT
- Tres pasos para asegurar las cadenas de suministro de software
- Saelig lanza una nueva PC integrada fabricada por Amplicon
- Uso de DevOps para abordar los desafíos del software integrado